kimi-k3, est destiné à la programmation à long terme, aux agents, au raisonnement complexe et au travail de connaissance, et peut être appelé via l’API Chat Completions compatible avec OpenAI.
Ce document présente principalement le processus d’utilisation de l’API Kimi Chat Completion, qui nous permet d’utiliser facilement les fonctionnalités de conversation de Kimi.
Processus de demande
Pour utiliser l’API Kimi Chat Completion, commencez par obtenir votre token API sur le tableau de bord Ace Data Cloud pour le garder en réserve.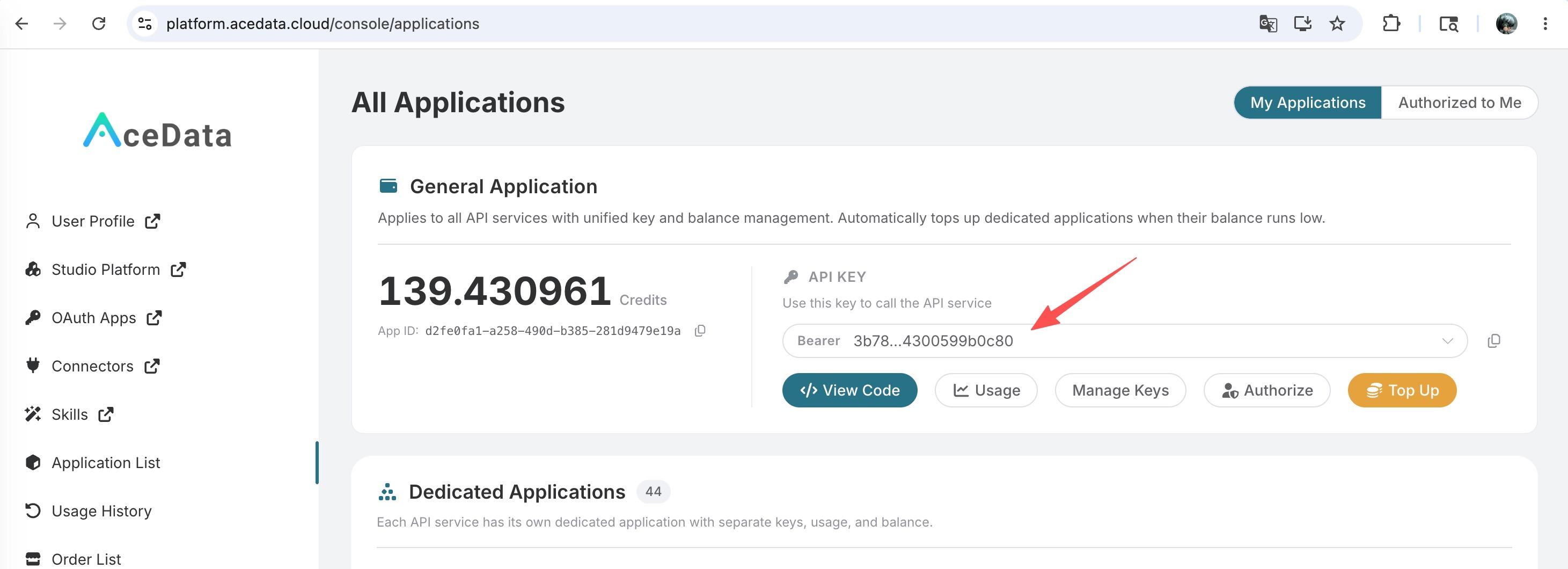 Si vous n’êtes pas encore connecté ou inscrit, vous serez automatiquement redirigé vers la page de connexion pour vous inviter à vous inscrire et à vous connecter, après quoi vous serez automatiquement renvoyé à la page actuelle.
Un seul token API suffit pour appeler tous les services de la plateforme, sans avoir besoin de demander un pour chaque service. La première demande vous donnera un quota gratuit pour une expérience sans frais ; en cas de quota insuffisant, vous pouvez recharger le solde général dans le tableau de bord.
Si vous n’êtes pas encore connecté ou inscrit, vous serez automatiquement redirigé vers la page de connexion pour vous inviter à vous inscrire et à vous connecter, après quoi vous serez automatiquement renvoyé à la page actuelle.
Un seul token API suffit pour appeler tous les services de la plateforme, sans avoir besoin de demander un pour chaque service. La première demande vous donnera un quota gratuit pour une expérience sans frais ; en cas de quota insuffisant, vous pouvez recharger le solde général dans le tableau de bord.
