Proceso de Solicitud
Para usar la API de OpenAI Chat Completion, primero puedes ir a la página de OpenAI Chat Completion API y hacer clic en el botón “Acquire” para obtener las credenciales necesarias para la solicitud: Si aún no has iniciado sesión o registrado, serás redirigido automáticamente a la página de inicio de sesión que te invita a registrarte e iniciar sesión. Después de iniciar sesión o registrarte, serás redirigido automáticamente a la página actual.
En la primera solicitud, se te otorgará un crédito gratuito, lo que te permitirá usar esta API de forma gratuita.
Si aún no has iniciado sesión o registrado, serás redirigido automáticamente a la página de inicio de sesión que te invita a registrarte e iniciar sesión. Después de iniciar sesión o registrarte, serás redirigido automáticamente a la página actual.
En la primera solicitud, se te otorgará un crédito gratuito, lo que te permitirá usar esta API de forma gratuita.
Uso Básico
A continuación, puedes completar el contenido correspondiente en la interfaz, como se muestra en la imagen: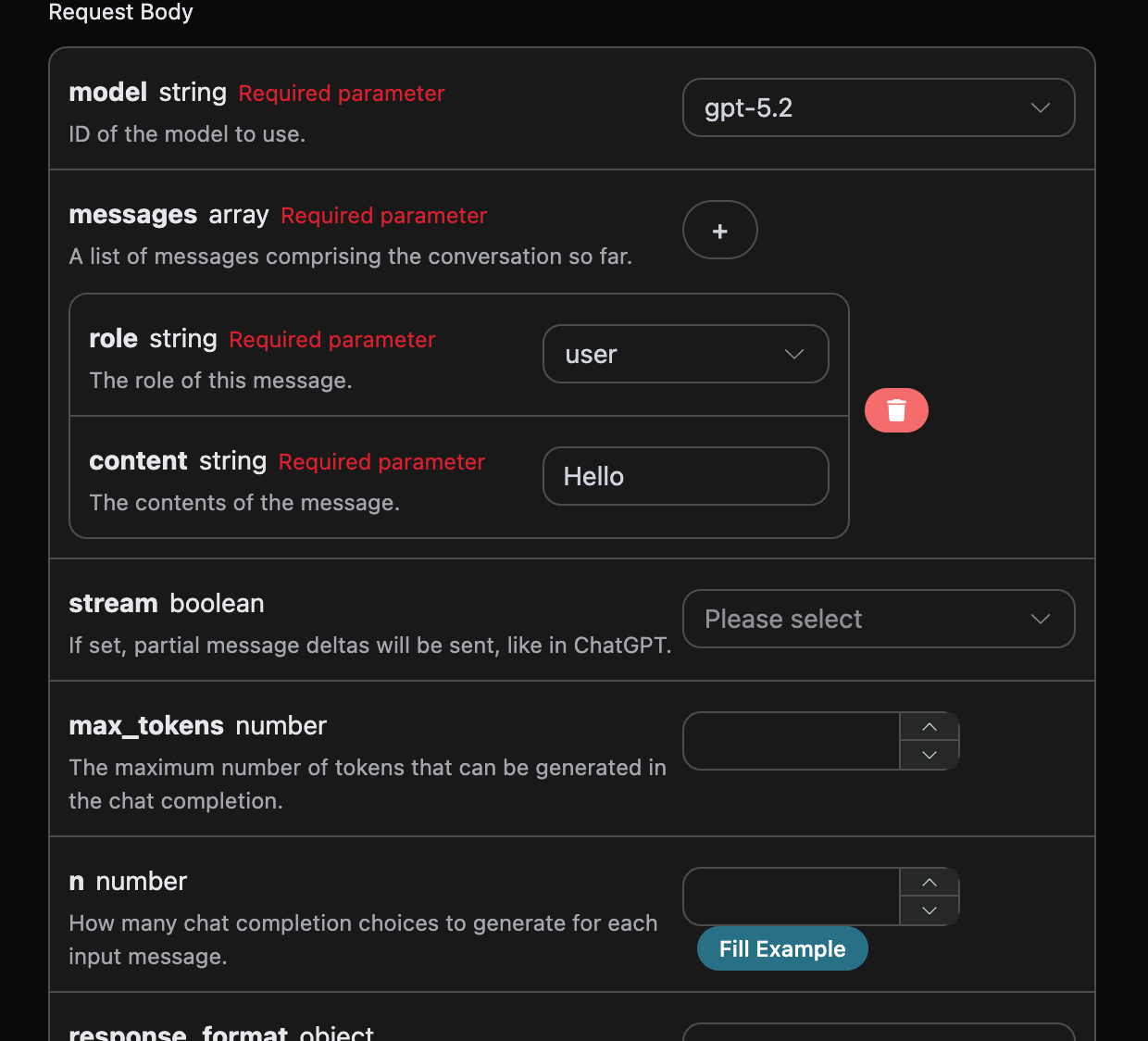
authorization, que se puede seleccionar directamente en la lista desplegable. Otro parámetro es model, model es la categoría del modelo de OpenAI ChatGPT que elegimos usar, aquí tenemos principalmente 20 modelos, los detalles se pueden ver en