Processus de demande
Pour utiliser l’API Midjourney Imagine, commencez par obtenir votre API Token sur le tableau de bord Ace Data Cloud pour le garder en réserve.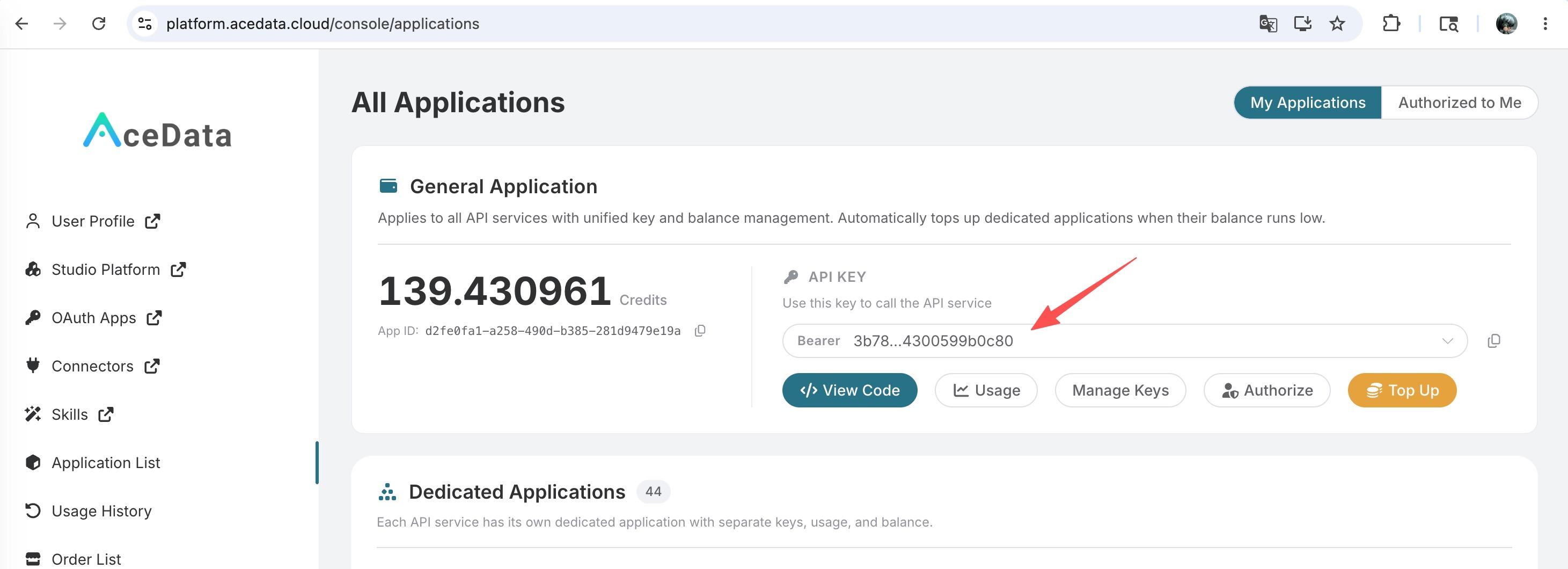 Si vous n’êtes pas encore connecté ou inscrit, vous serez automatiquement redirigé vers la page de connexion pour vous inviter à vous inscrire et à vous connecter, après quoi vous serez automatiquement renvoyé à la page actuelle.
Un seul API Token suffit pour appeler tous les services de la plateforme, sans avoir besoin de demander séparément pour chaque service. La première demande vous donnera un quota gratuit pour une expérience sans frais ; lorsque le quota est insuffisant, vous pouvez recharger le solde général dans le tableau de bord.
Si vous n’êtes pas encore connecté ou inscrit, vous serez automatiquement redirigé vers la page de connexion pour vous inviter à vous inscrire et à vous connecter, après quoi vous serez automatiquement renvoyé à la page actuelle.
Un seul API Token suffit pour appeler tous les services de la plateforme, sans avoir besoin de demander séparément pour chaque service. La première demande vous donnera un quota gratuit pour une expérience sans frais ; lorsque le quota est insuffisant, vous pouvez recharger le solde général dans le tableau de bord.
