Application Process
To use OpenAI Embeddings API, first open the Ace Data Cloud Console and copy your API Token.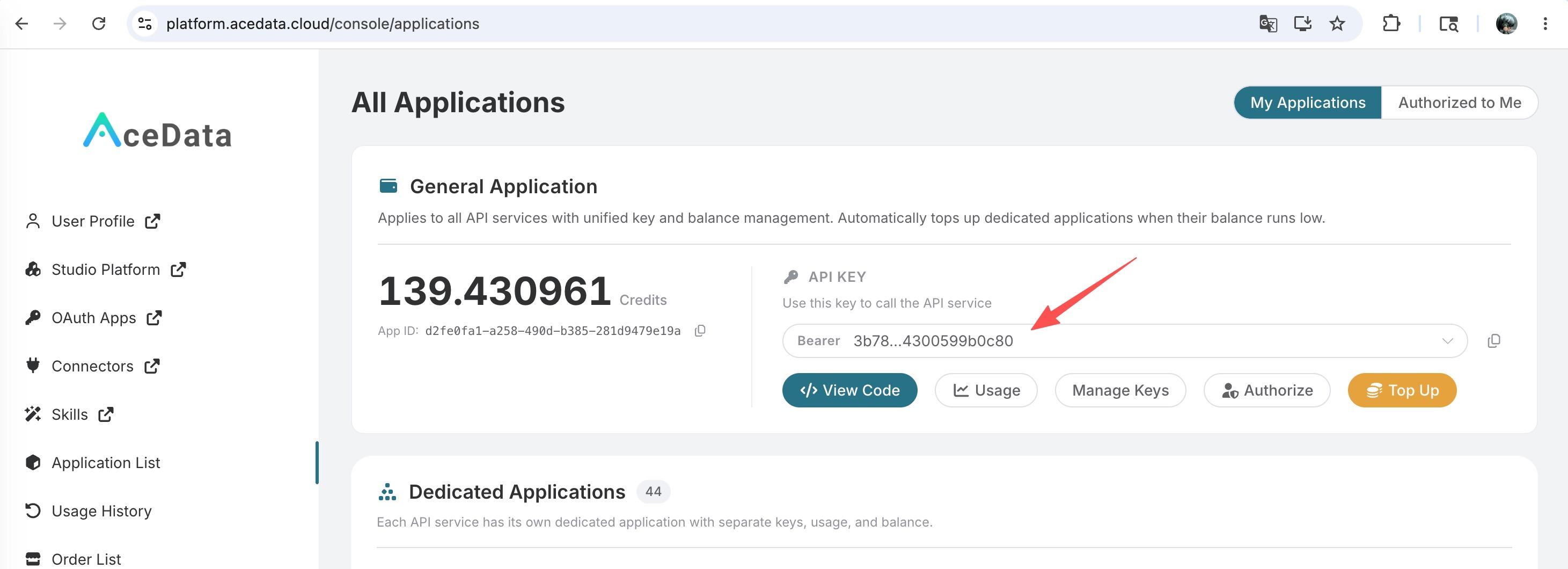 If you are not logged in, you will be redirected to sign in and brought back to this page automatically.
A single API Token works across every service on the platform — no need to subscribe per service. New accounts receive free starter credit; when it runs low you can top up your shared balance in the console.
If you are not logged in, you will be redirected to sign in and brought back to this page automatically.
A single API Token works across every service on the platform — no need to subscribe per service. New accounts receive free starter credit; when it runs low you can top up your shared balance in the console.
📘 Full documentation: OpenAI Embeddings API →
Basic Usage
Next, you can fill in the corresponding content on the interface, as shown in the figure: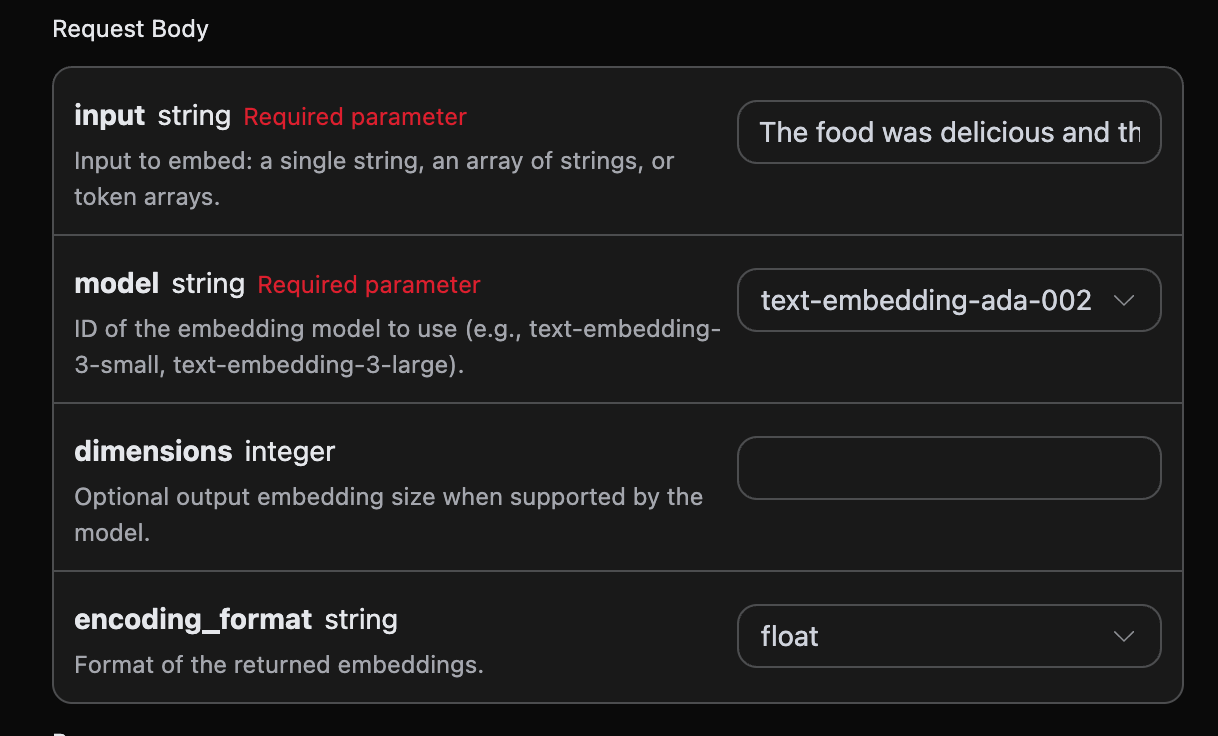
authorization, which can be selected directly from the dropdown list. The other parameter is model, which is the model category we choose to use from the OpenAI official website. Here we mainly have 3 types of models; details can be found in the models we provide. The last parameter is input, which is the text we need to convert into a word vector.
