Processus de demande
Pour utiliser l’API de Complétion de Chat OpenAI, vous pouvez d’abord vous rendre sur la page OpenAI Chat Completion API et cliquer sur le bouton « Acquire » pour obtenir les informations d’identification nécessaires à la demande : Si vous n’êtes pas encore connecté ou inscrit, vous serez automatiquement redirigé vers la page de connexion pour vous inviter à vous inscrire et à vous connecter. Après vous être connecté ou inscrit, vous serez automatiquement renvoyé à la page actuelle.
Lors de votre première demande, un quota gratuit sera offert, vous permettant d’utiliser cette API gratuitement.
Si vous n’êtes pas encore connecté ou inscrit, vous serez automatiquement redirigé vers la page de connexion pour vous inviter à vous inscrire et à vous connecter. Après vous être connecté ou inscrit, vous serez automatiquement renvoyé à la page actuelle.
Lors de votre première demande, un quota gratuit sera offert, vous permettant d’utiliser cette API gratuitement.
Utilisation de base
Ensuite, vous pouvez remplir le contenu correspondant sur l’interface, comme indiqué sur l’image :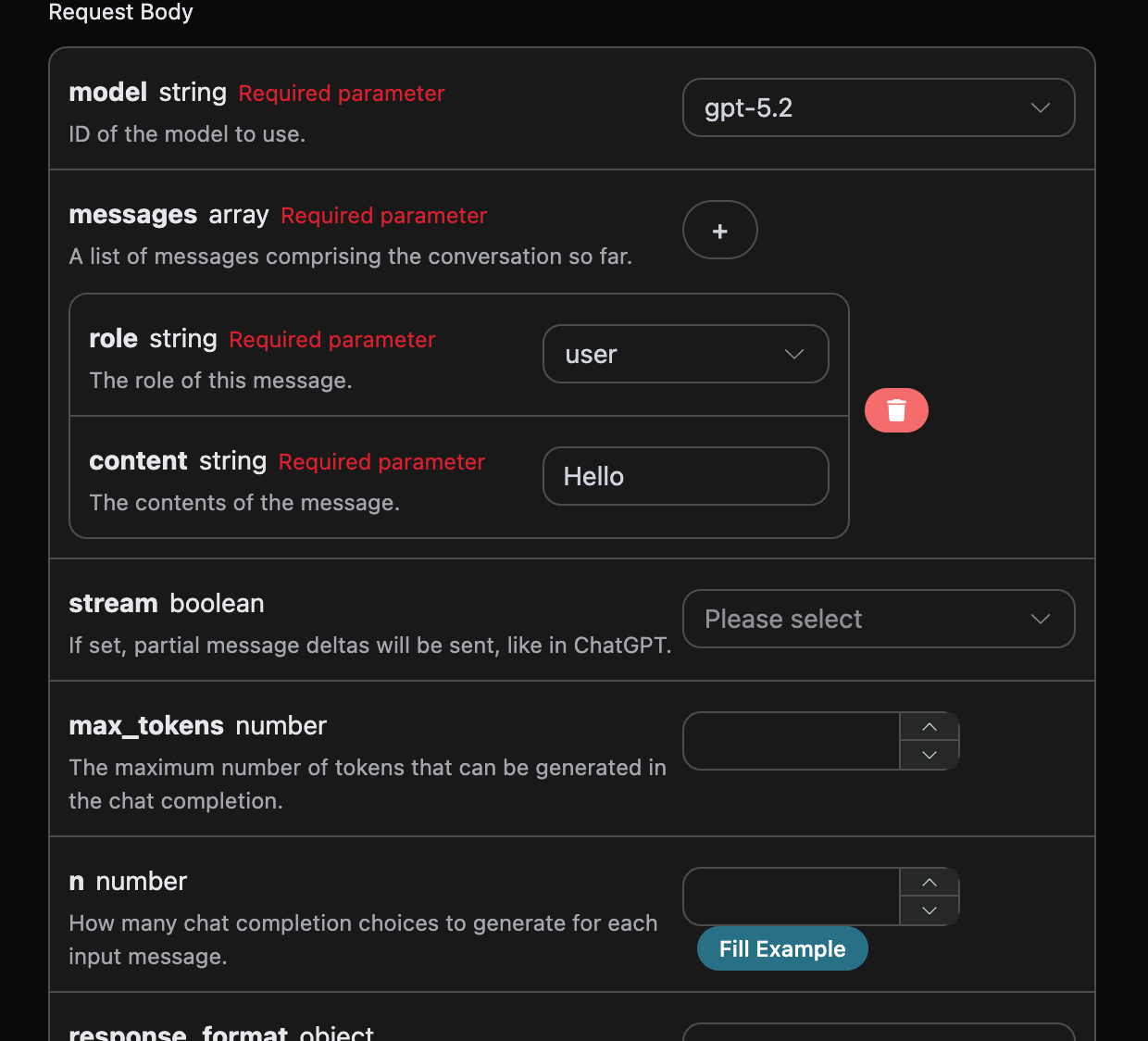
authorization, que vous pouvez sélectionner directement dans la liste déroulante. L’autre paramètre est model, qui correspond à la catégorie de modèle que nous choisissons d’utiliser sur le site officiel d’OpenAI ChatGPT. Ici, nous avons principalement 20 modèles, dont les détails peuvent être consultés dans les modèles que nous fournissons. Le dernier paramètre est messages, qui est un tableau de nos questions. Il s’agit d’un tableau qui permet de télécharger plusieurs questions simultanément, chaque question contenant role et content, où role indique le rôle du questionneur. Nous avons trois identités : user, assistant, system. L’autre content est le contenu spécifique de notre question.
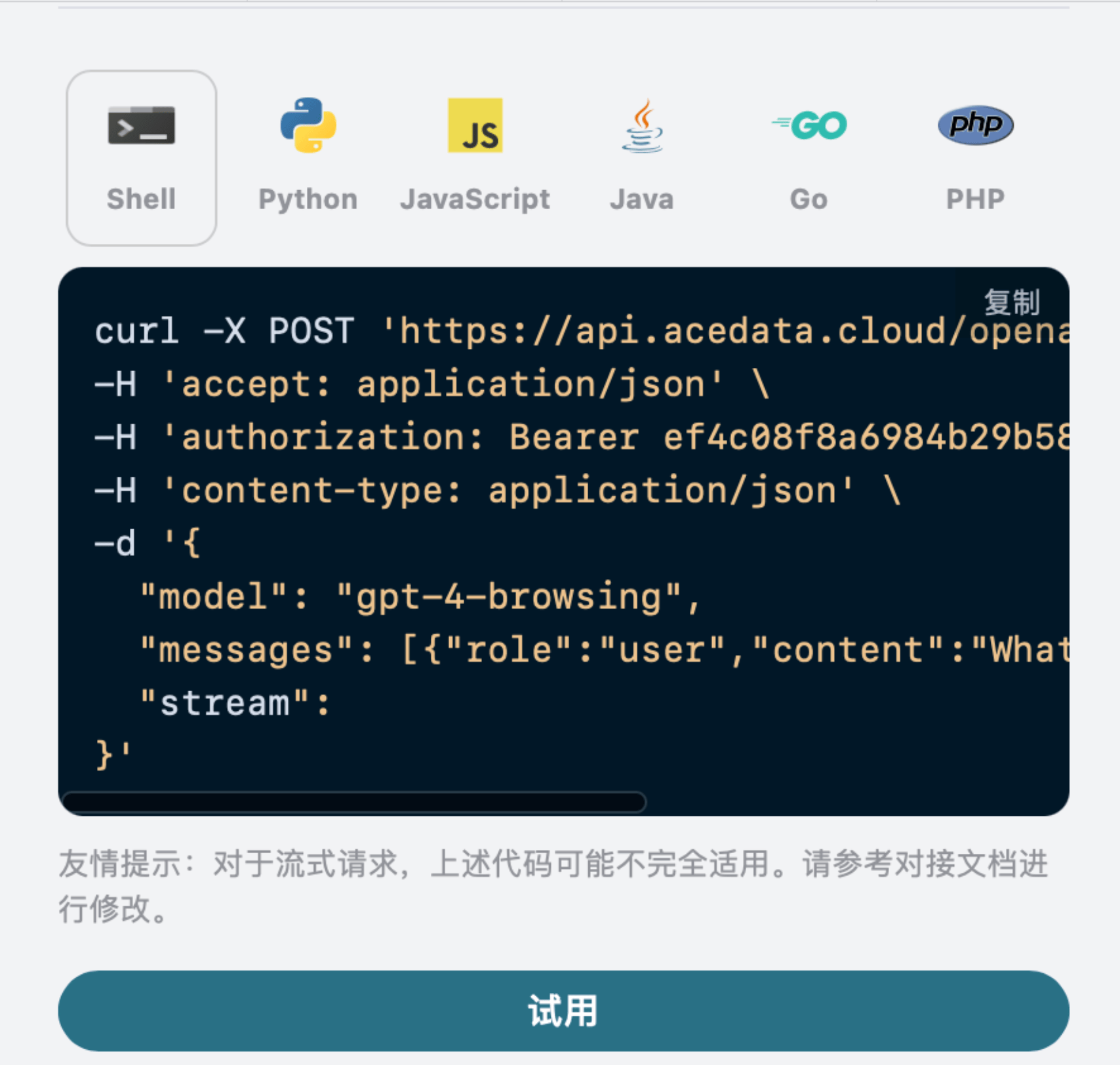