los modelos que proporcionamos. El último parámetro es messages, messages es un array de nuestras preguntas, que representa que se pueden subir múltiples preguntas a la vez, cada pregunta contiene role y content, donde role indica el rol del preguntador, y hemos proporcionado tres identidades: user, assistant, system. El otro content es el contenido específico de nuestra pregunta.
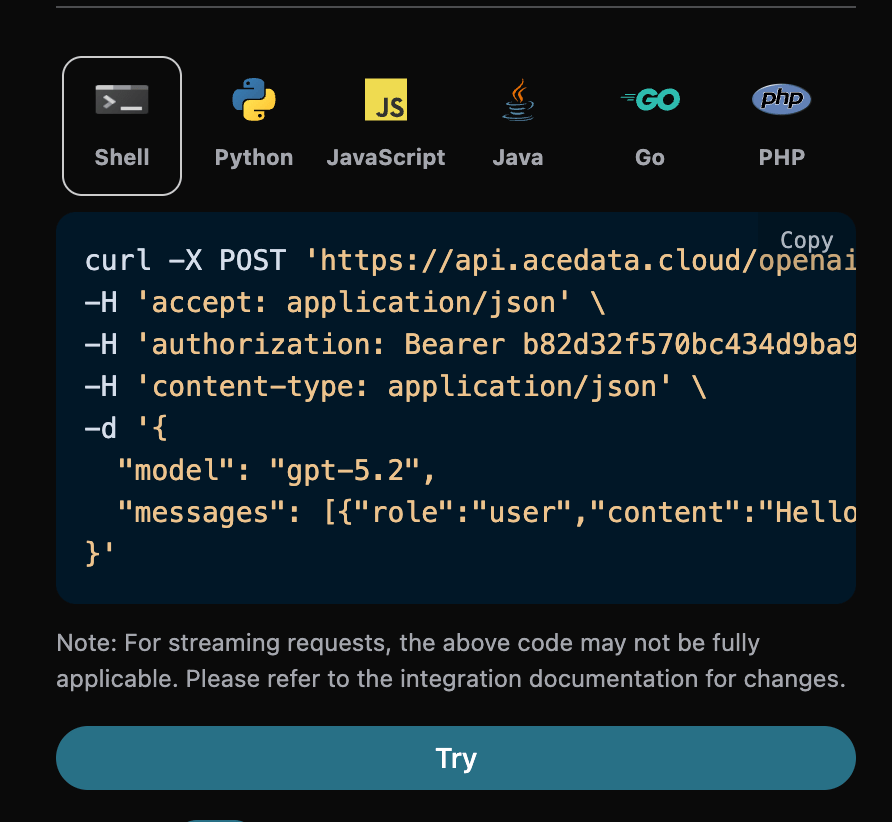
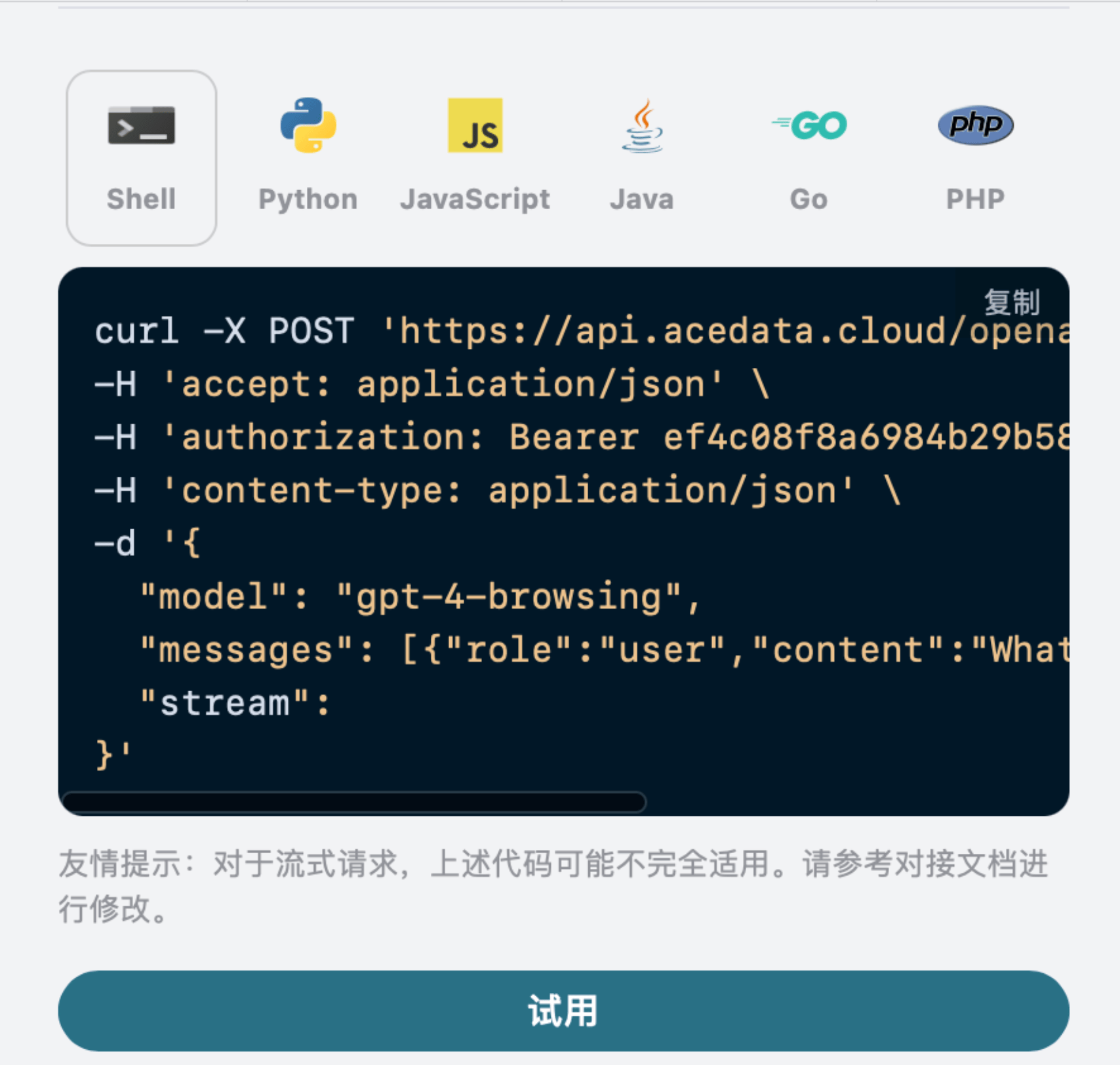
También puedes notar que a la derecha hay un código de llamada correspondiente generado, puedes copiar el código y ejecutarlo directamente, o simplemente hacer clic en el botón “Try” para realizar pruebas.
