Proceso de solicitud
Para utilizar la API de Embeddings de OpenAI, primero puede ir a la página de API de Embeddings de OpenAI y hacer clic en el botón “Acquire” para obtener las credenciales necesarias para la solicitud: Si aún no ha iniciado sesión o registrado, será redirigido automáticamente a la página de inicio de sesión que le invita a registrarse e iniciar sesión. Después de registrarse e iniciar sesión, volverá automáticamente a la página actual.
En la primera solicitud, se le otorgará un crédito gratuito que le permitirá utilizar esta API de forma gratuita.
Si aún no ha iniciado sesión o registrado, será redirigido automáticamente a la página de inicio de sesión que le invita a registrarse e iniciar sesión. Después de registrarse e iniciar sesión, volverá automáticamente a la página actual.
En la primera solicitud, se le otorgará un crédito gratuito que le permitirá utilizar esta API de forma gratuita.
Uso básico
A continuación, puede completar el contenido correspondiente en la interfaz, como se muestra en la imagen: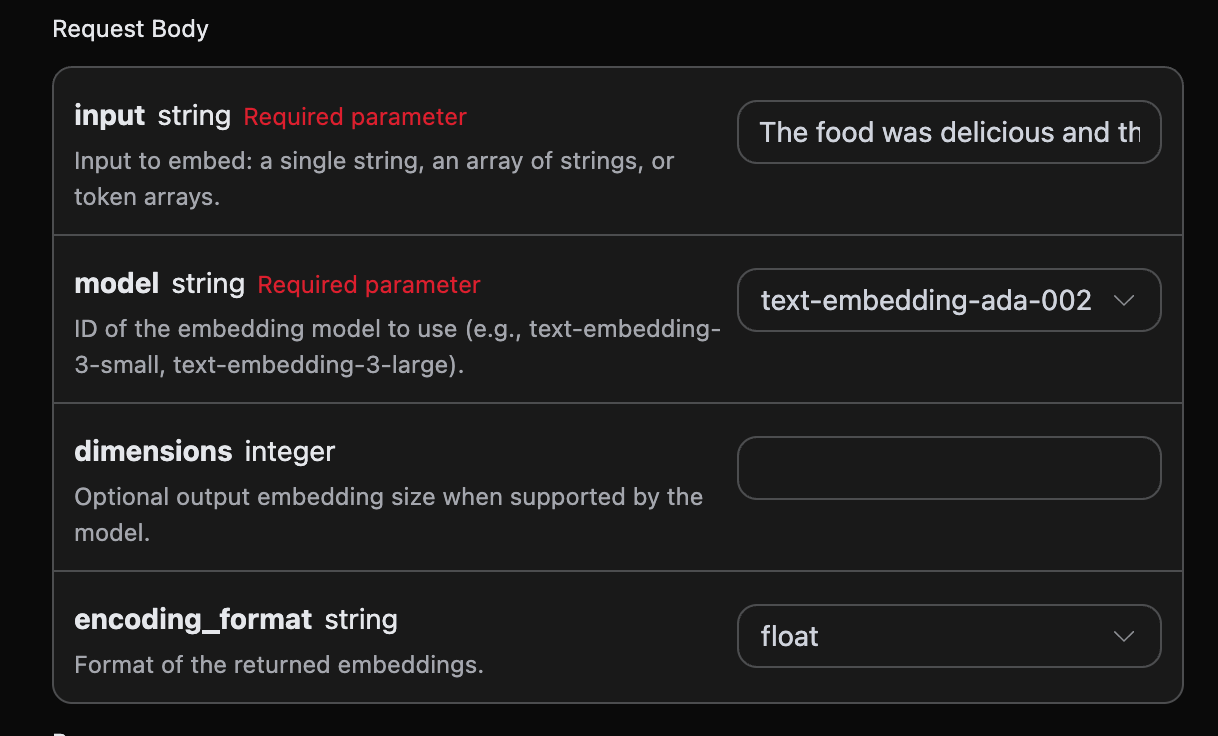
authorization, que se puede seleccionar directamente en la lista desplegable. El otro parámetro es model, que es la categoría del modelo que elegimos utilizar del sitio web de OpenAI; aquí tenemos principalmente 3 tipos de modelos, los detalles se pueden ver en los modelos que proporcionamos. El último parámetro es input, que es el texto de vector de palabras que necesitamos convertir.
Al mismo tiempo, puede notar que a la derecha hay un código de llamada correspondiente generado, puede copiar el código y ejecutarlo directamente, o puede hacer clic en el botón “Try” para realizar pruebas.
Parámetros opcionales:
dimensions: recortar la dimensión del vector, la salida predeterminada es la dimensión completa.encoding_format: formato de retorno, puede serfloatobase64.
model, el modelo utilizado para convertir el texto en un vector de palabras.usage, la información de tokens utilizada para convertir el texto en un vector de palabras.data, el resultado del vector de palabras después de la conversión del texto.
data se incluye la información específica del vector de palabras correspondiente al texto, donde embedding es el resultado específico del vector de palabras generado.
Manejo de errores
Al llamar a la API, si se encuentra con un error, la API devolverá el código de error y la información correspondiente. Por ejemplo:400 token_mismatched: Solicitud incorrecta, posiblemente debido a parámetros faltantes o inválidos.400 api_not_implemented: Solicitud incorrecta, posiblemente debido a parámetros faltantes o inválidos.401 invalid_token: No autorizado, token de autorización inválido o faltante.429 too_many_requests: Demasiadas solicitudes, ha superado el límite de tasa.500 api_error: Error interno del servidor, algo salió mal en el servidor.