📘 Documentation complète : Kimi Chat Completion API →
Utilisation de base
Vous pouvez ensuite remplir le contenu correspondant sur l’interface, comme indiqué sur l’image :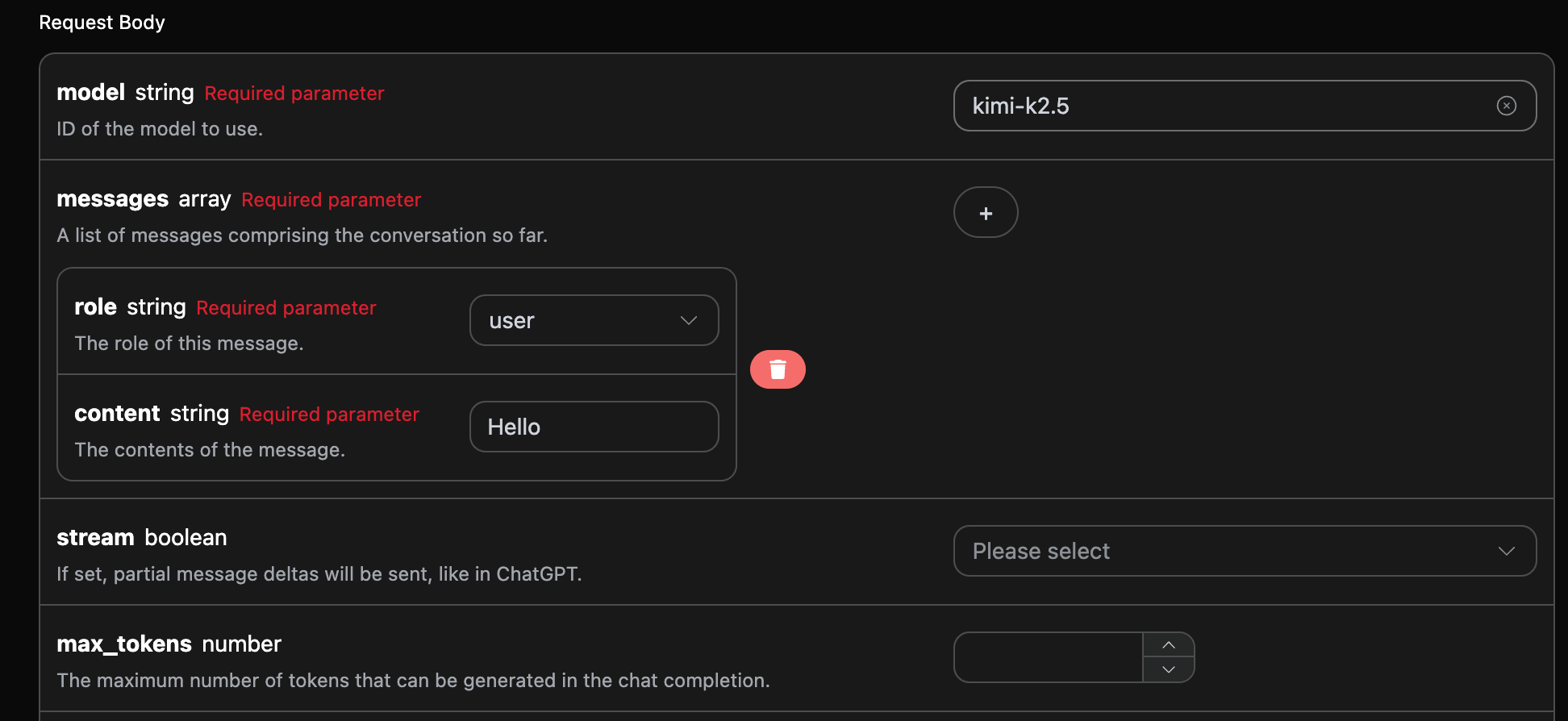
authorization peut être sélectionné directement dans la liste déroulante ; model est utilisé pour choisir le modèle Kimi, il est recommandé d’utiliser kimi-k3 ; messages est un tableau de messages de conversation, chaque message contenant role et content, où role prend en charge user, assistant, system et tool.
Vous pouvez également remarquer qu’il y a un code d’appel correspondant généré à droite, que vous pouvez copier et exécuter directement, ou cliquer sur le bouton « Essayer » pour effectuer un test.