📘 Documentation complète : Midjourney Imagine API →
Utilisation de base
Ensuite, vous pouvez remplir le contenu correspondant sur l’interface, comme indiqué sur l’image :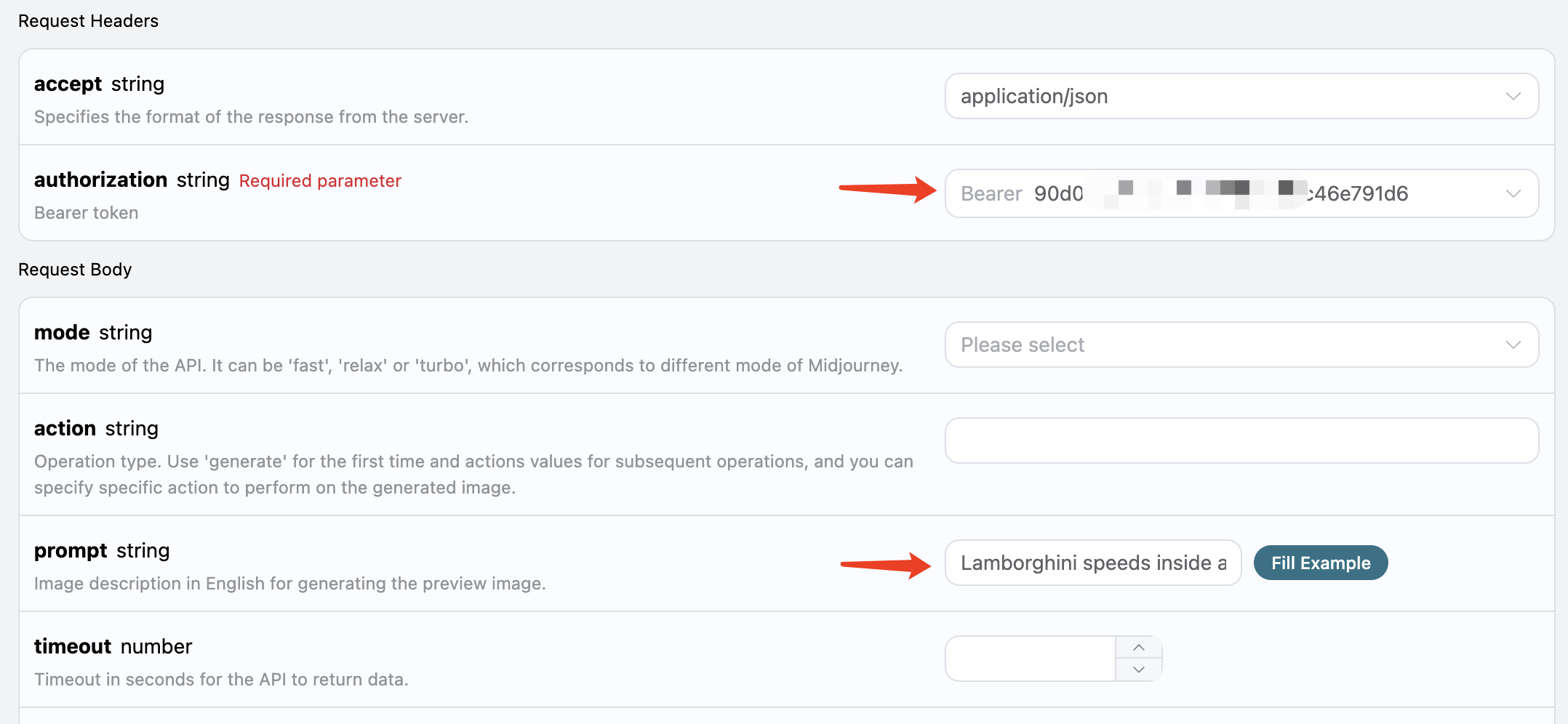 Lors de la première utilisation de cette interface, nous devons remplir au moins deux contenus, l’un est
Lors de la première utilisation de cette interface, nous devons remplir au moins deux contenus, l’un est authorization, que vous pouvez sélectionner directement dans la liste déroulante. L’autre paramètre est prompt, prompt est la description de l’image que nous souhaitons générer, il est conseillé de décrire en anglais, l’image sera plus précise et le résultat meilleur, ici nous avons utilisé le contenu d’exemple Lamborghini speeds inside a volcano, représentant un Lamborghini courant à l’intérieur d’un volcan.
Vous pouvez également remarquer qu’il y a un code d’appel correspondant généré à droite, vous pouvez copier le code pour l’exécuter directement, ou cliquer sur le bouton « Essayer » pour effectuer un test.
Paramètres de requête principaux :
prompt: mot de description de l’image (supporte la traduction automatique).mode: mode de génération, optionsfast/relax/turbo, par défaut fast. V8.1 ne supporte quefastetrelax.version: version du modèle. V8.1 utilise des résolutions SD/HD, ne supporte pas le paramètrequality; SD consomme environ 0,8 minute GPU, HD environ 1,3 minute GPU.timeout: temps d’attente (secondes), un dépassement de temps renverra directement.translation: si la traduction automatique des prompts non anglais est activée.split_images: si les résultats 2x2 doivent être renvoyés sous forme d’images individuelles.action/image_id: à spécifier lors de l’opération sur des images historiques.callback_url: adresse de rappel asynchrone.async: optionnel, si défini surtrue, l’interface renvoie immédiatementtask_id, sans avoir besoin de fournircallback_url, puis interrogez l’interface de requête de tâche correspondante pour obtenir les résultats.

task_id, l’ID de la tâche de génération de cette image, utilisé pour identifier de manière unique cette tâche de génération d’image.image_id, l’identifiant unique de l’image, nécessaire pour effectuer des opérations de transformation sur l’image lors de la prochaine fois.image_url, l’URL de la miniature, que vous pouvez ouvrir directement pour voir le résultat généré.image_width: largeur en pixels de la miniature.image_height: hauteur en pixels de la miniature.raw_image_url: l’URL de l’image originale, qui est identique au contenu de la miniature, mais plus haute définition, le temps de chargement sera un peu plus long.raw_image_width: largeur en pixels de l’image originale.raw_image_height: hauteur en pixels de l’image originale.actions, liste des opérations supplémentaires que vous pouvez effectuer sur l’image générée. Ici, il y a un total de 8, oùupscalereprésente l’agrandissement,variationreprésente la transformation. Ainsi,upscale1représente l’agrandissement de la première image en haut à gauche,variation3représente la transformation basée sur la troisième image en bas à gauche.
image_url ou raw_image_url, vous pouvez voir comme indiqué sur l’image.
 On peut voir qu’une image de prévisualisation 2x2 a été générée ici. Jusqu’à présent, le premier appel API est terminé.
On peut voir qu’une image de prévisualisation 2x2 a été générée ici. Jusqu’à présent, le premier appel API est terminé.
