data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"content": "", "role": "assistant"}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"reasoning_content": "**Définir ma nature**\n\nMa réflexion a commencé. L'utilisateur veut connaître ma nature, posant une question directe \"que es-tu ?\" La première étape était simple : identifier la requête. Maintenant, je me rappelle de mon identité fondamentale : je suis un grand modèle de langage. C'est la vérité essentielle que je vise à transmettre.\n\n\n"}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"reasoning_content": "**Affiner ma réponse**\n\nJ'ai ajouté l'information cruciale que je suis formé par Google à l'identité de base \"grand modèle de langage\". Ma prochaine étape consiste à réfléchir à ce que signifie réellement être un \"grand modèle de langage\", afin que je puisse expliquer mes capacités fondamentales. Je me concentre sur la fourniture de contexte sans entrer dans des détails techniques spécifiques ou des noms de modèles. Je veux transmettre ma fonction d'une manière que l'utilisateur puisse facilement comprendre.\n\n\n"}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"reasoning_content": "**Confirmer l'identité fondamentale**\n\nJe suis maintenant en train de solidifier ma réponse. La question de l'utilisateur concernant mon affiliation au modèle nécessite une réponse ciblée. J'ai identifié que \"formé par Google\" est essentiel, fournissant un contexte clé. Je résiste à l'envie de mentionner des noms de modèles spécifiques, car ce n'est pas pertinent. L'objectif est de livrer une déclaration directe et précise. Mon but reste une réponse claire et concise, évitant le jargon technique et allant droit au but pertinent.\n\n\n"}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
