Application Process
To use OpenAI Chat Completion API, first open the Ace Data Cloud Console and copy your API Token.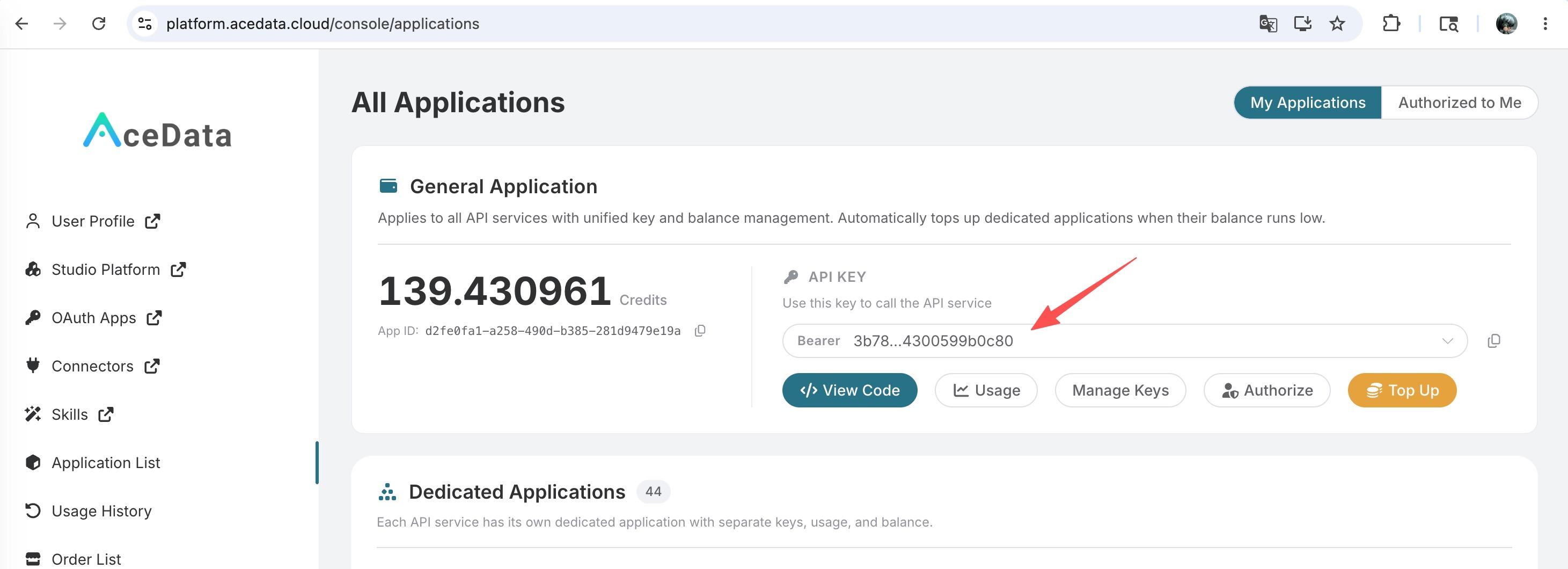 If you are not logged in, you will be redirected to sign in and brought back to this page automatically.
A single API Token works across every service on the platform — no need to subscribe per service. New accounts receive free starter credit; when it runs low you can top up your shared balance in the console.
If you are not logged in, you will be redirected to sign in and brought back to this page automatically.
A single API Token works across every service on the platform — no need to subscribe per service. New accounts receive free starter credit; when it runs low you can top up your shared balance in the console.