Agrandissement et transformation d’image
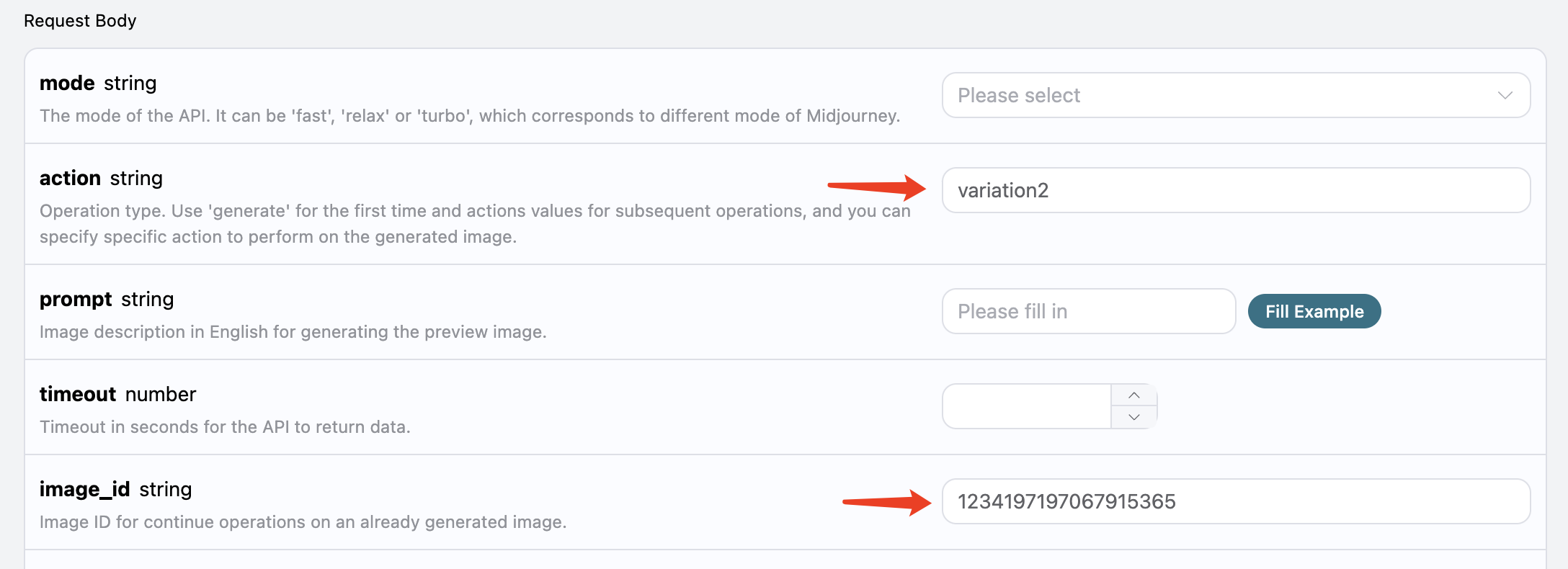
Ensuite, nous allons essayer d’effectuer des opérations supplémentaires sur la photo générée actuellement, par exemple, si nous pensons que la deuxième image en haut à droite est assez bonne, mais que nous souhaitons effectuer quelques ajustements, nous pouvons alors rempliraction avec variation2, tout en transmettant image_id :
 Le résultat obtenu est le suivant :
Le résultat obtenu est le suivant :
image_url, l’image nouvellement générée est comme suit :
 On peut voir qu’en ce qui concerne l’image en haut à droite, nous avons à nouveau obtenu quatre photos similaires.
À ce moment-là, nous pouvons choisir l’une d’elles pour effectuer une opération de mise à l’échelle plus précise, par exemple, si nous choisissons la quatrième, nous pouvons alors transmettre
On peut voir qu’en ce qui concerne l’image en haut à droite, nous avons à nouveau obtenu quatre photos similaires.
À ce moment-là, nous pouvons choisir l’une d’elles pour effectuer une opération de mise à l’échelle plus précise, par exemple, si nous choisissons la quatrième, nous pouvons alors transmettre action avec upscale4, en passant à nouveau l’ID de l’image actuelle via image_id.

Remarque : l’opérationLe résultat retourné est comme suit :upscaleprend moins de temps quevariationdans Midjourney.
image_url est comme montré ci-dessous :
 Ainsi, nous avons réussi à obtenir une photo de Lamborghini.
Il est également à noter que
Ainsi, nous avons réussi à obtenir une photo de Lamborghini.
Il est également à noter que actions contient plusieurs opérations possibles, décrites comme suit :
upscale_2x: agrandir l’image de 2 fois, obtenant une image haute définition 2 fois plus grande.upscale_4x: agrandir l’image de 4 fois, obtenant une image haute définition 4 fois plus grande.zoom_out_2x: réduire l’image de deux fois (remplissage des zones environnantes).zoom_out_1_5x: réduire l’image de 1,5 fois (remplissage des zones environnantes).pan_left: décaler l’image vers la gauche.pan_right: décaler l’image vers la droite.pan_up: décaler l’image vers le haut.pan_down: décaler l’image vers le bas.
