Processus de demande
Pour utiliser l’API OpenAI Embeddings, vous pouvez d’abord vous rendre sur la page OpenAI Embeddings API et cliquer sur le bouton « Acquire » pour obtenir les informations d’identification nécessaires à la demande : Si vous n’êtes pas encore connecté ou inscrit, vous serez automatiquement redirigé vers la page de connexion vous invitant à vous inscrire et à vous connecter. Après vous être connecté ou inscrit, vous serez automatiquement renvoyé à la page actuelle.
Lors de la première demande, un quota gratuit sera offert, vous permettant d’utiliser cette API gratuitement.
Si vous n’êtes pas encore connecté ou inscrit, vous serez automatiquement redirigé vers la page de connexion vous invitant à vous inscrire et à vous connecter. Après vous être connecté ou inscrit, vous serez automatiquement renvoyé à la page actuelle.
Lors de la première demande, un quota gratuit sera offert, vous permettant d’utiliser cette API gratuitement.
Utilisation de base
Ensuite, vous pouvez remplir les informations correspondantes sur l’interface, comme indiqué sur l’image :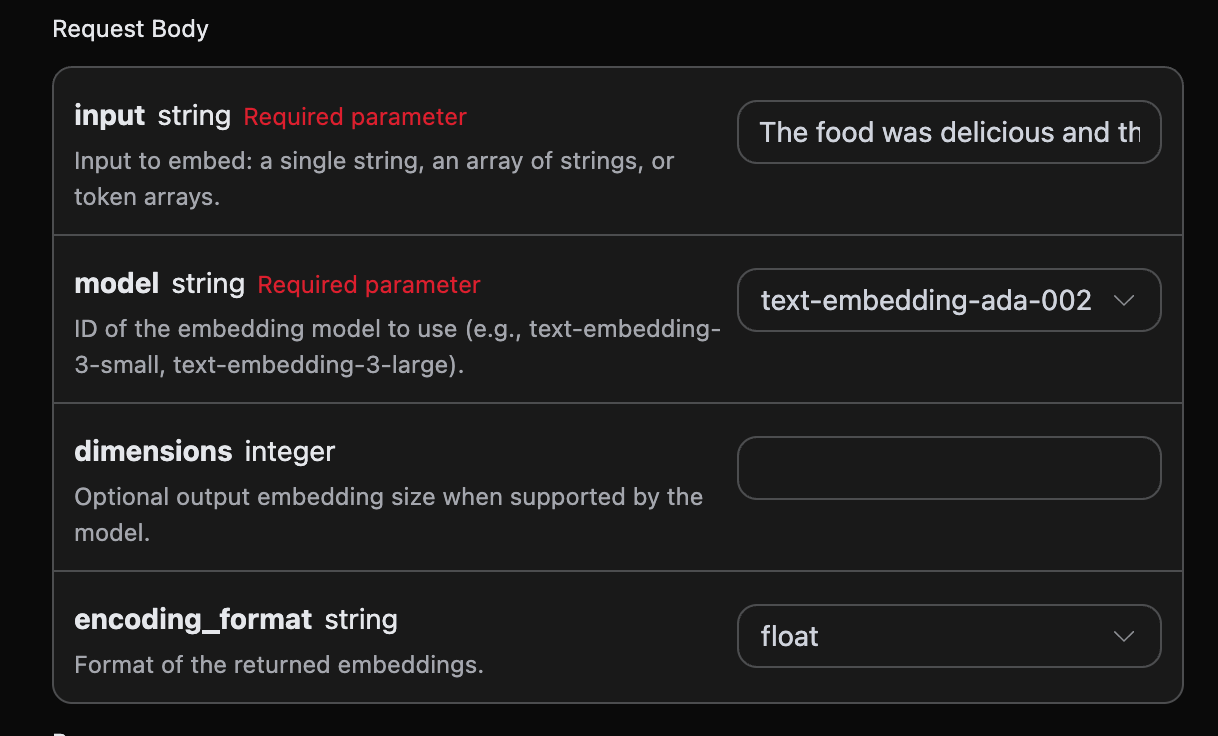
authorization, que vous pouvez sélectionner directement dans la liste déroulante. L’autre paramètre est model, model est la catégorie de modèle que nous choisissons d’utiliser sur le site officiel d’OpenAI, ici nous avons principalement 3 types de modèles, pour plus de détails, vous pouvez consulter les modèles que nous proposons. Le dernier paramètre est input, input est le texte de vecteur de mots que nous devons convertir.