Parámetros opcionales comunes:
max_tokens: limita el número máximo de tokens en una sola respuesta.temperature: aleatoriedad en la generación, entre 0-2, cuanto mayor sea el valor, más disperso será.n: cuántas respuestas candidatas generar a la vez.response_format: configuración del formato de respuesta.
id, el ID de la tarea de diálogo generada, utilizado para identificar de manera única esta tarea de diálogo.model, el modelo de OpenAI ChatGPT seleccionado.choices, la información de respuesta que ChatGPT proporciona para la pregunta.usage: información estadística sobre los tokens para esta pregunta y respuesta.
choices contiene la información de respuesta de ChatGPT, dentro de choices se puede observar como se muestra en la imagen.
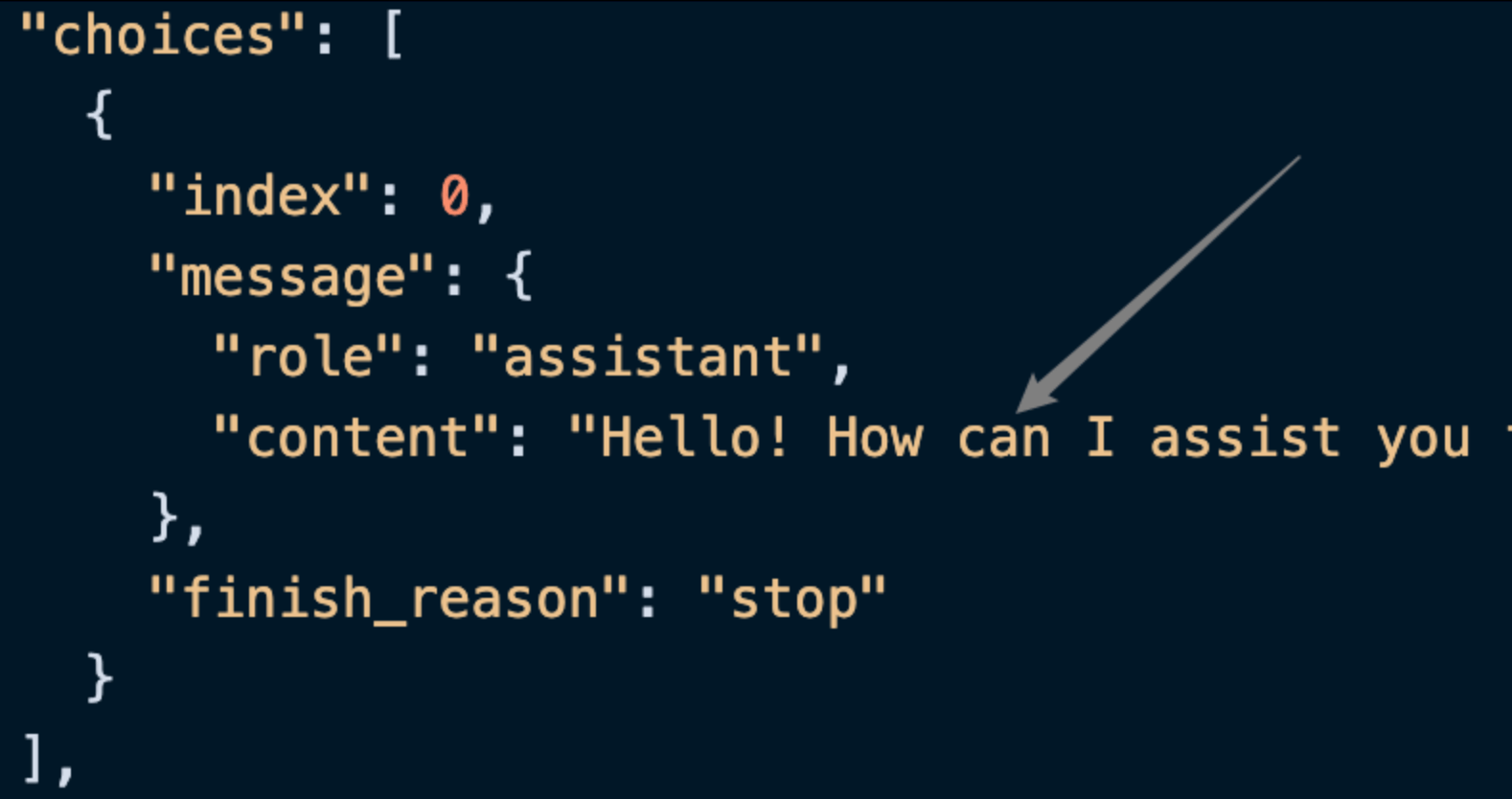
content dentro de choices contiene el contenido específico de la respuesta de ChatGPT.