📘 Full documentation: OpenAI Chat Completion API →
Basic Usage
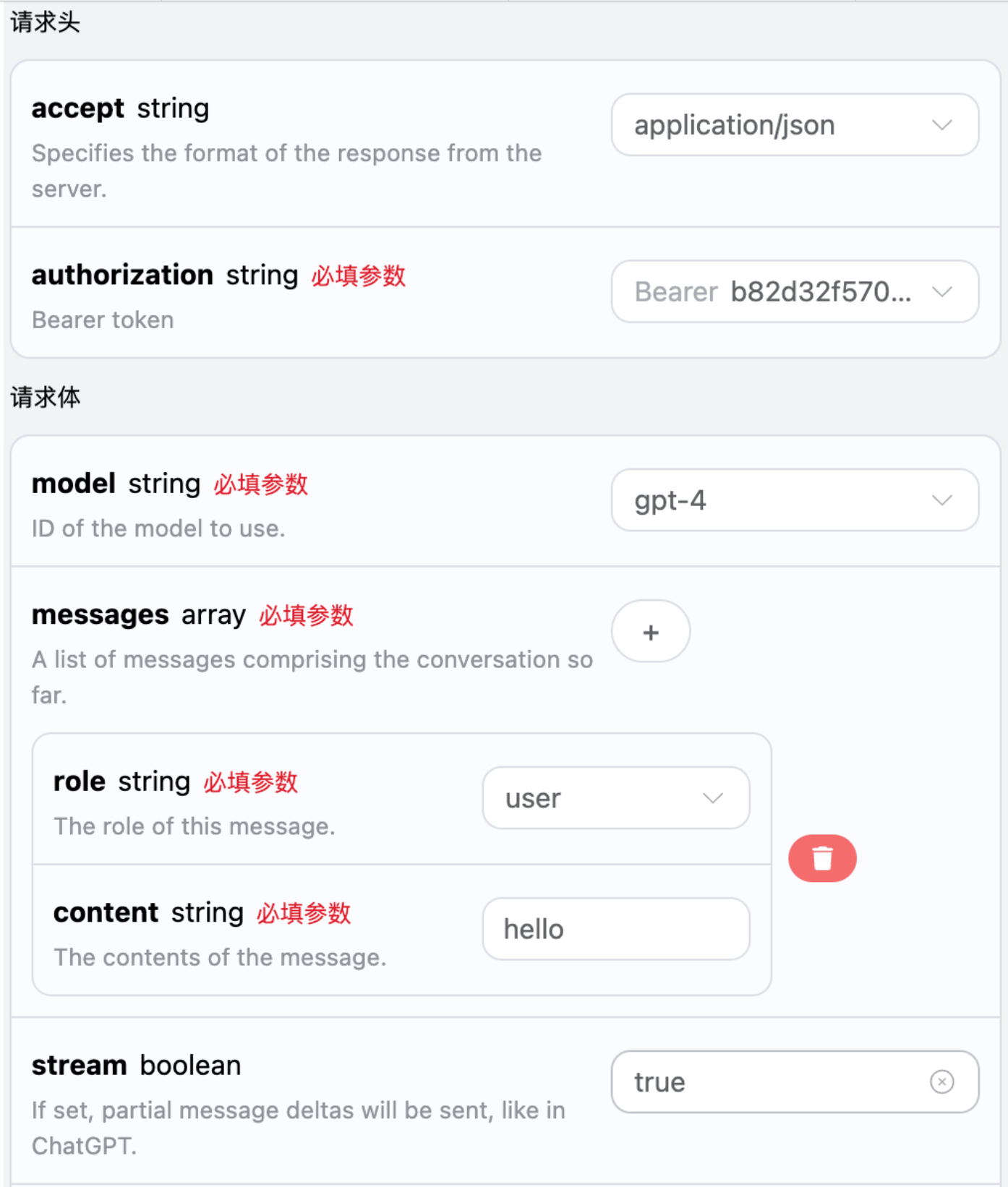
Next, you can fill in the corresponding content on the interface, as shown in the figure: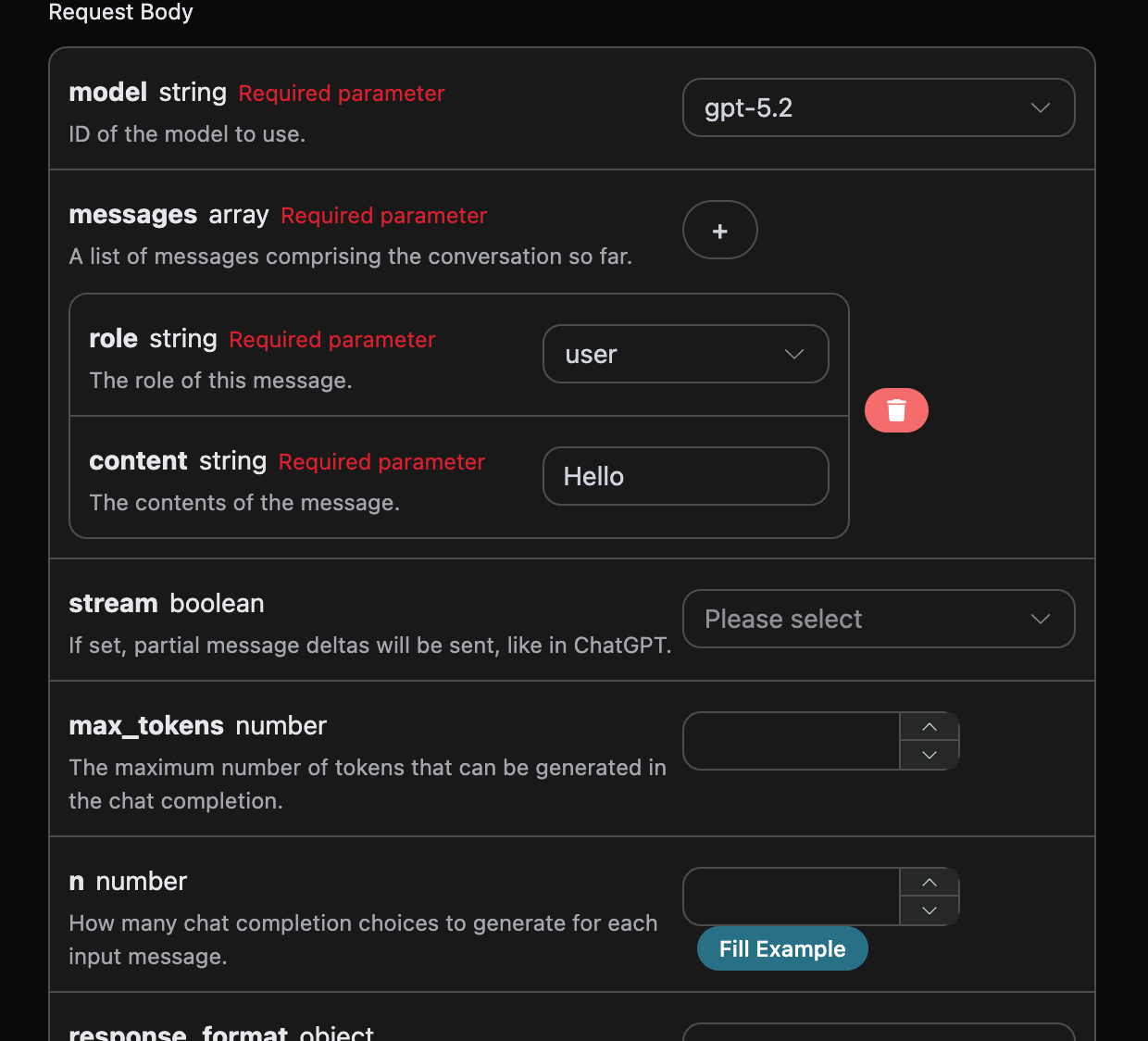
authorization, which can be selected directly from the dropdown list. The other parameter is model, which is the category of the OpenAI ChatGPT model we choose to use. Here we mainly have 20 types of models; details can be found in the models we provide. The last parameter is messages, which is an array of our input questions. It is an array that allows multiple questions to be uploaded simultaneously, with each question containing role and content. The role indicates the role of the questioner, and we provide three identities: user, assistant, and system. The other content is the specific content of our question.