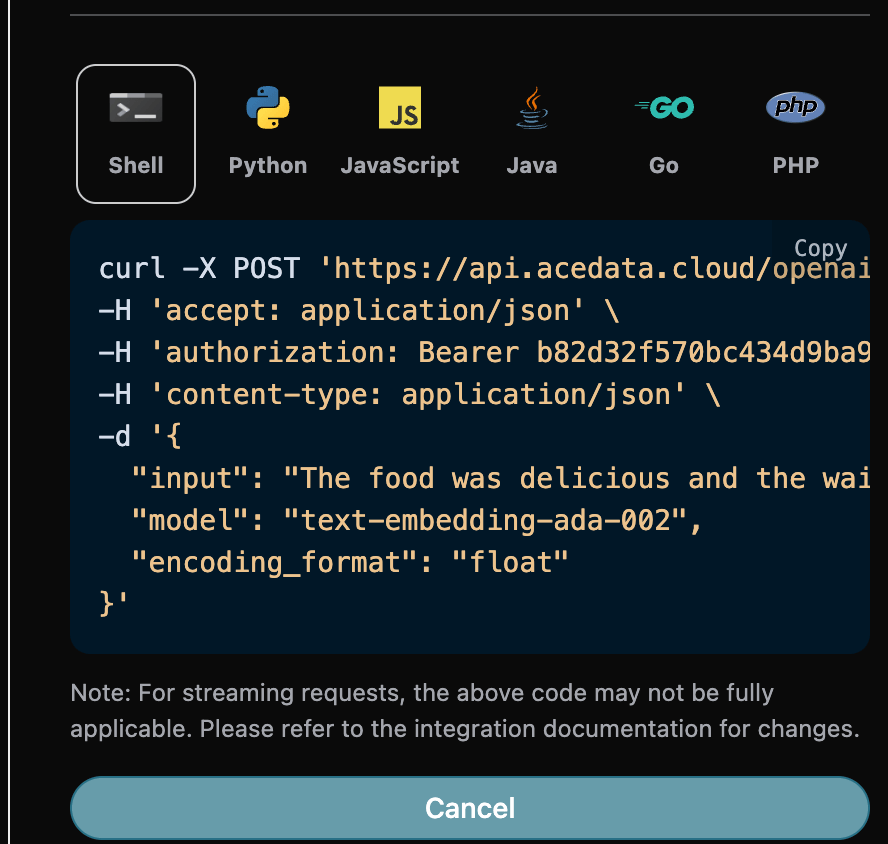
Vous pouvez également remarquer qu’il y a un code d’appel correspondant généré à droite, que vous pouvez copier et exécuter directement, ou vous pouvez simplement cliquer sur le bouton « Try » pour effectuer un test.
Paramètres optionnels :
dimensions: découpage de la dimension du vecteur, la sortie par défaut est la dimension complète.encoding_format: format de retour, optionnelfloatoubase64.
model, le modèle utilisé pour la conversion du texte en vecteur de mots.usage, les informations sur les tokens utilisés pour la conversion du texte en vecteur de mots.data, le résultat du vecteur de mots après conversion du texte.
data contient des informations spécifiques sur le vecteur de mots correspondant au texte, où embedding est le résultat concret du vecteur de mots généré.
Gestion des erreurs
Lors de l’appel de l’API, si une erreur se produit, l’API renverra le code d’erreur et les informations correspondantes. Par exemple :400 token_mismatched: Mauvaise demande, probablement en raison de paramètres manquants ou invalides.400 api_not_implemented: Mauvaise demande, probablement en raison de paramètres manquants ou invalides.401 invalid_token: Non autorisé, jeton d’autorisation invalide ou manquant.429 too_many_requests: Trop de demandes, vous avez dépassé la limite de taux.500 api_error: Erreur interne du serveur, quelque chose s’est mal passé sur le serveur.