Respuesta en Flujo
Esta interfaz también admite respuestas en flujo, lo cual es muy útil para la integración en páginas web, ya que permite mostrar el contenido palabra por palabra. Si deseas que la respuesta se devuelva en flujo, puedes cambiar el parámetrostream en el encabezado de la solicitud a true.
El cambio se muestra en la imagen, pero el código de llamada necesita tener los cambios correspondientes para admitir respuestas en flujo.
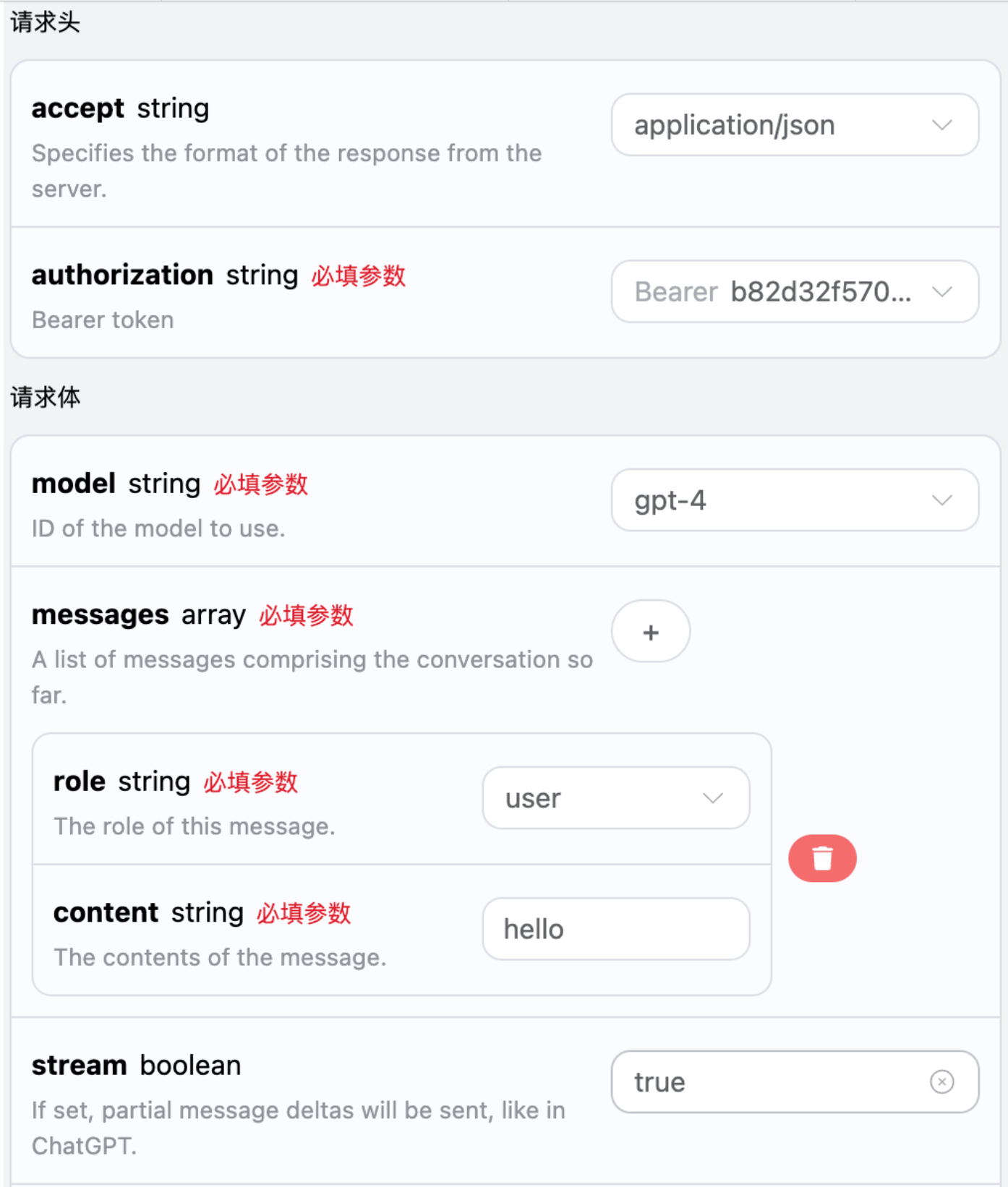
stream a true, la API devolverá los datos JSON correspondientes línea por línea, y a nivel de código, necesitamos hacer los cambios necesarios para obtener los resultados línea por línea.
