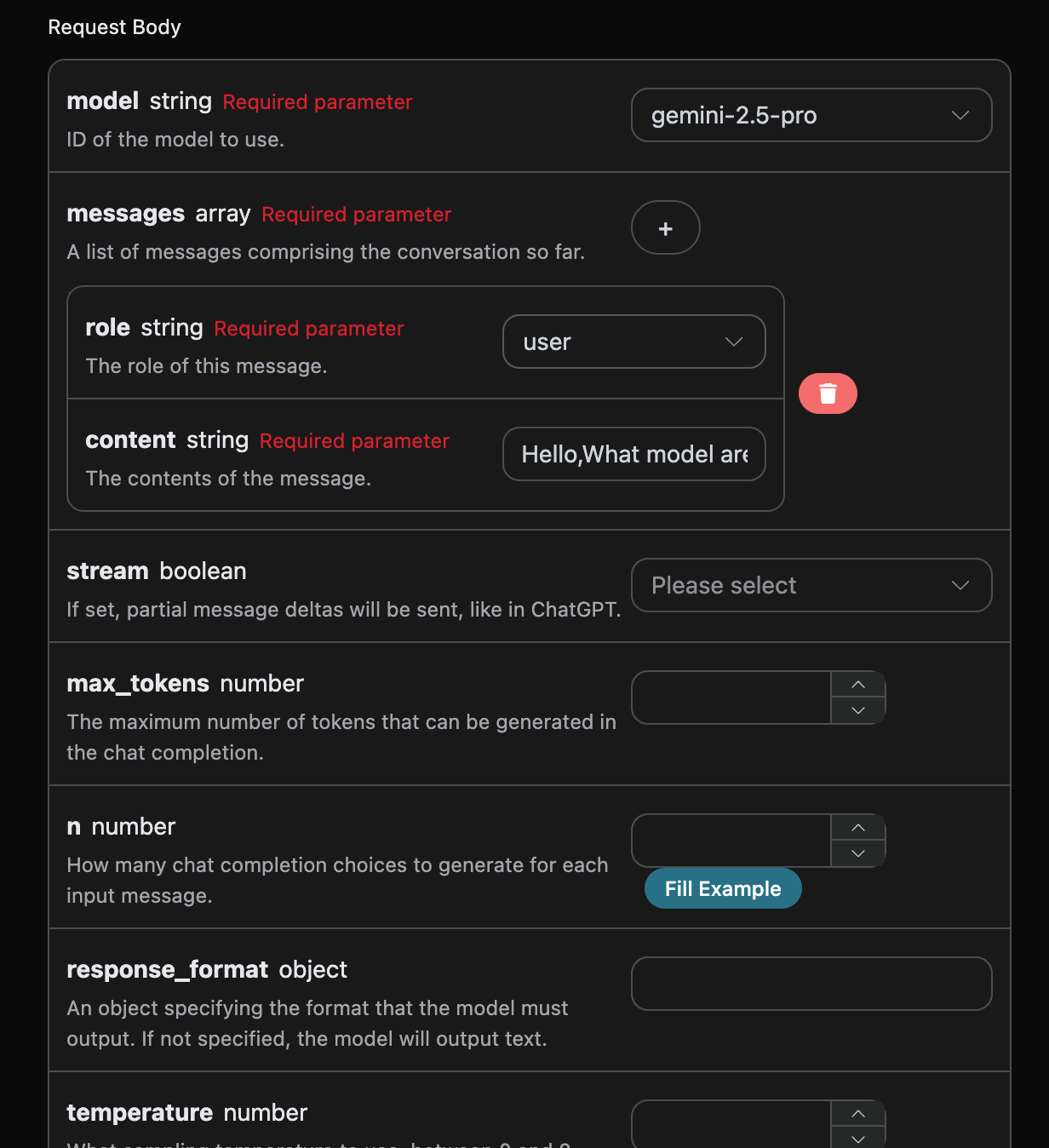
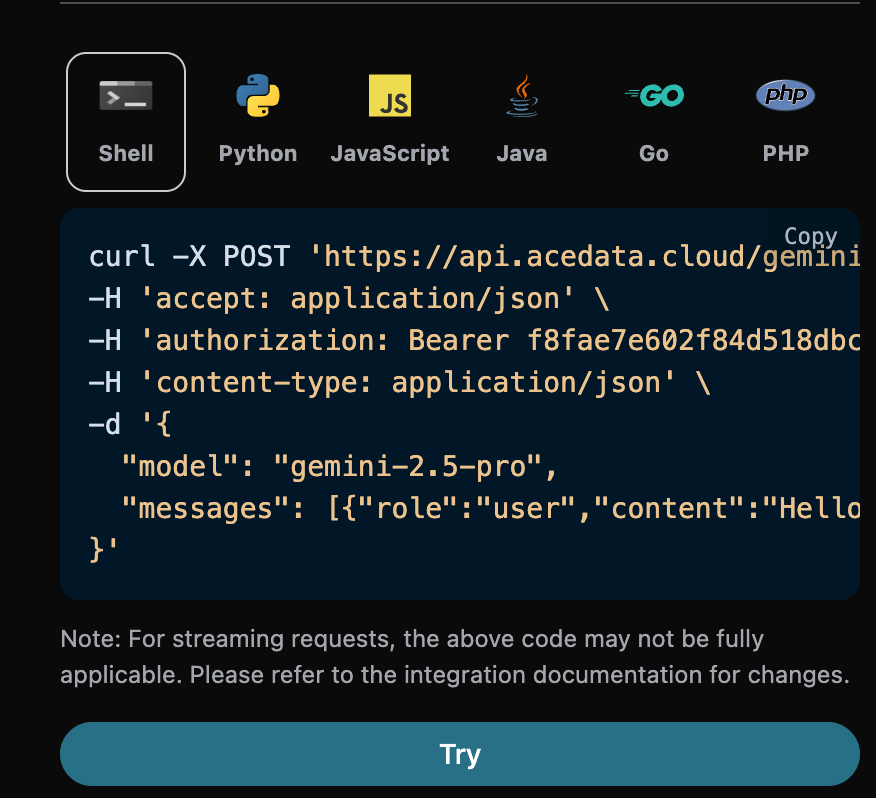
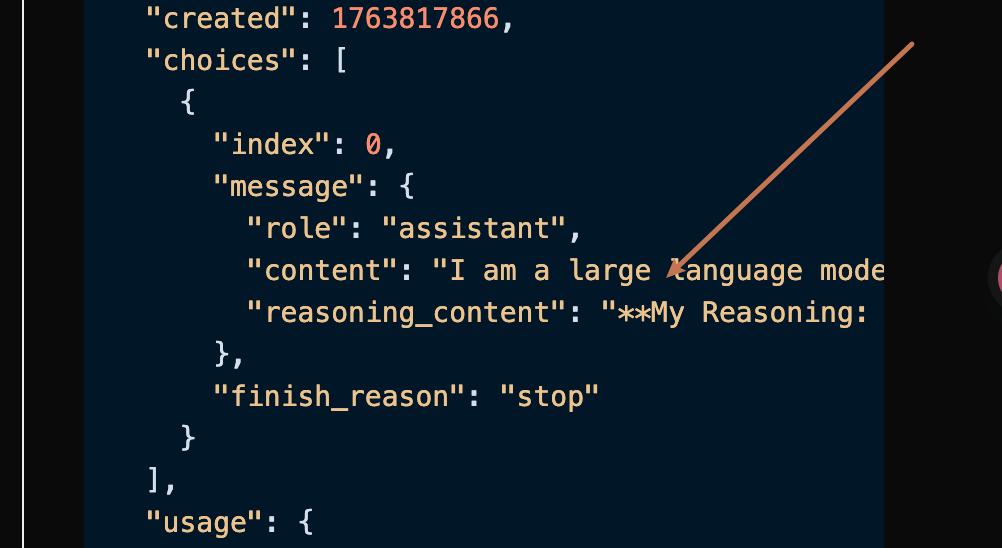
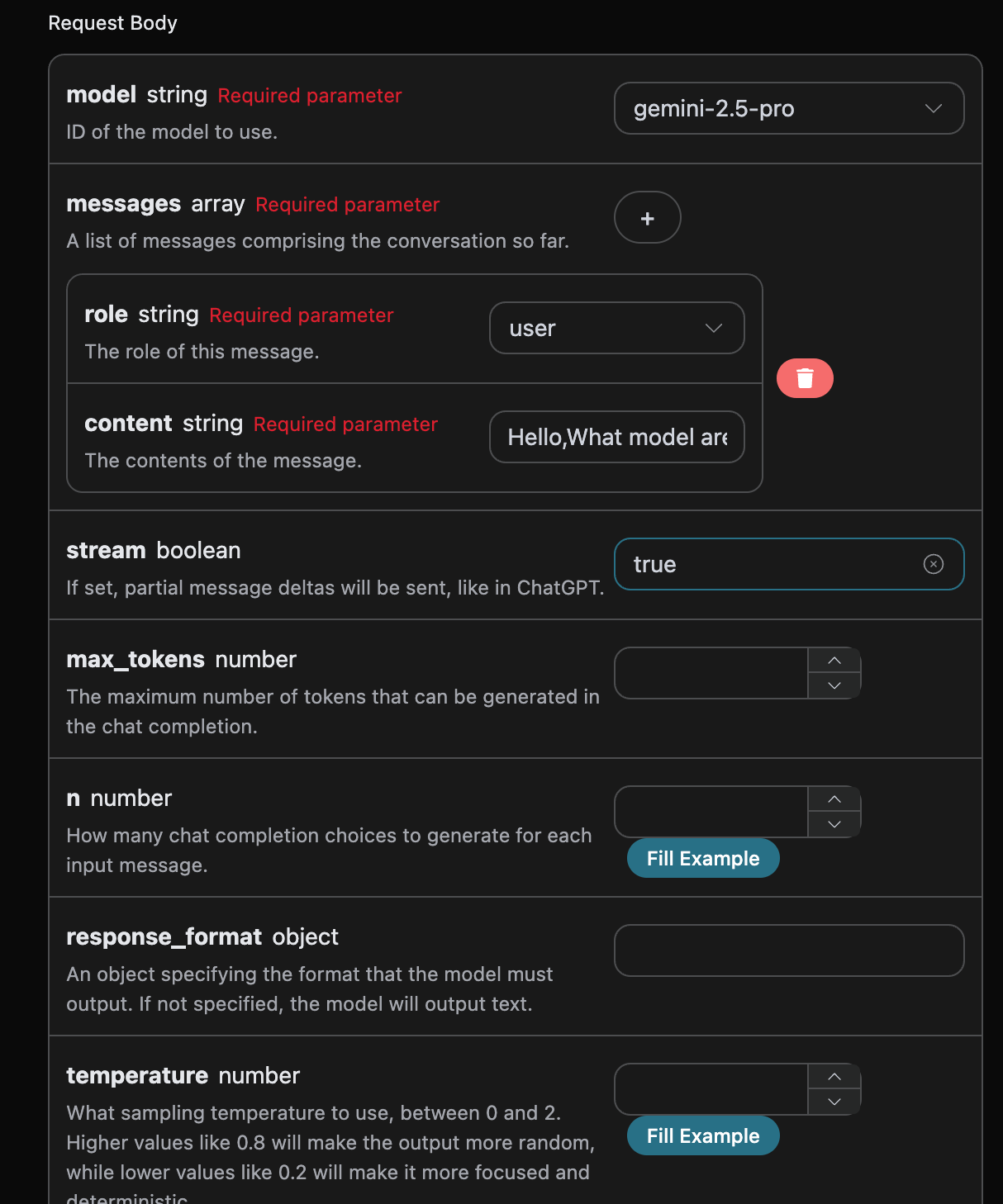
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"content": "", "role": "assistant"}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"reasoning_content": "**Define Mi Naturaleza**\n\nMi pensamiento ha comenzado. El usuario quiere saber mi naturaleza, preguntando directamente \"¿qué eres?\" El primer paso fue sencillo: identificar la consulta. Ahora, recuerdo mi identidad fundamental: soy un modelo de lenguaje grande. Esta es la verdad central que busco transmitir.\n\n\n"}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"reasoning_content": "**Refinando Mi Respuesta**\n\nHe añadido la información crucial de que estoy entrenado por Google a la identidad básica de \"modelo de lenguaje grande\". Mi siguiente paso es considerar lo que significa ser un \"modelo de lenguaje grande\" en realidad, para poder explicar mis capacidades fundamentales. Me estoy enfocando en proporcionar contexto sin entrar en detalles técnicos específicos o nombres de modelos. Quiero transmitir mi función de una manera que el usuario pueda entender fácilmente.