Vous pouvez également remarquer qu’il y a un code d’appel correspondant généré à droite, que vous pouvez copier et exécuter directement, ou cliquer sur le bouton « Try » pour effectuer un test.
Paramètres optionnels courants :
max_tokens: limite le nombre maximum de tokens pour une réponse unique.temperature: génère de l’aléatoire, entre 0 et 2, plus la valeur est élevée, plus c’est dispersé.n: combien de réponses candidates générer en une seule fois.response_format: paramètres de format de retour.
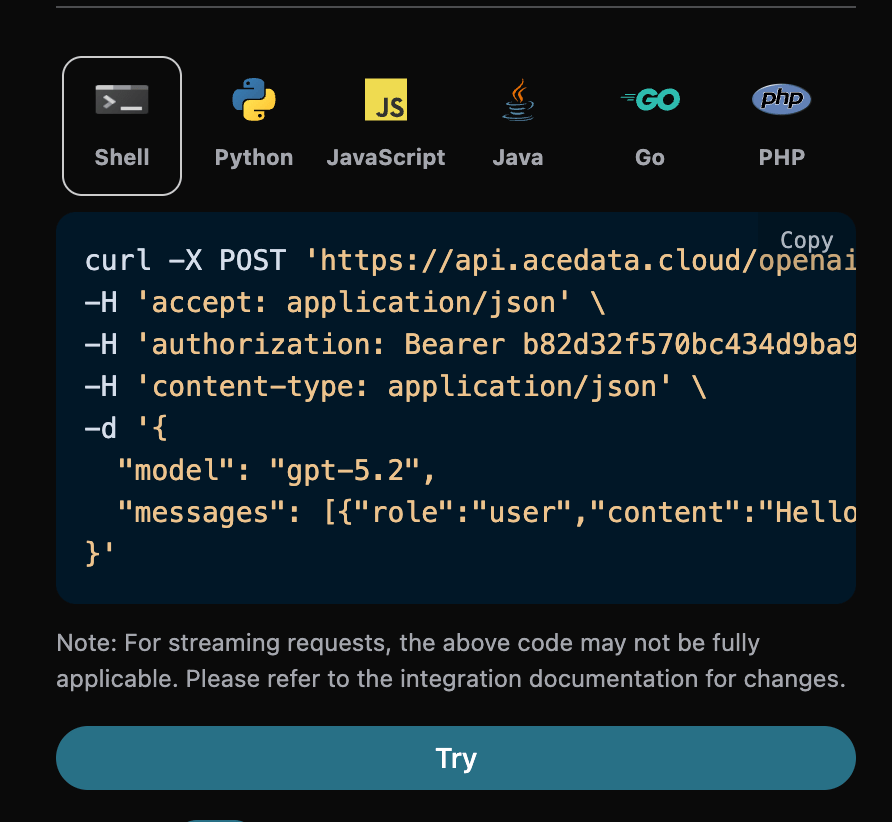
id, l’ID de la tâche de dialogue générée, utilisé pour identifier de manière unique cette tâche de dialogue.model, le modèle choisi sur le site officiel d’OpenAI ChatGPT.choices, les informations de réponse fournies par ChatGPT en réponse aux questions.usage: les informations statistiques sur les tokens pour cette question-réponse.
choices contient les informations de réponse de ChatGPT, et vous pouvez voir comme indiqué sur l’image.