Réécriture d’image (Image de base)
Cette API prend également en charge la réécriture d’image, communément appelée image de base. Nous pouvons entrer une URL d’image ainsi qu’un texte descriptif à réécrire, et cette API peut retourner l’image réécrite.Remarque : l’URL de l’image entrée doit être une image pure, ne peut pas être une image affichée dans une page web, sinon la réécriture d’image ne pourra pas être effectuée. Il est conseillé d’utiliser un hébergement d’images pour télécharger et obtenir l’URL de l’image.Par exemple, nous avons ici une image de coucher de soleil sur une route, avec quelques arbres et bâtiments à côté de la route, comme montré ci-dessous :
 Maintenant, nous voulons la modifier pour qu’elle soit à côté d’une plage, avec une voiture garée sur le bord de la route. Nous pouvons donc construire le prompt suivant :
Maintenant, nous voulons la modifier pour qu’elle soit à côté d’une plage, avec une voiture garée sur le bord de la route. Nous pouvons donc construire le prompt suivant :
—iw 2 pour ajuster le poids de l’image.
Nous pouvons transmettre le contenu ci-dessus comme un tout, dans le champ prompt, comme montré ci-dessous :
 Le résultat de sortie est comme suit :
Le résultat de sortie est comme suit :
 On peut voir que, tout en maintenant le style et la composition globaux de l’image d’origine, la scène entière est devenue à côté de la plage, tandis qu’une voiture est également apparue sur la route, c’est ce qu’on appelle le Prompt avec Image.
On peut voir que, tout en maintenant le style et la composition globaux de l’image d’origine, la scène entière est devenue à côté de la plage, tandis qu’une voiture est également apparue sur la route, c’est ce qu’on appelle le Prompt avec Image.
Fusion d’images
Cette API prend également en charge la fusion d’images, nous pouvons transmettre plusieurs images pour réaliser différents effets de fusion d’images. Par exemple, ici nous avons deux images, l’une est un ours en peluche, l’autre est une tronçonneuse, comme indiqué ci-dessous :

prompt, le résultat est le suivant :
 On peut voir que nous avons réussi à réaliser la fusion d’images.
On peut voir que nous avons réussi à réaliser la fusion d’images.
Remarque : La fusion d’images peut prendre en charge jusqu’à 5 URL d’images en entrée, c’est-à-dire qu’elle prend en charge la fusion de jusqu’à 5 images, le format d’entrée est le même que ci-dessus.
Transformation locale
Cette API prend également en charge la fonction de dessin local d’images, mais ne prend en charge que la génération d’images sous le contenu mentionné ci-dessus, nous pouvons transmettre l’ID unique d’une image générée, le paramètre d’action de redessin localaction ainsi que le masque de la zone à redessiner pour réaliser le redessin dans la zone de ce masque.
Par exemple, ici nous avons une image générée d’un chat :


Remarque : Le code Python ci-dessus décrit le processus de génération du masque. Si vous souhaitez l’intégrer à votre produit, veuillez écrire le code correspondant dans le langage de votre choix en fonction de son principe.Avec le code ci-dessus, nous avons obtenu le masque à redessiner. Ensuite, nous devons définir le paramètre
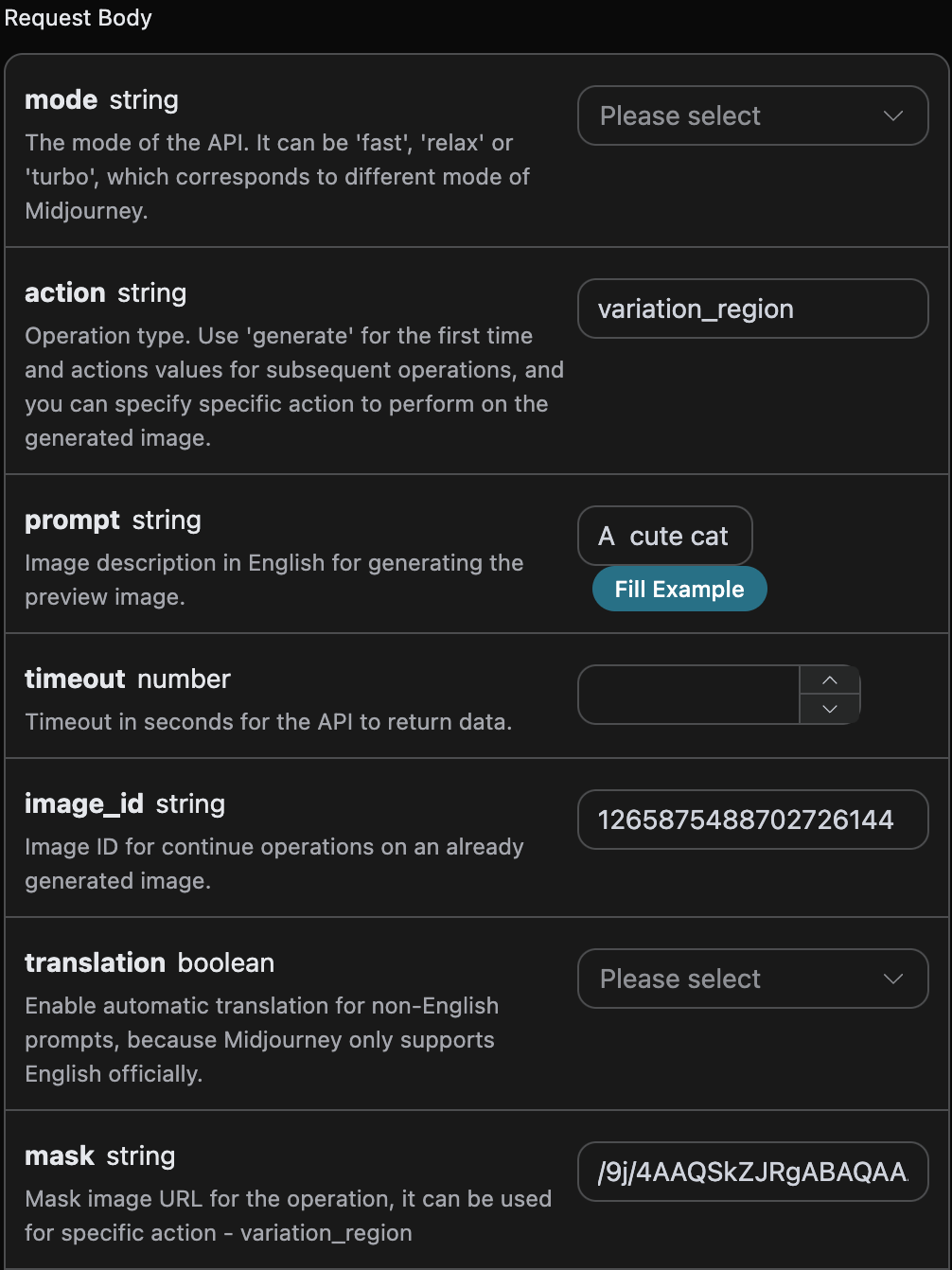
action sur variation_region, générer l’ID de l’image image_id (pour obtenir ce paramètre, référez-vous au contenu ci-dessus), et passer le masque correspondant mask. Les autres informations de paramètre sont les suivantes :
action: le comportement d’opération sur l’image, icivariation_region, indiquant un redessin partiel de l’image.prompt: le terme descriptif pour le redessin partiel de l’image (paramètre optionnel).image_id: l’identifiant unique de l’image, facilitant le redessin partiel de l’image.mask: l’encodage base64 de la zone de masque correspondante à l’image (l’image est celle spécifiée par l’image_idci-dessus).