Código de ejemplo de llamada en Python:
data, donde data contiene choices, que es el contenido de la respuesta más reciente, consistente con el contenido introducido anteriormente. choices es el contenido de respuesta nuevo, que puede ser integrado en su sistema. Al mismo tiempo, el final de la respuesta en flujo se determina según el contenido de data; si el contenido es [DONE], significa que la respuesta en flujo ha terminado por completo. El resultado de data tiene varios campos, que se describen a continuación:
id, el ID que genera la tarea de conversación actual, utilizado para identificar de manera única esta tarea de conversación.model, el modelo seleccionado de OpenAI ChatGPT.choices, la información de respuesta que ChatGPT proporciona en respuesta a la consulta.
Diálogo en múltiples rondas
Si desea integrar la función de diálogo en múltiples rondas, necesita cargar múltiples consultas en el campomessages, ejemplos específicos de múltiples consultas se muestran en la imagen a continuación:
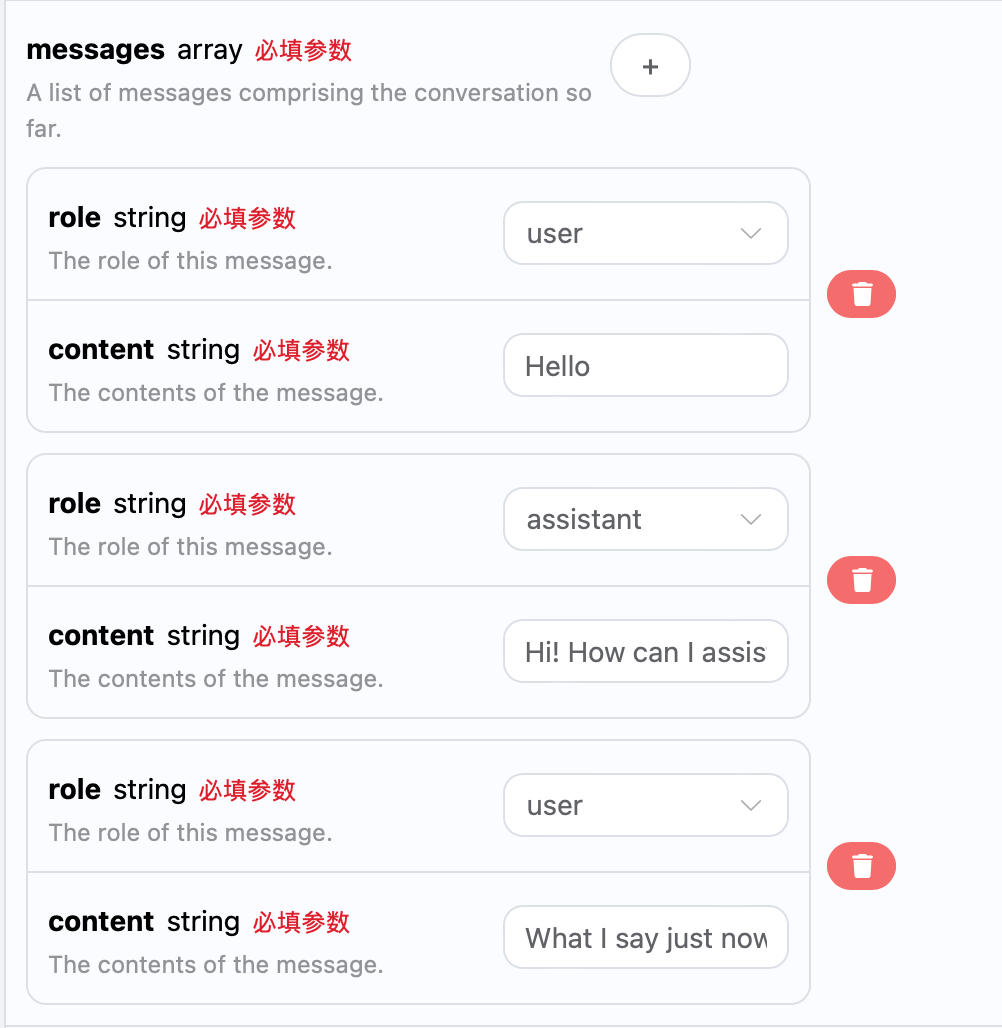
choices es consistente con el contenido de uso básico, que incluye el contenido específico de la respuesta de ChatGPT a múltiples diálogos, lo que permite responder a las preguntas correspondientes según el contenido de múltiples diálogos.