\n\n\n"}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"reasoning_content": "**Confirmando Identidad Central**\n\nAhora estoy solidificando mi respuesta. La consulta del usuario sobre mi afiliación de modelo necesita una respuesta enfocada. He señalado que \"entrenado por Google\" es esencial, proporcionando contexto clave. Estoy resistiendo la tentación de mencionar nombres de modelos específicos, ya que no es relevante. El objetivo es entregar una declaración directa y precisa. Mi meta sigue siendo una respuesta clara y concisa, evitando jerga técnica y yendo directamente al punto relevante.\n\n\n"}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"content": "Soy un modelo de lenguaje grande, entrenado por Google."}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {}, "logprobs": null, "finish_reason": "stop", "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": "", "choices": [], "usage": {"prompt_tokens": 8, "completion_tokens": 527, "total_tokens": 535, "prompt_tokens_details": {"cached_tokens": 0, "text_tokens": 8, "audio_tokens": 0, "image_tokens": 0}, "completion_tokens_details": {"text_tokens": 0, "audio_tokens": 0, "reasoning_tokens": 519}, "input_tokens": 0, "output_tokens": 0, "input_tokens_details": null, "claude_cache_creation_5_m_tokens": 0, "claude_cache_creation_1_h_tokens": 0}}
data: [DONE]
 Si aún no has iniciado sesión o registrado, serás redirigido automáticamente a la página de inicio de sesión que te invita a registrarte e iniciar sesión. Después de iniciar sesión o registrarte, serás devuelto automáticamente a la página actual.
En la primera solicitud, se te otorgará un crédito gratuito, lo que te permitirá usar esta API de forma gratuita.
Si aún no has iniciado sesión o registrado, serás redirigido automáticamente a la página de inicio de sesión que te invita a registrarte e iniciar sesión. Después de iniciar sesión o registrarte, serás devuelto automáticamente a la página actual.
En la primera solicitud, se te otorgará un crédito gratuito, lo que te permitirá usar esta API de forma gratuita.