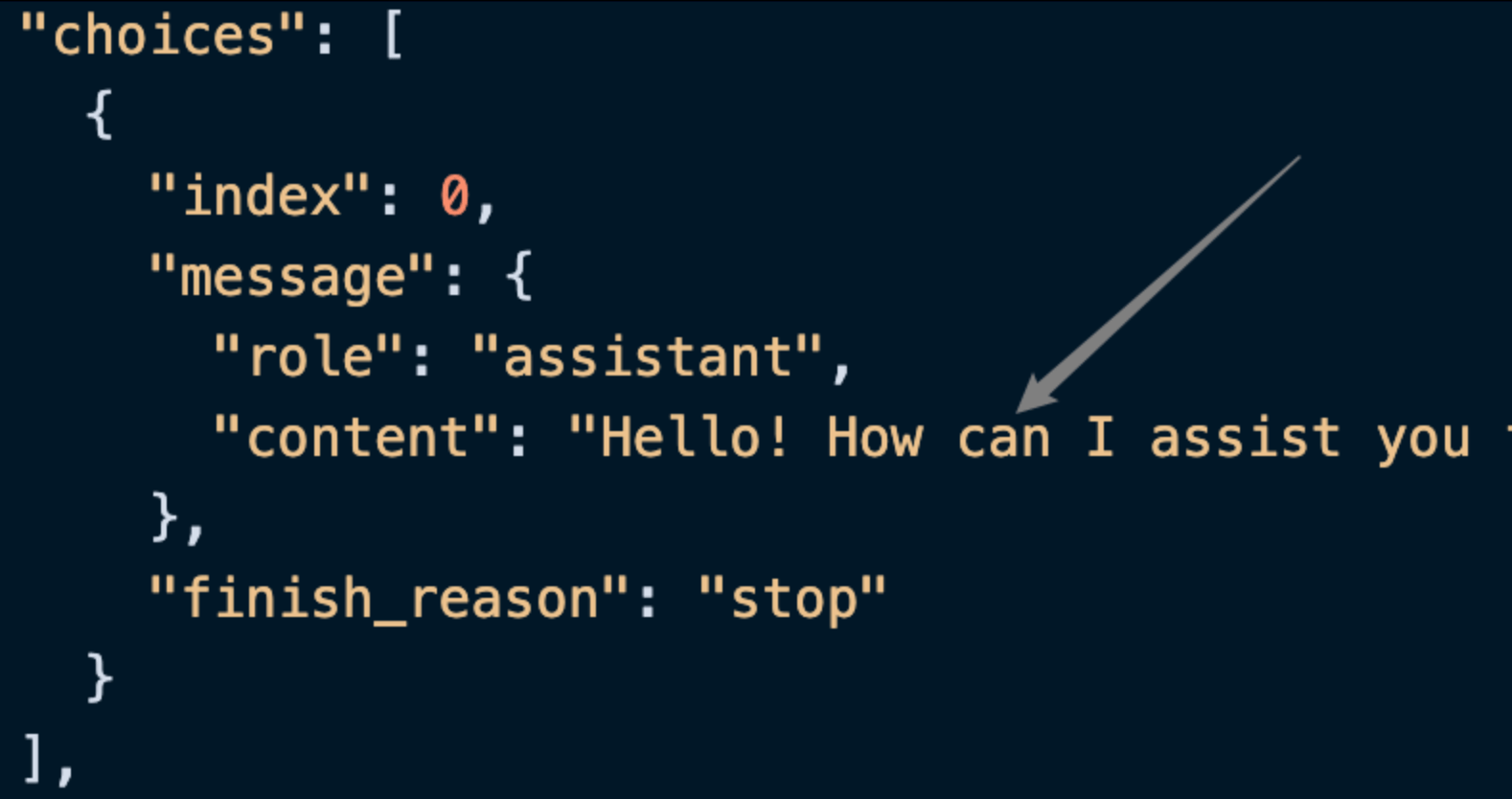
content dans choices contient le contenu spécifique de la réponse de ChatGPT.