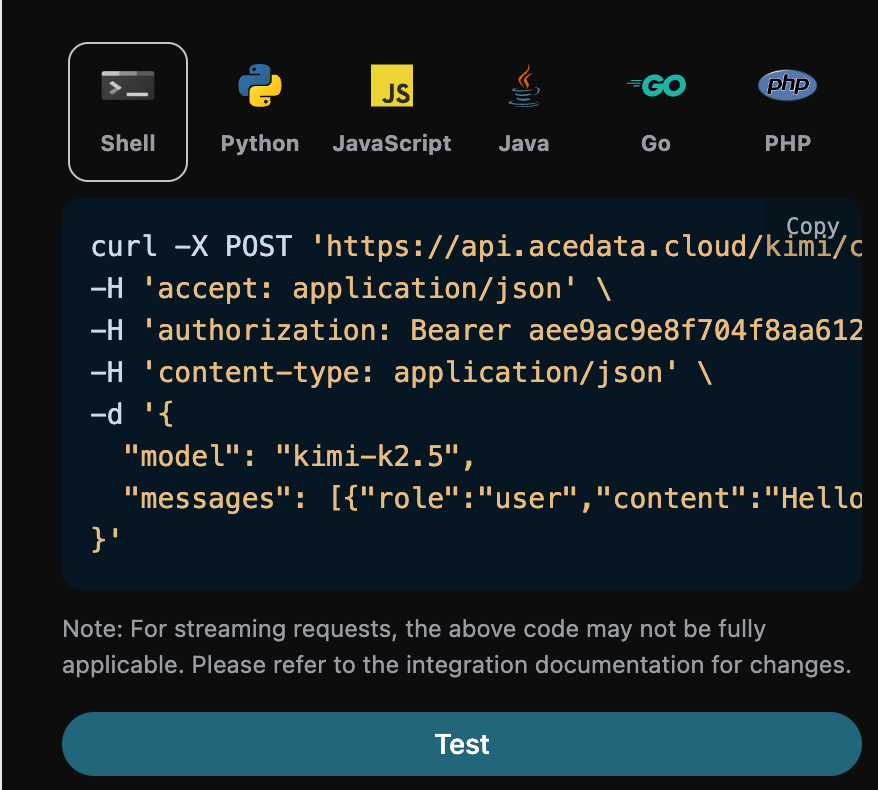
reasoning_effort: max (les champs d’extension non utilisés sont omis) :
id, l’ID généré pour cette tâche de conversation, utilisé pour identifier de manière unique cette tâche de conversation.model, le modèle Kimi sélectionné sur le site officiel.choices, les informations de réponse fournies par Kimi en fonction de la question.usage: les informations statistiques sur les tokens pour cette question-réponse.
choices contient les informations de réponse de Kimi, et à l’intérieur de choices se trouvent les informations spécifiques de la réponse de Kimi, comme le montre l’image.
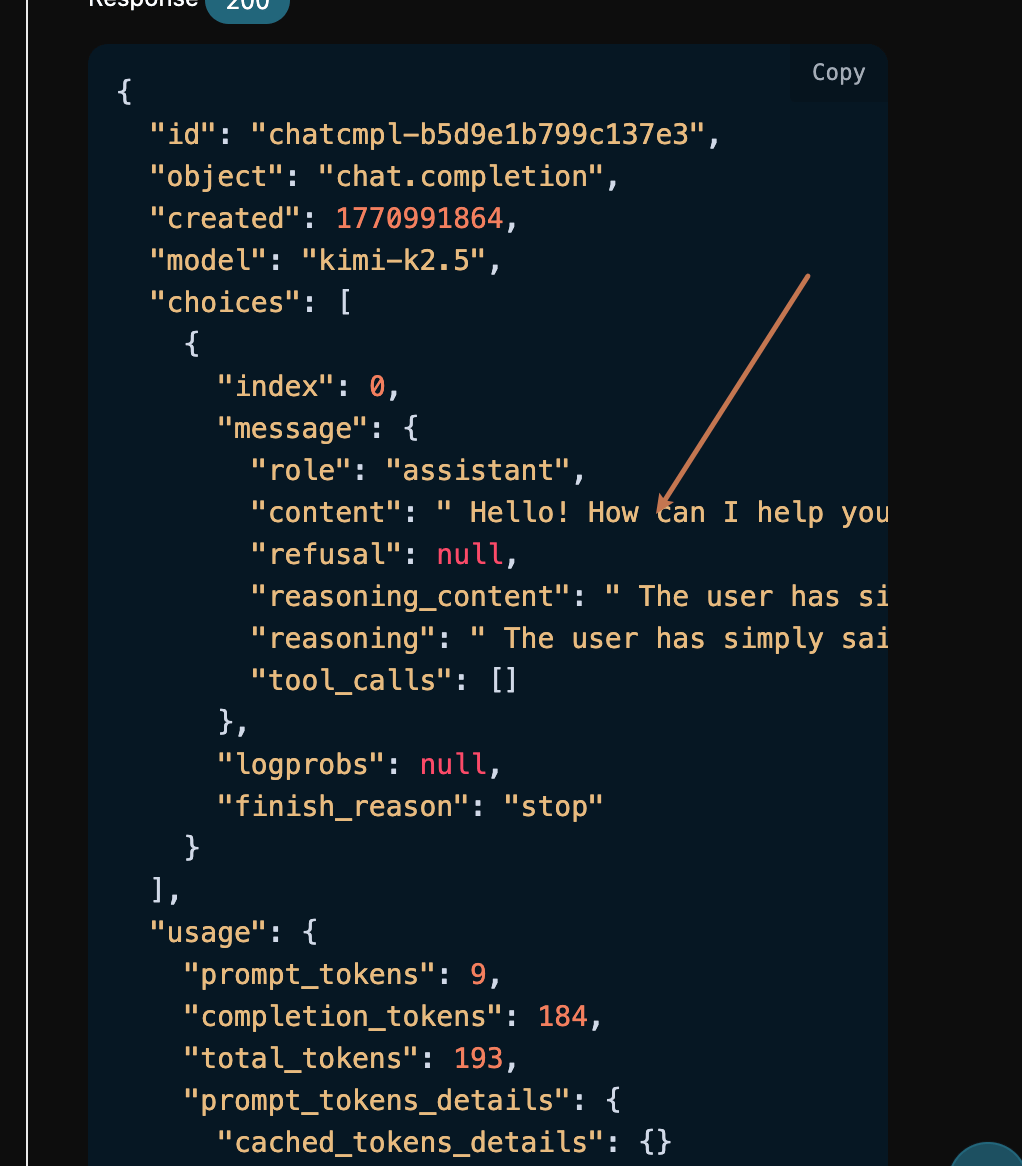
content à l’intérieur de choices contient le contenu spécifique de la réponse de Kimi ; K3 peut également renvoyer reasoning_content, utilisé pour indiquer le processus de raisonnement.
Intensité de raisonnement K3
kimi-k3 active toujours le raisonnement. Le corps de la requête prend en charge le champ reasoning_effort au niveau supérieur, la seule valeur actuellement prise en charge est max ; si ce champ est omis, max est également utilisé. standard, high ou d’autres chaînes peuvent être partiellement acceptées par des systèmes en amont compatibles, mais il n’est pas garanti que cela modifie le comportement de raisonnement, ne pas en dépendre.
messages, y compris reasoning_content et tool_calls.
Références officielles
- Thinking Effort : indique que Kimi K3 active toujours le raisonnement, la seule valeur actuellement prise en charge pour
reasoning_effortestmax. - Model Parameter Reference : compare les paramètres de raisonnement, la fenêtre de contexte et les différences d’appels d’outils entre K3 et la série K2.
- Create Chat Completion : demande, réponse et définition des champs OpenAPI pour les Chat Completions officiels de Moonshot.
Réponse en continu
Cette interface prend également en charge les réponses en continu, ce qui est très utile pour l’intégration web, permettant d’afficher les résultats caractère par caractère. Si vous souhaitez renvoyer une réponse en continu, vous pouvez modifier le paramètrestream dans l’en-tête de la requête pour le définir sur true.
La modification est illustrée sur l’image, mais le code d’appel doit également être modifié pour prendre en charge les réponses en continu.