You can also notice that there is corresponding code generation on the right side; you can copy the code to run directly or click the “Try” button for testing.
Optional parameters:
dimensions: Crop vector dimensions; the default output is the full dimension.encoding_format: Return format, optionalfloatorbase64.
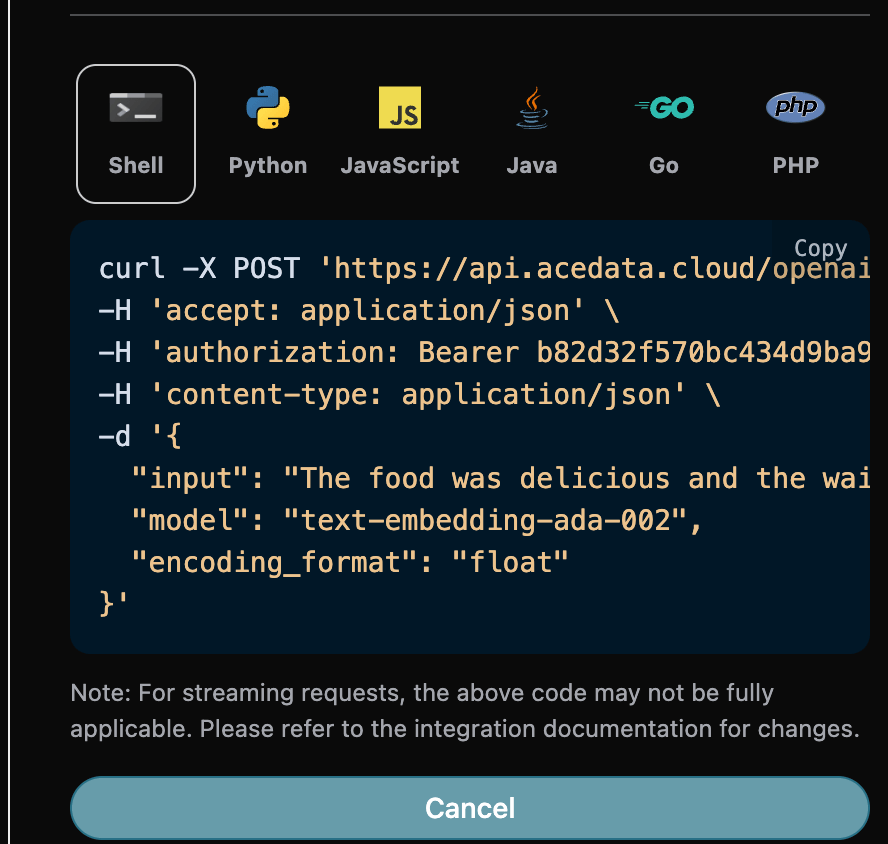
model, the model used for converting the text to word vectors.usage, the token information used for converting the text to word vectors.data, the word vector results after the text conversion.
data contains the specific information of the word vectors corresponding to the text, and the embedding inside it is the specific result of the generated word vector.
Error Handling
When calling the API, if an error occurs, the API will return the corresponding error code and message. For example:400 token_mismatched: Bad request, possibly due to missing or invalid parameters.400 api_not_implemented: Bad request, possibly due to missing or invalid parameters.401 invalid_token: Unauthorized, invalid or missing authorization token.429 too_many_requests: Too many requests, you have exceeded the rate limit.500 api_error: Internal server error, something went wrong on the server.