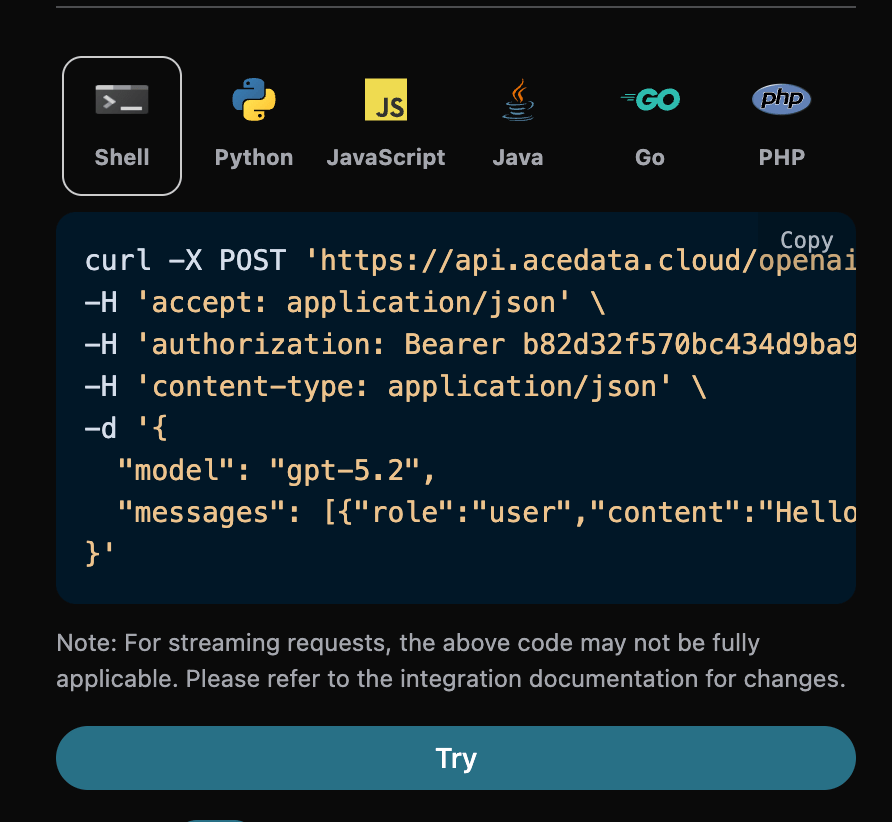
You can also notice that there is corresponding code generation on the right side; you can copy the code to run directly or click the “Try” button for testing.
Common optional parameters:
max_tokens: Limits the maximum number of tokens for a single response.temperature: Generates randomness, between 0-2, with larger values being more divergent.n: How many candidate responses to generate at once.response_format: Sets the return format.
id: The ID generated for this dialogue task, used to uniquely identify this dialogue task.model: The selected OpenAI ChatGPT model.choices: The response information provided by ChatGPT for the question.usage: Statistical information regarding tokens for this Q&A.
choices contains the response information from ChatGPT, and within it, the choices is ChatGPT’s response, as shown in the figure.
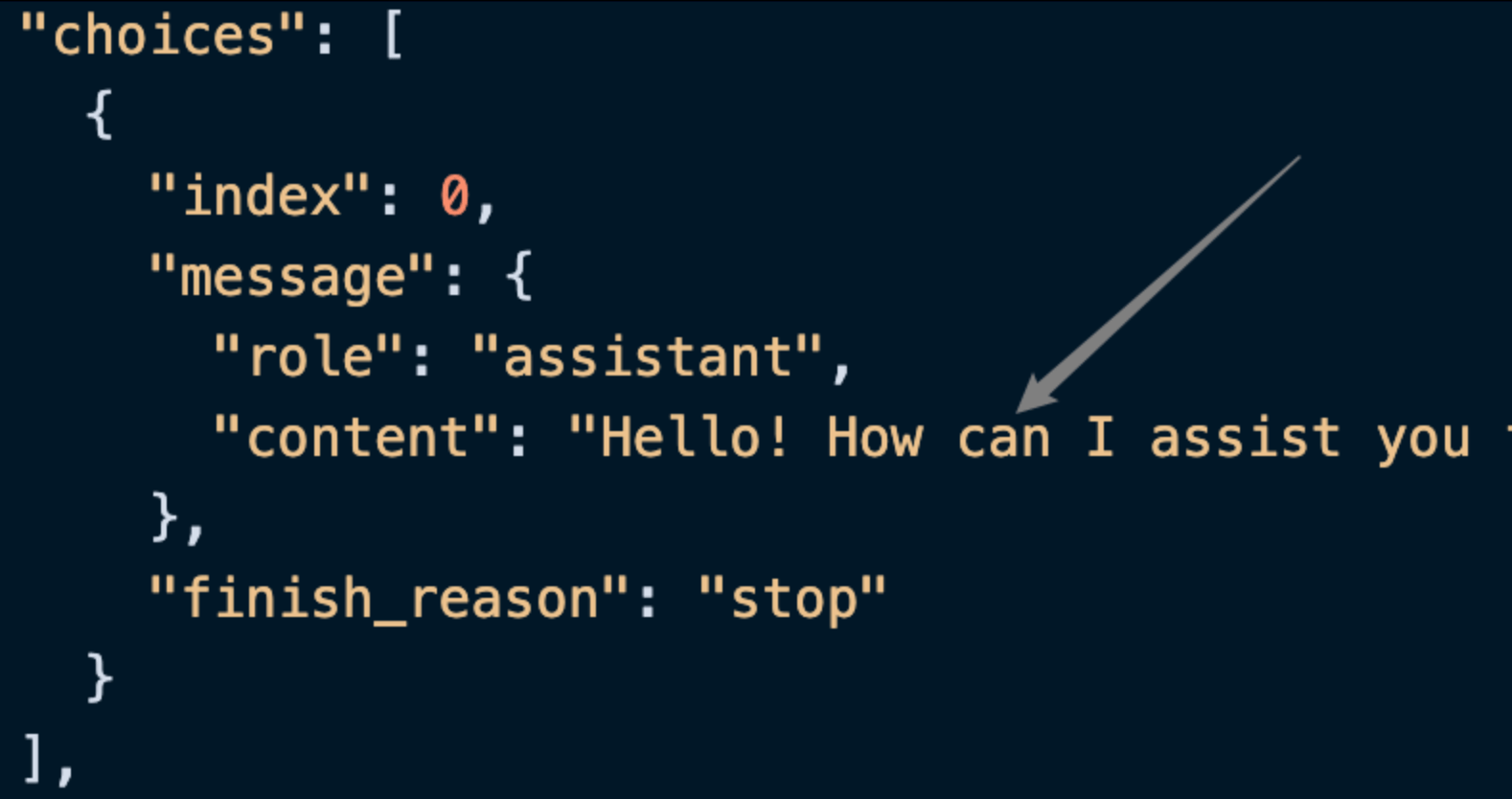
content field in choices contains the specific content of ChatGPT’s reply.
Streaming Response
This interface also supports streaming responses, which is very useful for web integration, allowing the webpage to achieve a word-by-word display effect. If you want to return responses in a streaming manner, you can change thestream parameter in the request header to true.
Modify as shown in the figure, but the calling code needs to have corresponding changes to support streaming responses.