Réponse en flux
Cette interface prend également en charge les réponses en flux, ce qui est très utile pour l’intégration sur le web, permettant d’afficher les résultats caractère par caractère. Si vous souhaitez une réponse en flux, vous pouvez modifier le paramètrestream dans l’en-tête de la requête en le changeant en true.
La modification est illustrée sur l’image, mais le code d’appel doit également être modifié pour prendre en charge les réponses en flux.
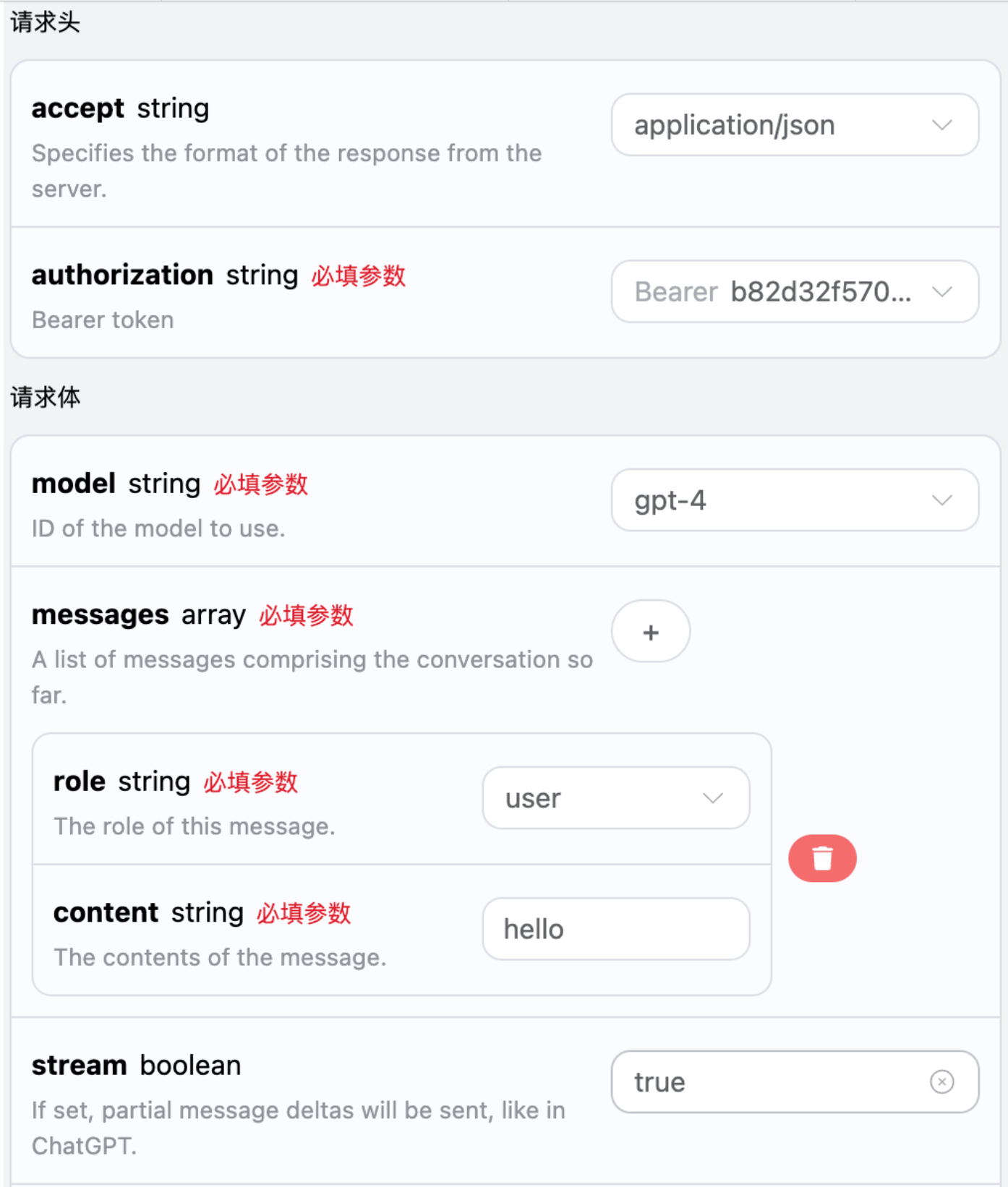
stream en true, l’API renverra les données JSON ligne par ligne, et au niveau du code, nous devons apporter les modifications nécessaires pour obtenir les résultats ligne par ligne.