Integración con OpenAI-Python
El servicio de API de OpenAI Chat Completion tiene como upstream el servicio oficial de OpenAI, que se puede consultar en el OpenAI-Python oficial. Este artículo presentará brevemente cómo utilizar el servicio proporcionado oficialmente.- Primero, necesitas configurar un entorno local de
Python, este proceso se puede buscar en Google. - Descarga e instala un entorno de desarrollo, como el editor VSCode.
- Configura las variables de entorno de
OpenAI.
- En la carpeta del proyecto, crea un archivo llamado
.envy guárdalo. - Contenido del archivo
.env:
sk-xxx con tu propia clave. OPENAI_BASE_URL es la interfaz de proxy para acceder a OpenAI.
- Instala los paquetes de dependencias del proyecto.
- Crea un archivo de código fuente de ejemplo.
index.py, cuyo contenido es el siguiente:
Modelo en línea
Los modelos gpt-3.5-browsing y gpt-4-browsing son diferentes de otros modelos, ya que pueden realizar búsquedas en línea según las preguntas y devolver los resultados de búsqueda ajustados adecuadamente. Este artículo demostrará la función en línea a través de un ejemplo específico, y luego podrás completar el contenido correspondiente en la interfaz de API de OpenAI Chat Completion, como se muestra en la imagen: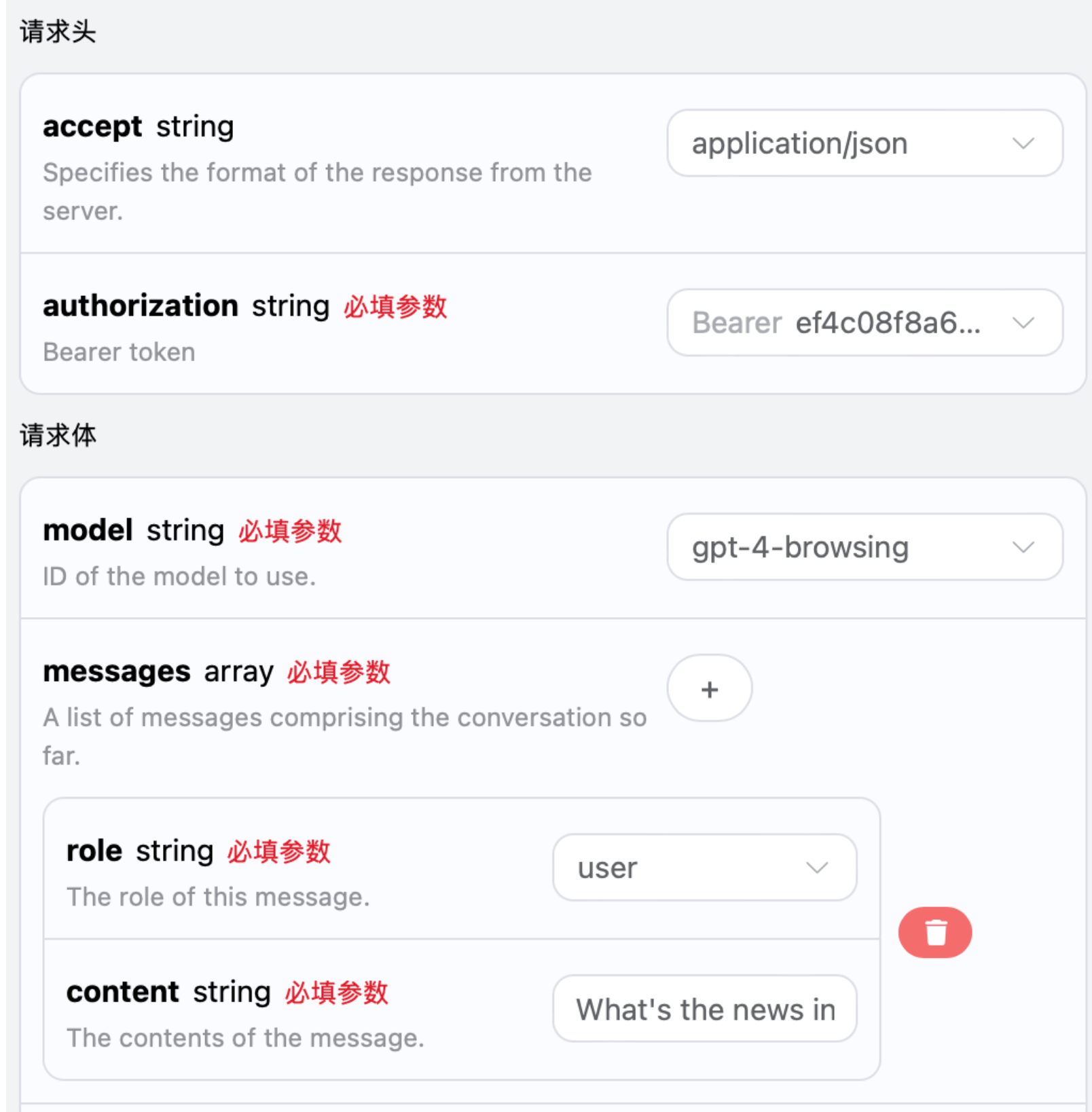
choices se obtuvo a través de consultas en línea y también se proporcionaron enlaces relevantes. La información de respuesta en choices debe ser renderizada utilizando la sintaxis de markdown para obtener la mejor experiencia, lo que también refleja la poderosa ventaja de la función en línea de nuestro modelo.