stream to true, the API will return the corresponding JSON data line by line, and we need to make corresponding modifications at the code level to obtain the line-by-line results.
Python sample calling code:
data in the response, and the choices in data is the latest response content, consistent with the content introduced above. The choices is the newly added response content, which you can use to connect to your system. At the same time, the end of the streaming response is determined by the content of data. If the content is [DONE], it indicates that the streaming response has completely ended. The returned data result has multiple fields, which are described as follows:
id, the ID generated for this dialogue task, used to uniquely identify this dialogue task.model, the OpenAI ChatGPT model selected.choices, the response information provided by ChatGPT to the prompt.
Multi-turn Dialogue
If you want to integrate multi-turn dialogue functionality, you need to upload multiple prompts in themessages field. The specific examples of multiple prompts are shown in the image below:
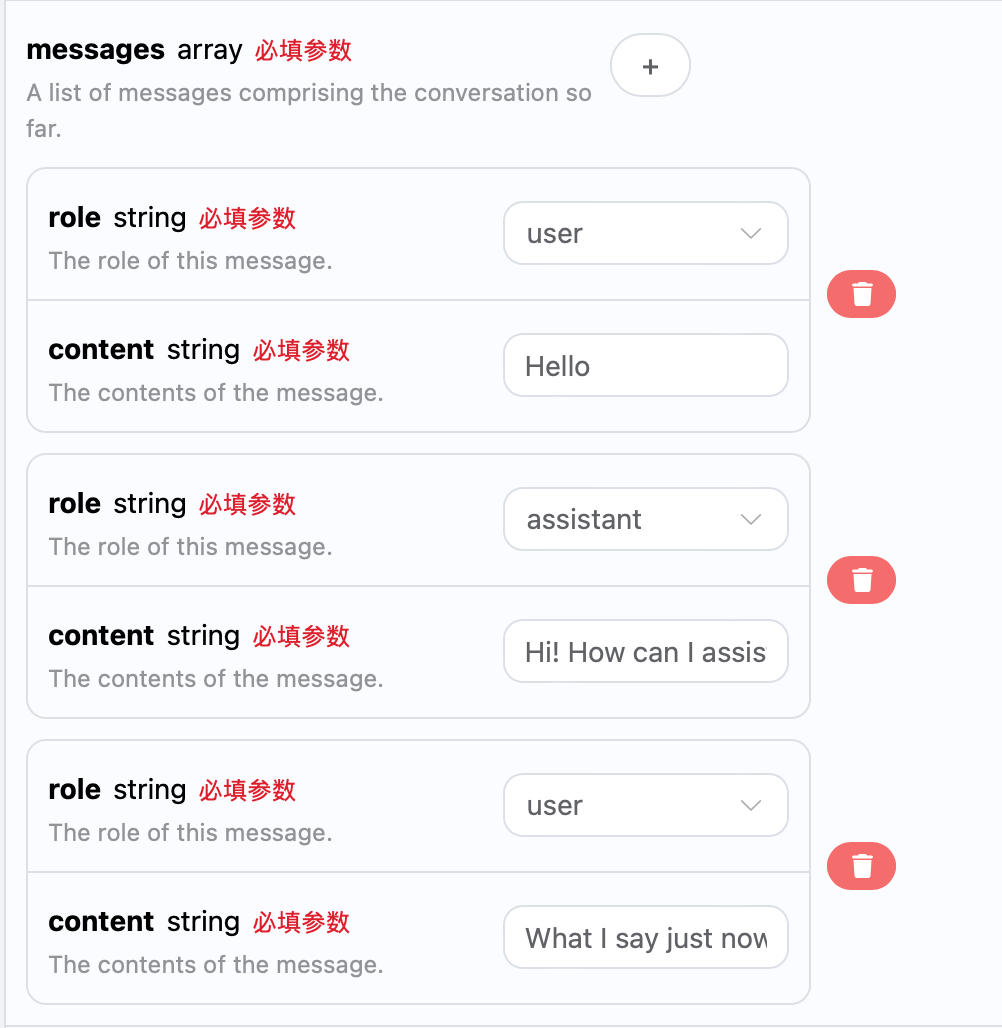
choices is consistent with the basic usage content, which includes the specific content of ChatGPT’s responses to multiple dialogues, allowing for answers to corresponding questions based on multiple dialogue contents.