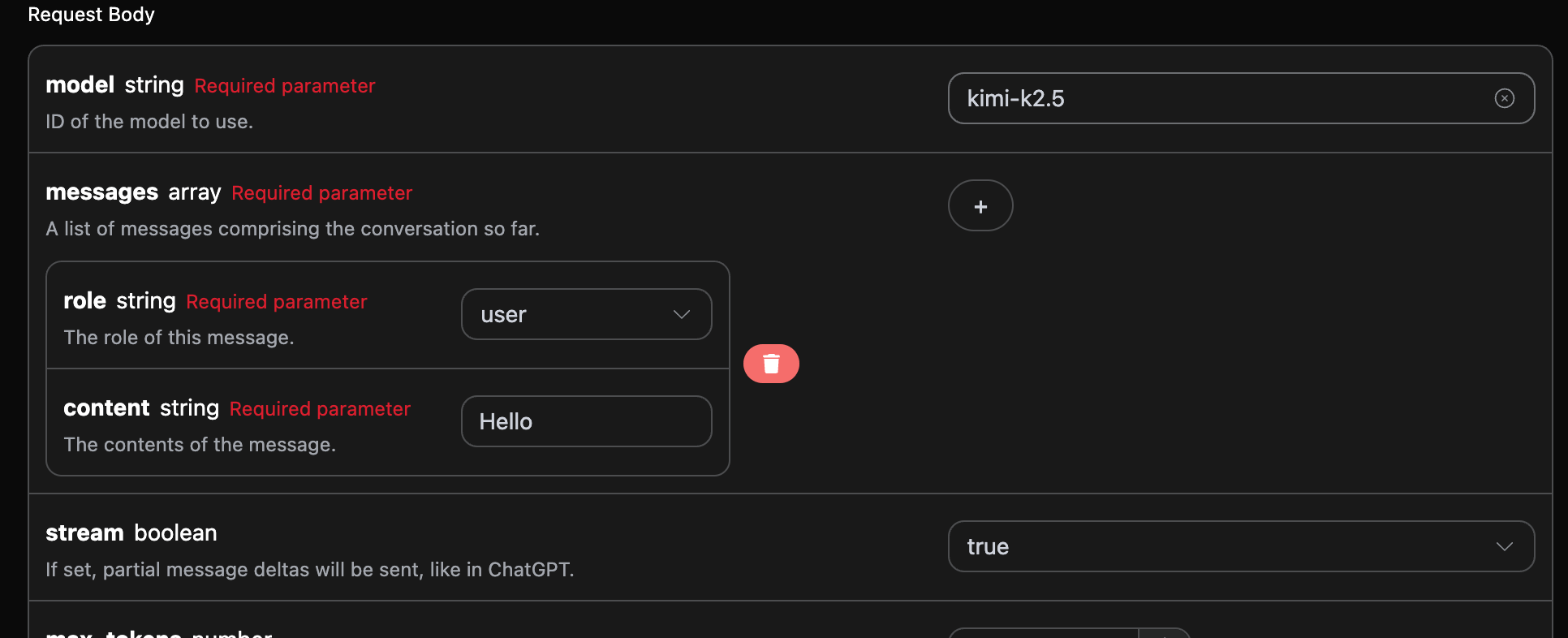
stream en true, l’API renverra les données JSON ligne par ligne, et au niveau du code, nous devons apporter les modifications nécessaires pour obtenir les résultats ligne par ligne.
Exemple de code d’appel en Python :
data, où data contient les choices, qui sont le contenu de la réponse la plus récente, conforme à ce qui a été présenté ci-dessus. choices est le contenu de réponse ajouté, que vous pouvez intégrer dans votre système. De plus, la fin de la réponse en streaming est déterminée par le contenu de data; si le contenu est [DONE], cela signifie que la réponse en streaming est entièrement terminée. Le résultat data retourné contient plusieurs champs, décrits comme suit :
id, l’ID généré pour cette tâche de conversation, utilisé pour identifier de manière unique cette tâche de conversation.model, le modèle choisi sur le site officiel de Kimi.choices, les informations de réponse fournies par Kimi en réponse aux questions.