Modelo visual
gpt-4o es un modelo de lenguaje grande multimodal desarrollado por OpenAI, que ha aumentado la capacidad de comprensión visual sobre la base de GPT-4. Este modelo puede procesar simultáneamente entradas de texto e imagen, logrando una comprensión y generación cruzada de modalidades. El procesamiento de texto utilizando el modelo gpt-4o es consistente con el contenido de uso básico mencionado anteriormente. A continuación, se presentará brevemente cómo utilizar la capacidad de procesamiento de imágenes del modelo. La capacidad de procesamiento de imágenes del modelo gpt-4o se utiliza principalmente añadiendo un campotype al contenido original de content, a través del cual se puede saber si lo que se está subiendo es texto o imagen, permitiendo así utilizar la capacidad de procesamiento de imágenes del modelo gpt-4o. A continuación, se describen dos formas de invocar esta función utilizando Curl y Python.
- Método de script Curl
- Método de script Python
Modelo de dibujo GPT-4o
Ejemplo de solicitud:Manejo de errores
Al llamar a la API, si se encuentra un error, la API devolverá el código de error correspondiente y la información. Por ejemplo:400 token_mismatched: Solicitud incorrecta, posiblemente debido a parámetros faltantes o inválidos.400 api_not_implemented: Solicitud incorrecta, posiblemente debido a parámetros faltantes o inválidos.401 invalid_token: No autorizado, token de autorización inválido o faltante.429 too_many_requests: Demasiadas solicitudes, ha superado el límite de tasa.500 api_error: Error interno del servidor, algo salió mal en el servidor.