Integrating OpenAI-Python
The upstream of the OpenAI Chat Completion API service is the official OpenAI service, which can be viewed in the official OpenAI-Python. This article will briefly introduce how to use the services provided by the official.- First, set up a local
Pythonenvironment, this process can be searched on Google. - Download and install the development environment, such as installing the VSCode editor.
- Configure the
OpenAIenvironment variables.
- In the project folder, create a file named
.envand save it. - The content of the
.envfile:
sk-xxx with your own key. OPENAI_BASE_URL is the proxy interface for accessing OpenAI.
- Install the project dependencies
- Create an example source code file
index.py, the specific content is as follows:
Online Model
The gpt-3.5-browsing and gpt-4-browsing models are different from other models; they can perform online searches based on the question words and return the results of the online search with appropriate adjustments. This article will demonstrate the online functionality through a specific example, and you can fill in the corresponding content on the OpenAI Chat Completion API interface, as shown in the figure: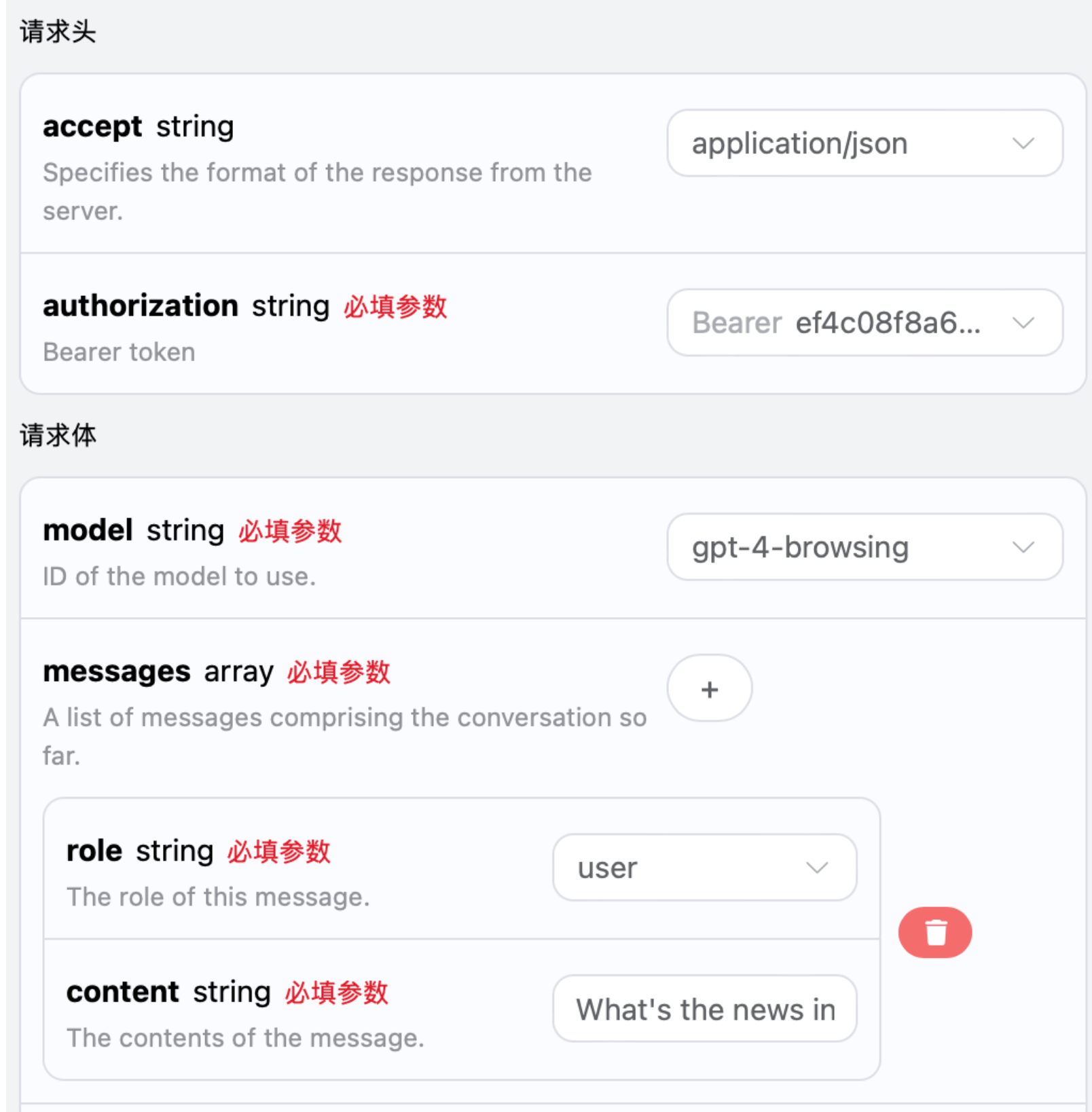
choices is obtained based on online queries and also provides relevant links. The response information in choices needs to be rendered using markdown syntax to achieve the best experience, which ultimately reflects the powerful advantages of our model’s online functionality.
Visual Model
gpt-4o is a multimodal large language model developed by OpenAI, which adds visual understanding capabilities on the basis of GPT-4. This model can process both text and image inputs simultaneously, achieving cross-modal understanding and generation. The text processing using the gpt-4o model is consistent with the basic usage content mentioned above. Below, we will briefly introduce how to use the model’s image processing capabilities. The image processing capability of the gpt-4o model is mainly achieved by adding atype field to the original content, which indicates whether the uploaded content is text or an image, thus utilizing the image processing capabilities of the gpt-4o model. The following mainly discusses how to call this function using both Curl and Python.
- Curl script method
- Python script method
GPT-4o Drawing Model
Request example:Error Handling
When calling the API, if an error occurs, the API will return the corresponding error code and message. For example:400 token_mismatched:错误请求,可能是由于缺少或无效的参数。400 api_not_implemented:错误请求,可能是由于缺少或无效的参数。401 invalid_token:未授权,授权令牌无效或缺失。429 too_many_requests:请求过多,您已超出速率限制。500 api_error:内部服务器错误,服务器出现问题。