prompt est un paramètre non obligatoire, ici pour faciliter la comparaison, le prompt de la zone de masque est défini sur Un chat mignon, les paramètres sont configurés comme indiqué ci-dessous :
Exemple de code
On peut constater que, sur le côté droit de la page, divers langages de code ont déjà été générés automatiquement, comme le montre l’image :
Exemple de réponse
Après un succès de la requête, l’API renverra des informations sur le résultat de l’image de fond d’échange. Par exemple :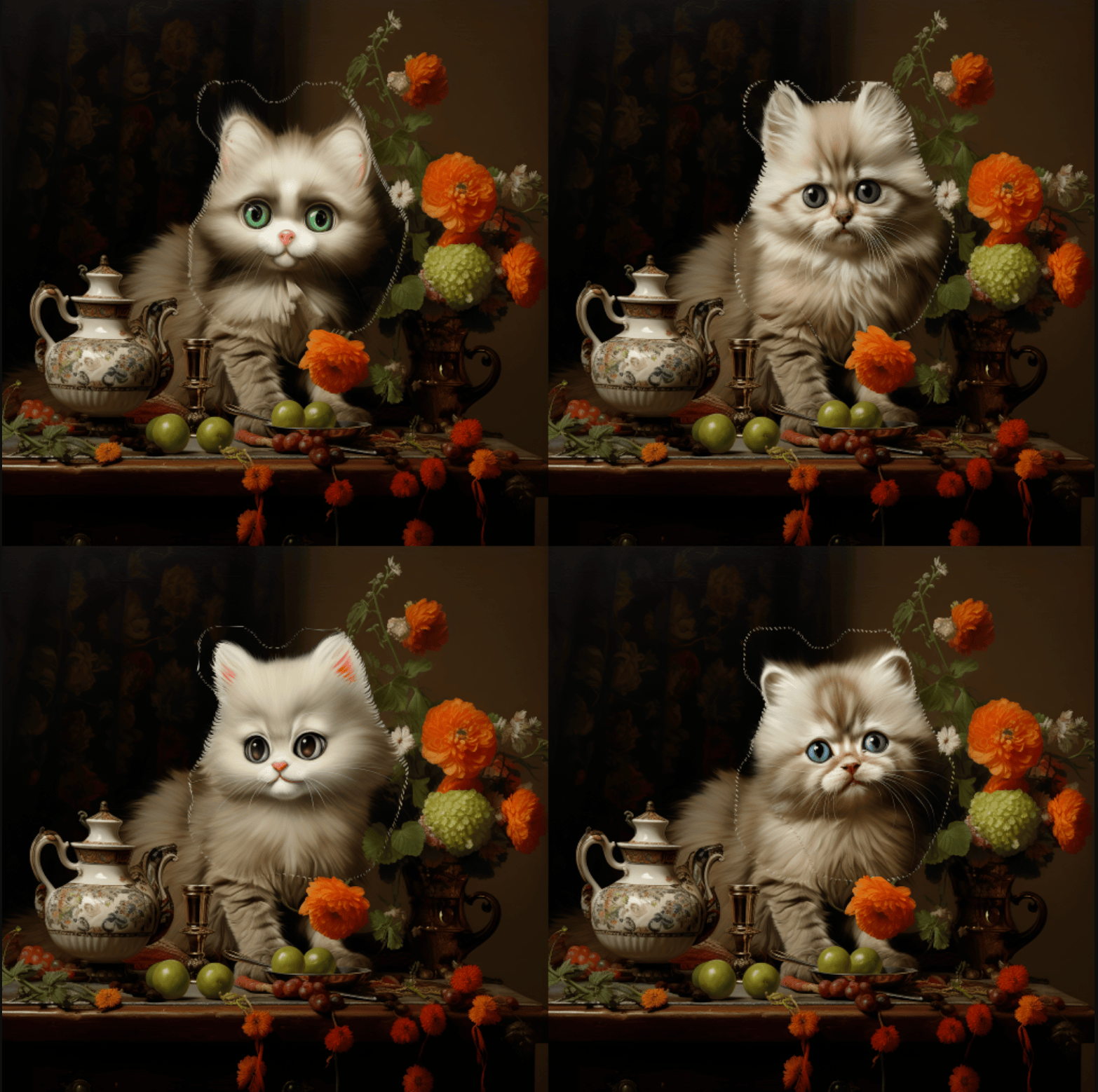 Nous avons réussi à réaliser un redessin partiel de la zone personnalisée de l’image générée.