Dialogue multi-tours
Si vous souhaitez intégrer la fonctionnalité de dialogue multi-tours, vous devez télécharger plusieurs questions dans le champmessages, des exemples spécifiques de plusieurs questions sont illustrés ci-dessous :
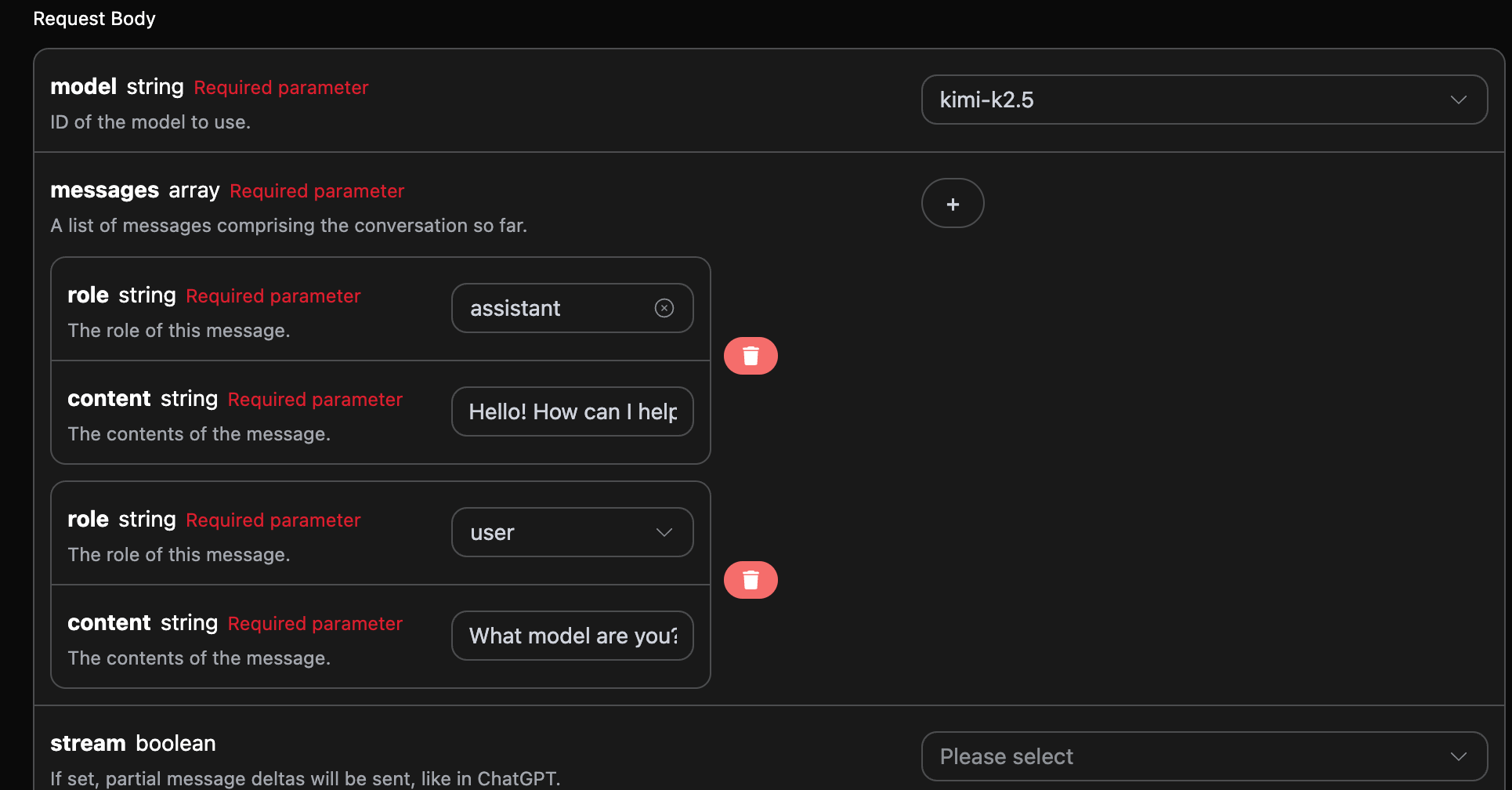
choices sont cohérentes avec le contenu de base utilisé, cela inclut le contenu de réponse de Kimi pour plusieurs dialogues, ce qui permet de répondre aux questions correspondantes en fonction de plusieurs contenus de dialogue.
Gestion des erreurs
Lors de l’appel de l’API, si une erreur se produit, l’API renverra le code d’erreur et les informations correspondantes. Par exemple :400 token_mismatched: Mauvaise requête, probablement en raison de paramètres manquants ou invalides.400 api_not_implemented: Mauvaise requête, probablement en raison de paramètres manquants ou invalides.401 invalid_token: Non autorisé, jeton d’autorisation invalide ou manquant.429 too_many_requests: Trop de requêtes, vous avez dépassé la limite de taux.500 api_error: Erreur interne du serveur, quelque chose s’est mal passé sur le serveur.
Exemple de réponse d’erreur
Conclusion
Grâce à ce document, vous avez compris comment utiliser l’API Kimi Chat Completion pour réaliser des conversations ordinaires, des réponses en streaming, des dialogues multi-tours, ainsi que contrôler l’intensité de raisonnement de K3 viareasoning_effort.