Exemple de code d’appel en Python :
data, où data contient les choices qui sont le contenu de la réponse la plus récente, conforme à ce qui a été décrit ci-dessus. choices est le contenu de la réponse ajoutée, que vous pouvez intégrer dans votre système. De plus, la fin de la réponse en flux est déterminée par le contenu de data, si le contenu est [DONE], cela signifie que la réponse en flux est entièrement terminée. Les résultats de data retournés contiennent plusieurs champs, décrits comme suit :
id, l’ID généré pour cette tâche de conversation, utilisé pour identifier de manière unique cette tâche de conversation.model, le modèle choisi sur le site officiel d’OpenAI ChatGPT.choices, les informations de réponse fournies par ChatGPT en réponse aux questions.
Dialogue multi-tours
Si vous souhaitez intégrer une fonctionnalité de dialogue multi-tours, vous devez télécharger plusieurs questions dans le champmessages, des exemples spécifiques de plusieurs questions sont illustrés ci-dessous :
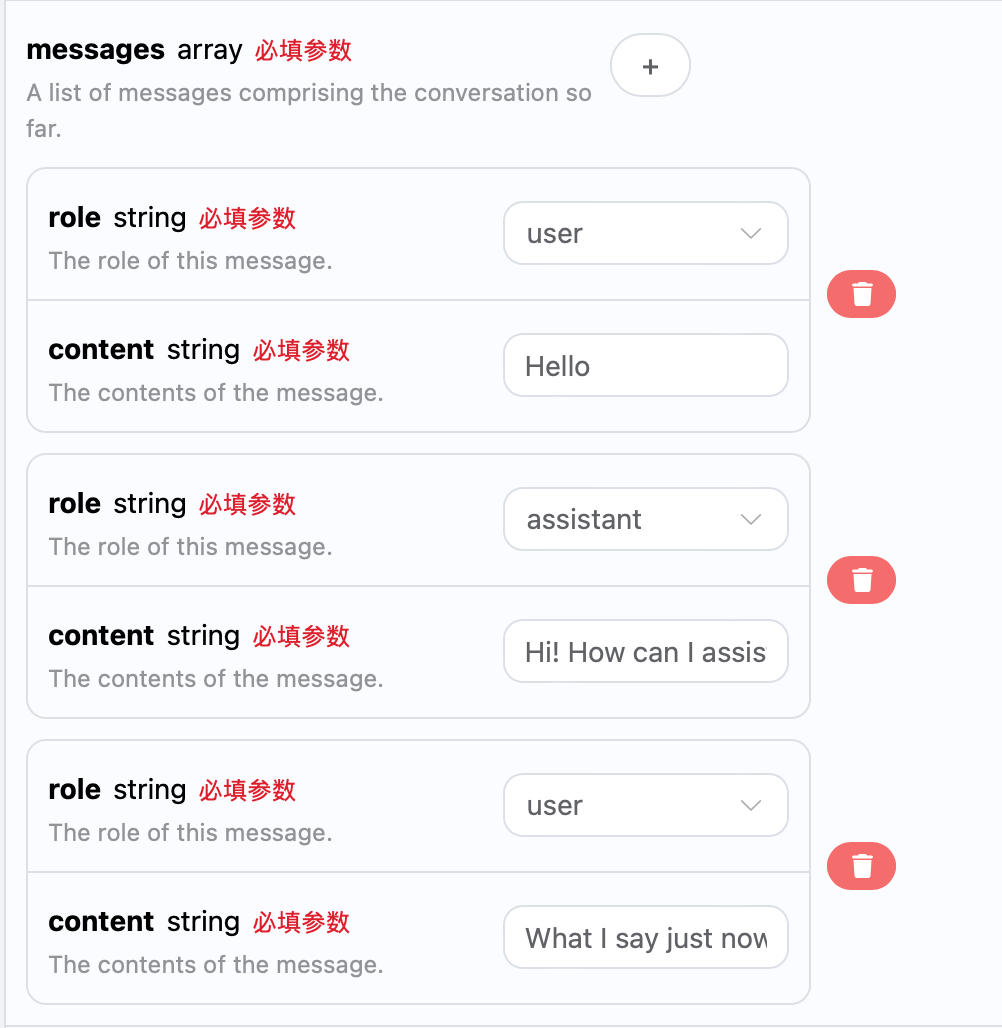
choices sont cohérentes avec le contenu de base utilisé, cela inclut le contenu spécifique de la réponse de ChatGPT à plusieurs dialogues, permettant ainsi de répondre aux questions correspondantes en fonction de plusieurs contenus de dialogue.