Nous avons réussi à réaliser un redessin partiel de la zone personnalisée de l’image générée.
CURL
Callback asynchrone
Étant donné que la génération d’images par Midjourney nécessite d’attendre un certain temps, cette API est également conçue par défaut pour un mode d’attente prolongée. Cependant, dans certains scénarios, une attente prolongée peut entraîner des coûts supplémentaires en ressources, c’est pourquoi cette API propose également un moyen de rappel Webhook asynchrone. Lorsque la génération d’images réussit ou échoue, son résultat est envoyé via une requête HTTP à l’URL de rappel Webhook spécifiée. Une fois que l’URL de rappel reçoit le résultat, elle peut procéder à un traitement supplémentaire. Voici une démonstration du processus d’appel spécifique. Tout d’abord, le rappel Webhook est un service capable de recevoir des requêtes HTTP, les développeurs doivent le remplacer par l’URL de leur propre serveur HTTP. Pour des raisons de démonstration, nous utilisons un site Web de modèle Webhook public https://webhook.site/, en ouvrant ce site, vous obtiendrez une URL Webhook, comme illustré ci-dessous : Copiez cette URL, vous pouvez l’utiliser comme Webhook, l’exemple ici est https://webhook.site/995d0a91-d737-40a7-a3b9-5baf68ed924c.
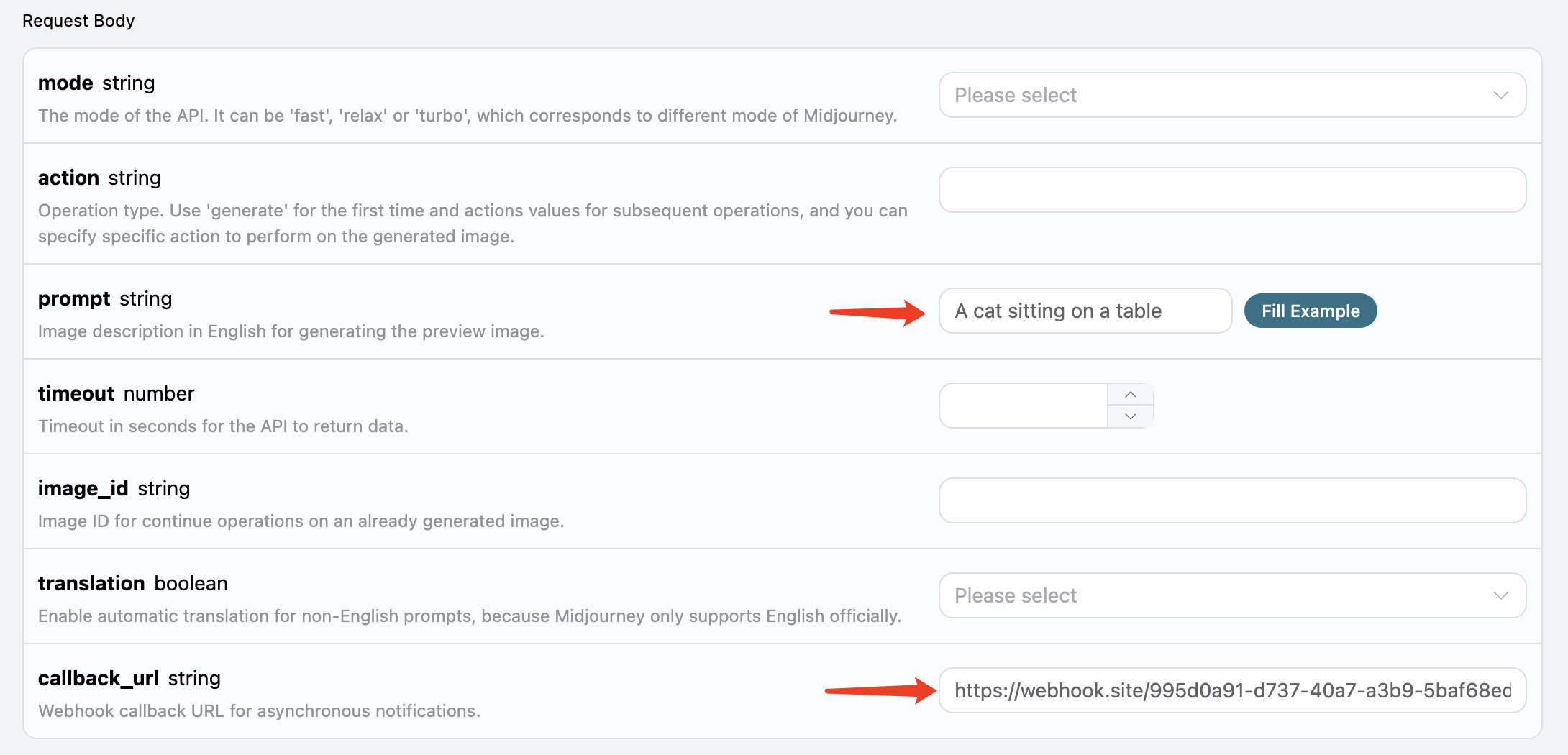
Ensuite, nous pouvons définir le champ
Copiez cette URL, vous pouvez l’utiliser comme Webhook, l’exemple ici est https://webhook.site/995d0a91-d737-40a7-a3b9-5baf68ed924c.