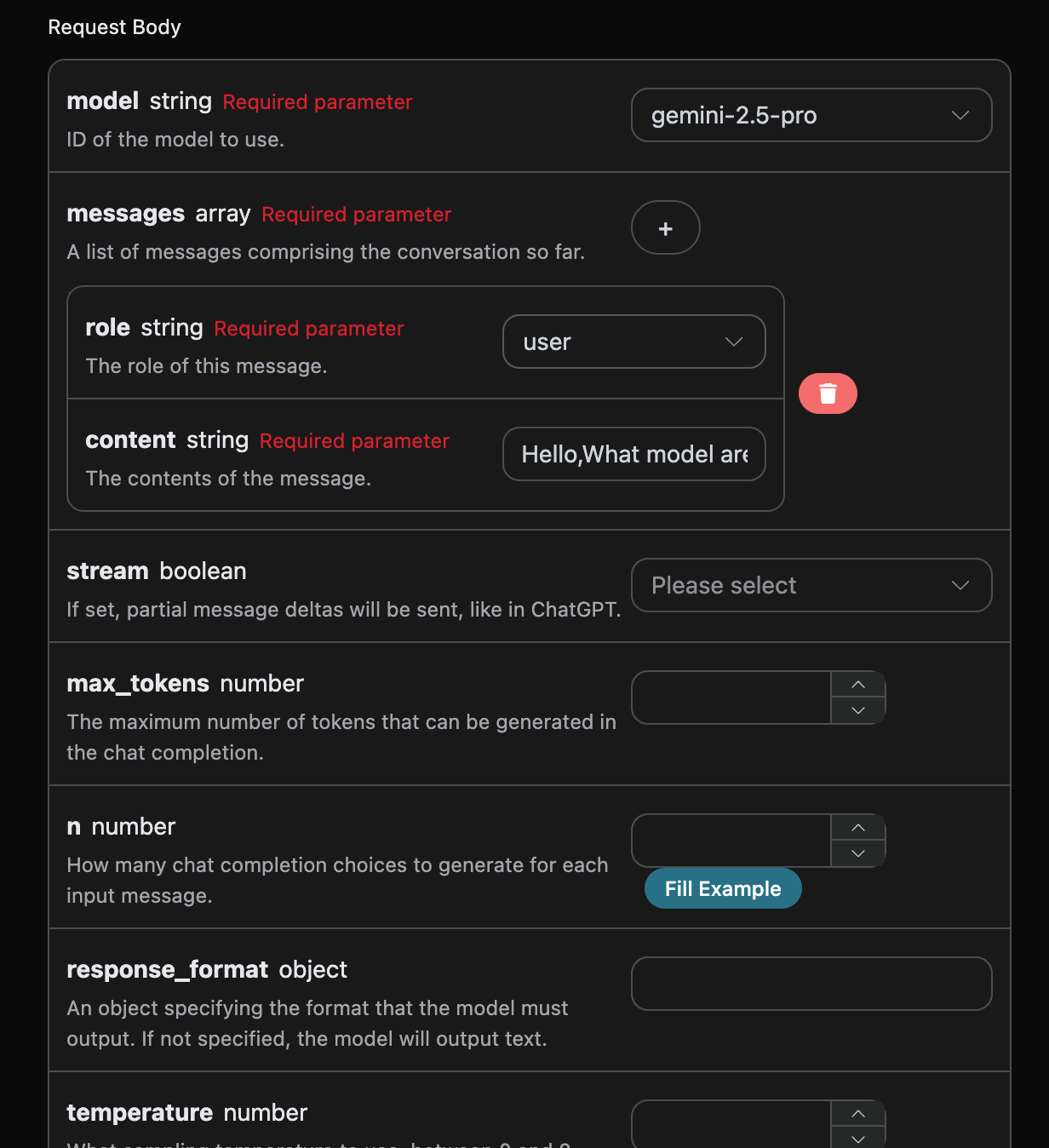
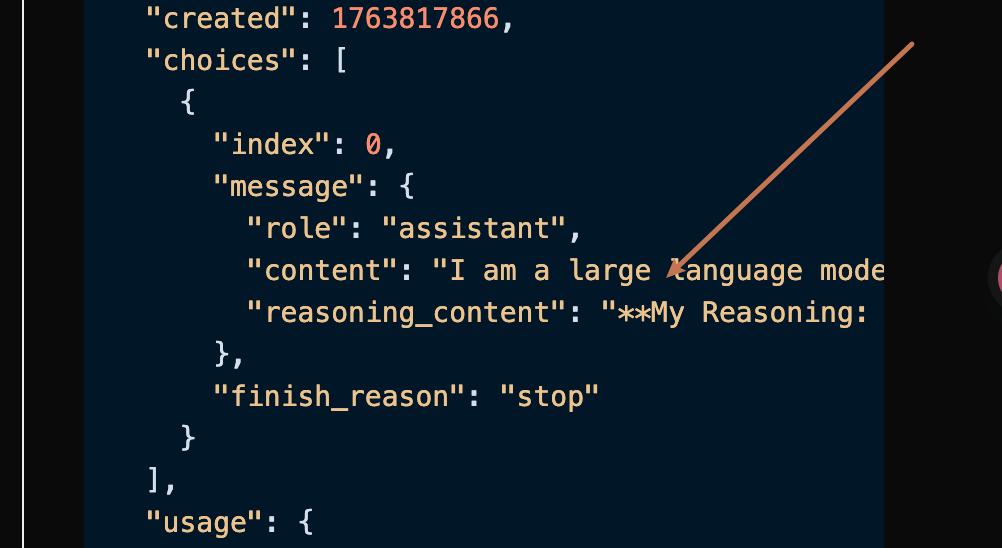
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"content": "Je suis un grand modèle de langage, formé par Google."}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {}, "logprobs": null, "finish_reason": "stop", "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": "", "choices": [], "usage": {"prompt_tokens": 8, "completion_tokens": 527, "total_tokens": 535, "prompt_tokens_details": {"cached_tokens": 0, "text_tokens": 8, "audio_tokens": 0, "image_tokens": 0}, "completion_tokens_details": {"text_tokens": 0, "audio_tokens": 0, "reasoning_tokens": 519}, "input_tokens": 0, "output_tokens": 0, "input_tokens_details": null, "claude_cache_creation_5_m_tokens": 0, "claude_cache_creation_1_h_tokens": 0}}
data: [DONE]
 Si vous n’êtes pas encore connecté ou inscrit, vous serez automatiquement redirigé vers la page de connexion pour vous inviter à vous inscrire et à vous connecter. Après vous être connecté ou inscrit, vous serez automatiquement renvoyé à la page actuelle.
Lors de la première demande, un quota gratuit sera offert, vous permettant d’utiliser cette API gratuitement.
Si vous n’êtes pas encore connecté ou inscrit, vous serez automatiquement redirigé vers la page de connexion pour vous inviter à vous inscrire et à vous connecter. Après vous être connecté ou inscrit, vous serez automatiquement renvoyé à la page actuelle.
Lors de la première demande, un quota gratuit sera offert, vous permettant d’utiliser cette API gratuitement.