Intégration avec OpenAI-Python
Le service OpenAI Chat Completion API est en amont du service officiel d’OpenAI, vous pouvez consulter le OpenAI-Python officiel pour plus de détails, cet article présentera brièvement comment utiliser le service fourni par l’officiel.- Tout d’abord, vous devez configurer un environnement
Pythonlocal, ce processus peut être recherché sur Google. - Téléchargez et installez un environnement de développement, par exemple, installez l’éditeur VSCode.
- Configurez les variables d’environnement
OpenAI.
- Dans le dossier du projet, créez un fichier nommé
.envet enregistrez-le. - Contenu du fichier
.env:
sk-xxx par votre propre clé. OPENAI_BASE_URL est l’interface proxy pour accéder à OpenAI.
- Installez les paquets de dépendance du projet
- Créez un fichier source d’exemple
index.py, le contenu est le suivant :
Modèle en ligne
Les modèles gpt-3.5-browsing et gpt-4-browsing sont différents des autres modèles, ils peuvent effectuer des recherches en ligne en fonction des mots de question et ajuster les résultats de recherche en ligne pour vous les renvoyer. Cet article démontrera la fonctionnalité en ligne à travers un exemple concret, vous pouvez ensuite remplir le contenu correspondant sur l’interface OpenAI Chat Completion API, comme illustré ci-dessous :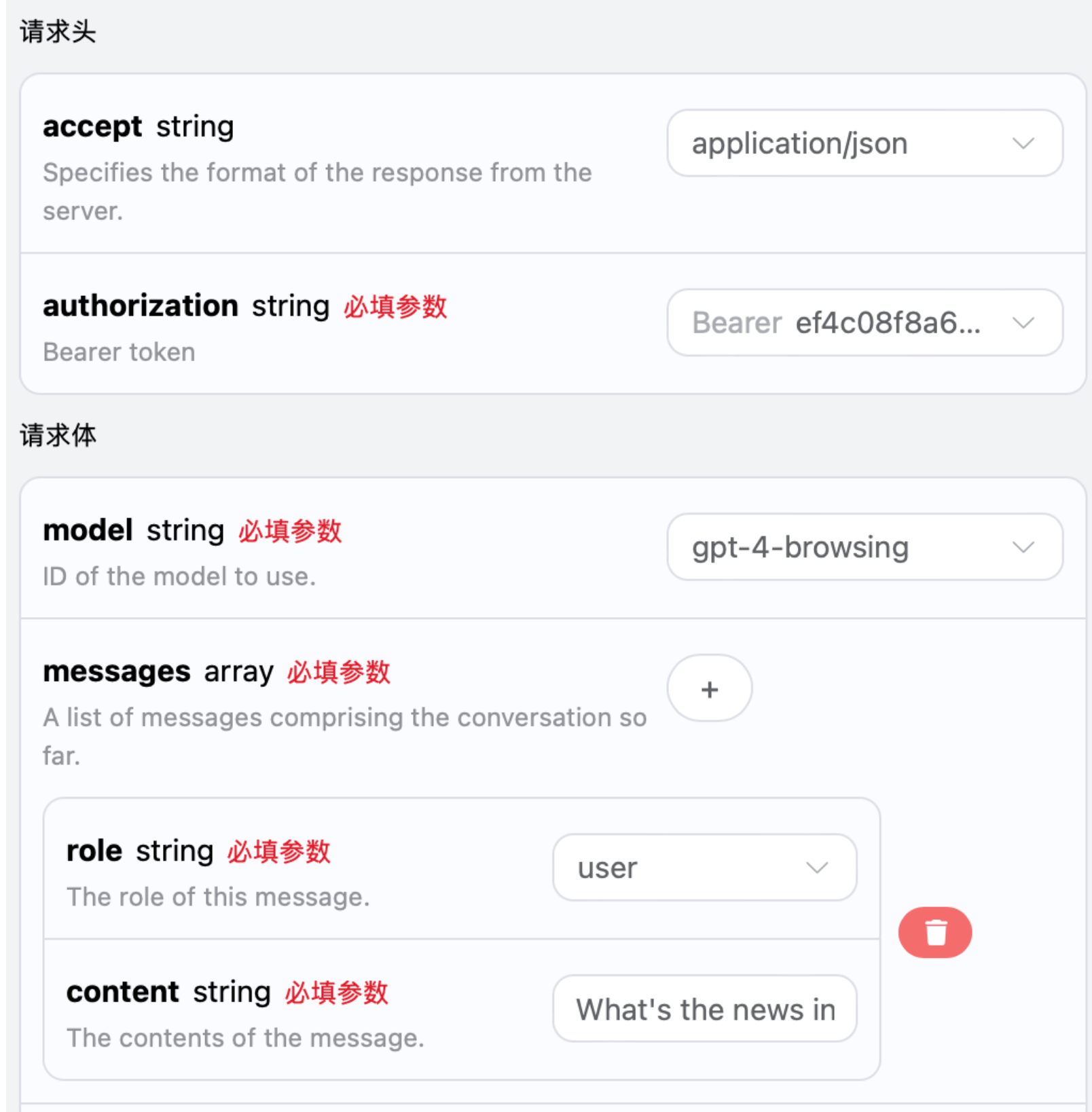
choices sont basées sur les recherches en ligne et fournissent également des liens pertinents. Les informations de réponse dans choices doivent être rendues en utilisant la syntaxe markdown pour obtenir la meilleure expérience, ce qui met également en évidence la puissance de la fonctionnalité en ligne de notre modèle.