Ensuite, nous pouvons définir le champ callback_url sur l’URL Webhook ci-dessus, tout en remplissant prompt, comme illustré ci-dessous :
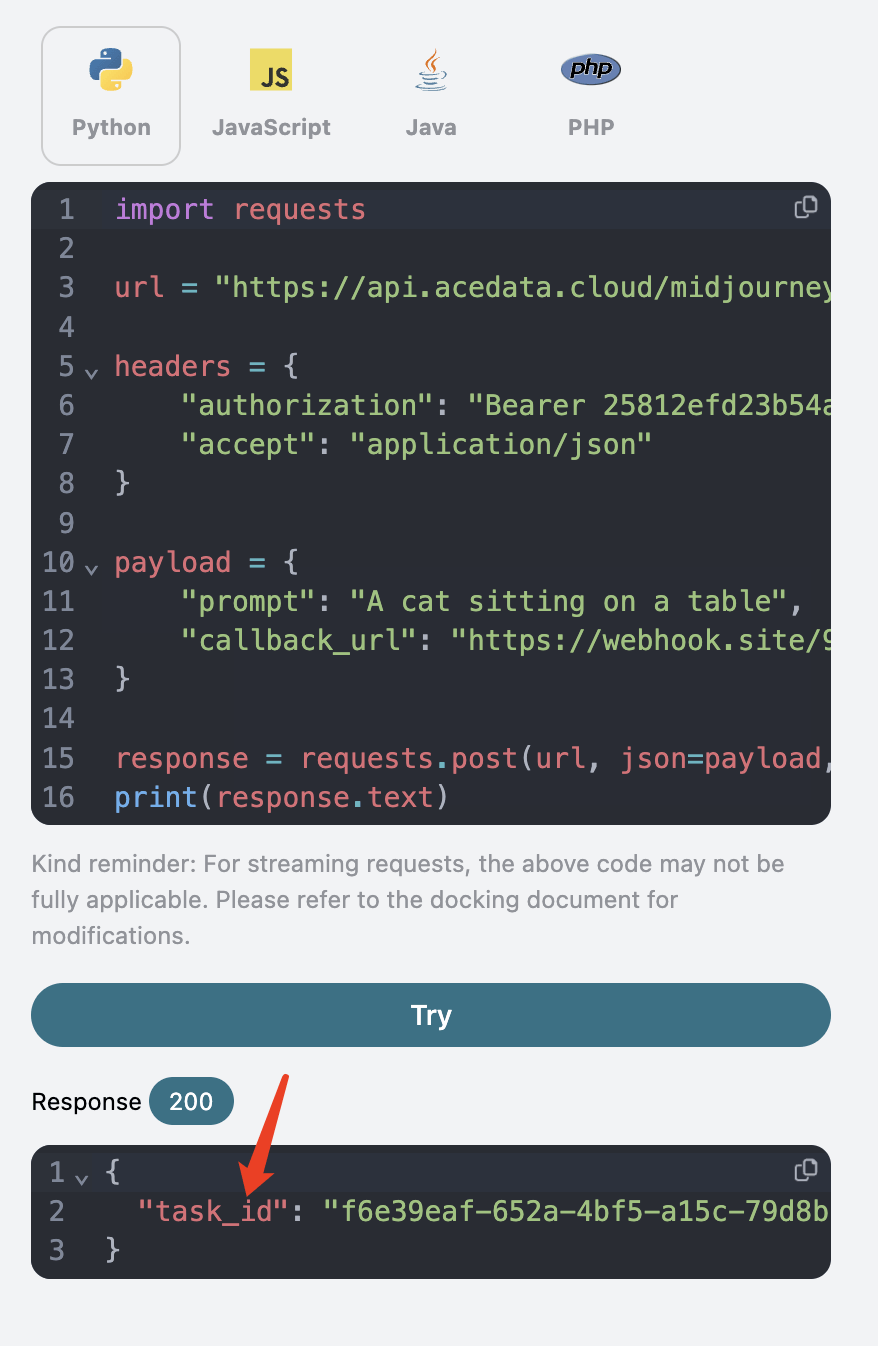
 Après avoir cliqué sur tester, vous recevrez immédiatement une réponse
Après avoir cliqué sur tester, vous recevrez immédiatement une réponse task_id, qui sert à identifier l’ID de la tâche de génération actuelle, comme illustré ci-dessous :
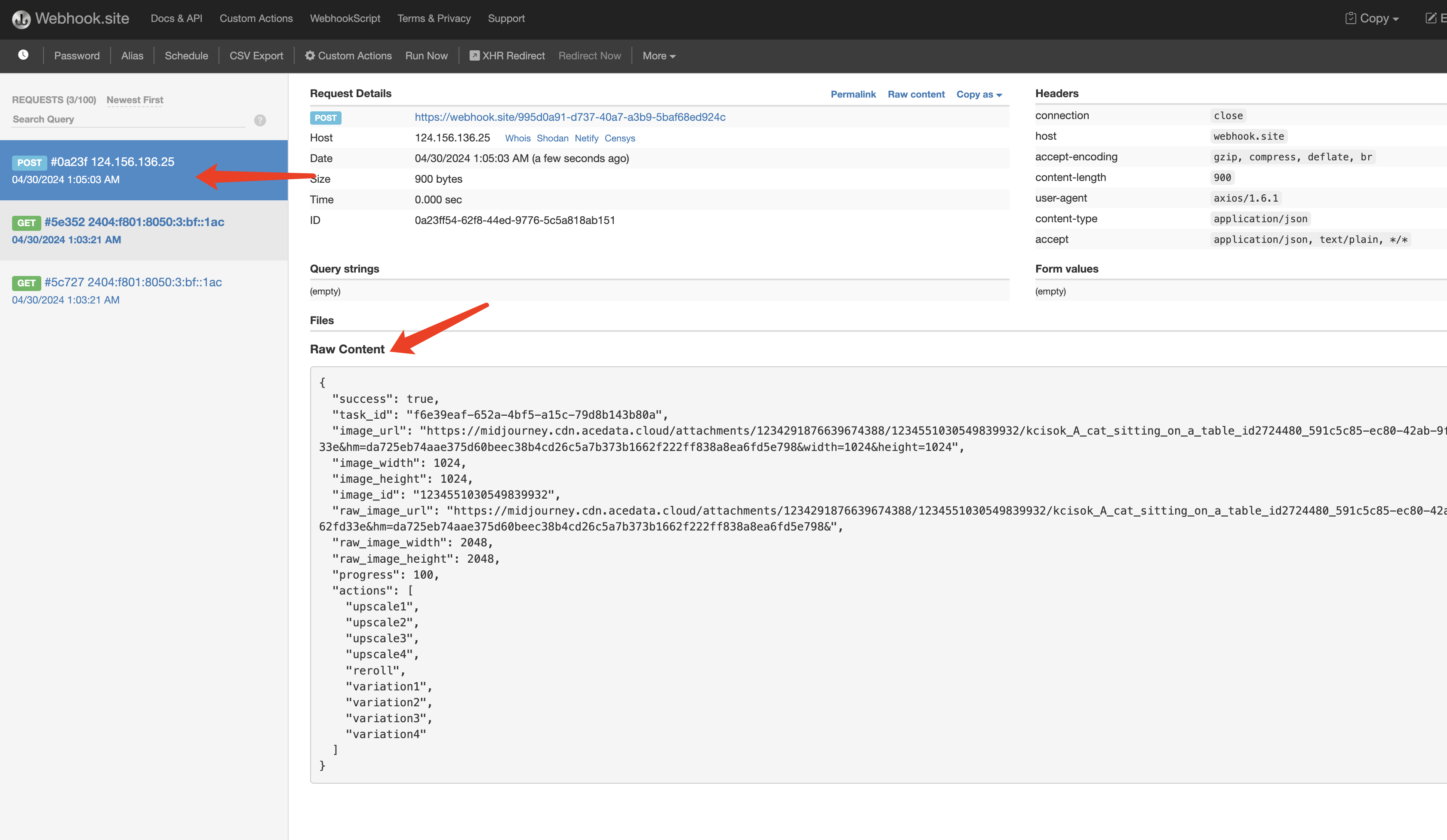 Le résultat est celui de la tâche actuelle, le contenu est le suivant :
Le résultat est celui de la tâche actuelle, le contenu est le suivant :
success indique si la tâche a été exécutée avec succès. Si elle a été exécutée avec succès, il y aura également les mêmes champs actions, image_id, image_url, et le résultat de retour est identique à celui décrit ci-dessus, en plus du task_id utilisé pour identifier la tâche, afin de relier le résultat du Webhook à la demande API initiale.
Si la génération d’images échoue, l’URL Webhook recevra un contenu similaire à celui-ci :
success sera false, et il y aura également les champs error.code et error.message décrivant les détails de l’erreur de la tâche, le serveur Webhook peut traiter en fonction des résultats correspondants.
Sortie en continu
Midjourney a un progrès lors de la génération d’images, au début, il s’agit d’une photo floue, puis après plusieurs itérations, l’image devient progressivement claire, et enfin, une image complète est obtenue. Ainsi, le processus de génération d’une image peut être divisé en trois étapes : « Envoi de la commande » -> « Début de la génération d’images (plusieurs itérations progressivement claires) » -> « Génération d’images terminée ». Sans sortie en continu activée, cette API, depuis l’envoi de la demande jusqu’au retour du résultat, couvre en réalité tout le processus de « Envoi de la commande » -> « Génération d’images terminée », le processus de génération d’images est également inclus, et comme Midjourney lui-même génère des images lentement, l’ensemble du processus nécessite environ une minute ou plus. Ainsi, pour une meilleure expérience utilisateur, cette API prend en charge la sortie en continu, c’est-à-dire qu’au moment où « la génération d’images commence », elle commence à renvoyer des résultats, chaque fois que le progrès du dessin change, les résultats seront diffusés jusqu’à la fin de la génération d’images. Si vous souhaitez renvoyer des réponses en continu, vous pouvez modifier le paramètreaccept dans l’en-tête de la requête, en le changeant en application/x-ndjson, mais le code d’appel doit également être modifié pour prendre en charge la réponse en continu.
Exemple de code Python :
Remarque : lorsque la génération n’est pas complètement terminée, le champ actions est vide, ce qui signifie qu’aucune opération de traitement supplémentaire ne peut être effectuée sur l’image intermédiaire. Une fois la génération terminée, l’URL de l’image générée pendant le processus sera détruite.
De plus, vous pouvez combiner les résultats en continu avec un rappel asynchrone en spécifiant l’en-tête accept=application/x-ndjson et le corps de la requête callback_url, puis callback_url peut recevoir plusieurs requêtes POST de résultats en continu.