Modèle visuel
gpt-4o est un modèle de langage multimodal de grande taille développé par OpenAI, qui a ajouté des capacités de compréhension visuelle à GPT-4. Ce modèle peut traiter simultanément des entrées textuelles et d’images, réalisant une compréhension et une génération intermodales. L’utilisation des capacités de traitement d’images du modèle gpt-4o est similaire à l’utilisation de base décrite ci-dessus, ci-dessous nous allons brièvement expliquer comment utiliser la capacité de traitement d’images du modèle. L’utilisation des capacités de traitement d’images du modèle gpt-4o se fait principalement en ajoutant un champtype à la base du contenu content, ce champ permet de savoir si ce qui est téléchargé est du texte ou une image, permettant ainsi d’utiliser les capacités de traitement d’images du modèle gpt-4o. Nous allons principalement aborder comment appeler cette fonctionnalité en utilisant Curl et Python.
- Méthode de script Curl
- Méthode de script Python
Modèle de dessin GPT-4o
Exemple de requête :Gestion des erreurs
Lors de l’appel de l’API, si une erreur se produit, l’API renverra le code d’erreur et les informations correspondantes. Par exemple :400 token_mismatched: Mauvaise requête, probablement en raison de paramètres manquants ou invalides.400 api_not_implemented: Mauvaise requête, probablement en raison de paramètres manquants ou invalides.401 invalid_token: Non autorisé, jeton d’autorisation invalide ou manquant.429 too_many_requests: Trop de requêtes, vous avez dépassé la limite de taux.500 api_error: Erreur interne du serveur, quelque chose s’est mal passé sur le serveur.