Antragsprozess
Um die OpenAI Embeddings API zu nutzen, können Sie zunächst auf die Seite OpenAI Embeddings API gehen und auf die Schaltfläche „Acquire“ klicken, um die erforderlichen Anmeldeinformationen zu erhalten: Wenn Sie noch nicht angemeldet oder registriert sind, werden Sie automatisch zur Anmeldeseite weitergeleitet, die Sie zur Registrierung und Anmeldung einlädt. Nach der Anmeldung werden Sie automatisch zur aktuellen Seite zurückgeleitet.
Bei der ersten Antragstellung gibt es ein kostenloses Kontingent, mit dem Sie die API kostenlos nutzen können.
Wenn Sie noch nicht angemeldet oder registriert sind, werden Sie automatisch zur Anmeldeseite weitergeleitet, die Sie zur Registrierung und Anmeldung einlädt. Nach der Anmeldung werden Sie automatisch zur aktuellen Seite zurückgeleitet.
Bei der ersten Antragstellung gibt es ein kostenloses Kontingent, mit dem Sie die API kostenlos nutzen können.
Grundlegende Nutzung
Als Nächstes können Sie die entsprechenden Inhalte im Interface ausfüllen, wie im Bild gezeigt: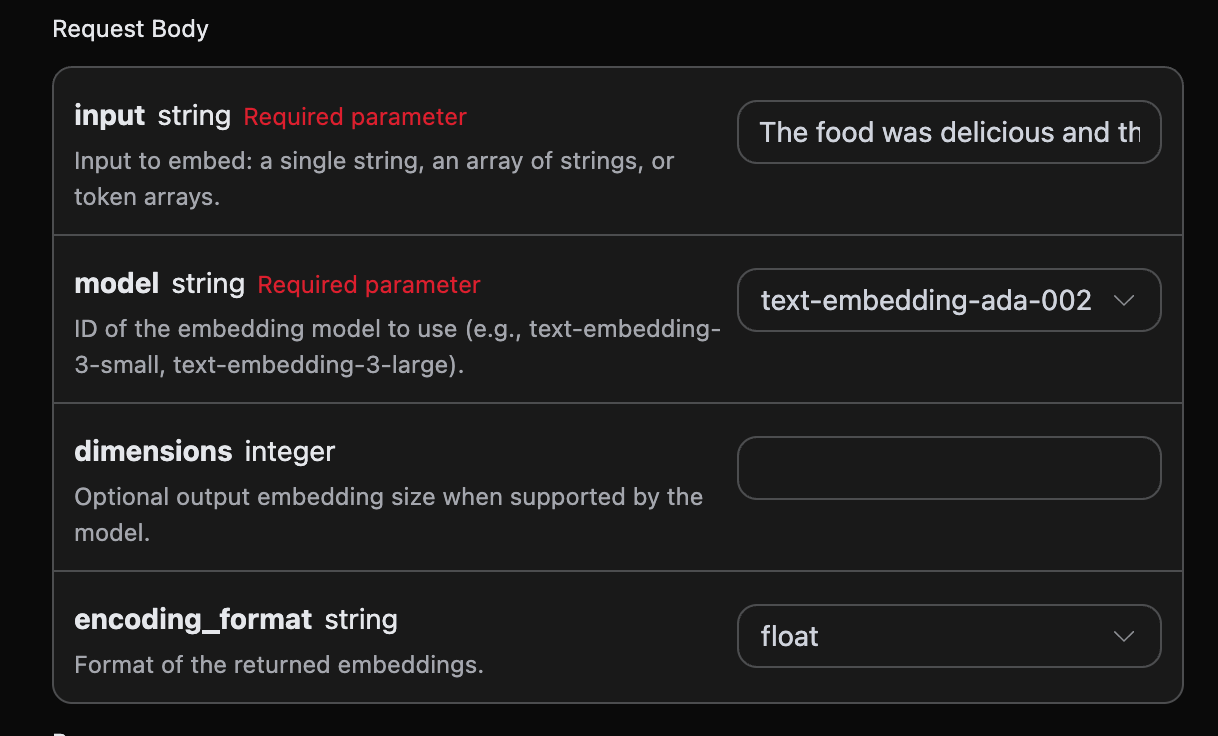
authorization, den Sie einfach aus der Dropdown-Liste auswählen können. Ein weiterer Parameter ist model, model ist die Modellkategorie, die wir von der OpenAI-Website auswählen. Hier haben wir hauptsächlich 3 Modelle, die Details können Sie in den von uns bereitgestellten Modellen einsehen. Der letzte Parameter ist input, input ist der Text, den wir in einen Wortvektor umwandeln möchten.
Gleichzeitig können Sie auf der rechten Seite den entsprechenden Code zur Aufrufgenerierung sehen, den Sie kopieren und direkt ausführen oder einfach auf die Schaltfläche „Try“ klicken können, um einen Test durchzuführen.
Optionale Parameter:
dimensions: Zuschneiden der Vektordimensionen, standardmäßig wird die vollständige Dimension ausgegeben.encoding_format: Rückgabeformat, wahlweisefloatoderbase64.
model, das Modell, das für die Umwandlung des Textes in einen Wortvektor verwendet wurde.usage, die Token-Informationen, die für die Umwandlung des Textes in einen Wortvektor verwendet wurden.data, das Ergebnis des umgewandelten Wortvektors.
data die spezifischen Informationen über den entsprechenden Wortvektor des Textes, wobei embedding das generierte Ergebnis des Wortvektors ist.
Fehlerbehandlung
Wenn beim Aufruf der API ein Fehler auftritt, gibt die API den entsprechenden Fehlercode und die Informationen zurück. Zum Beispiel:400 token_mismatched: Ungültige Anfrage, möglicherweise aufgrund fehlender oder ungültiger Parameter.400 api_not_implemented: Ungültige Anfrage, möglicherweise aufgrund fehlender oder ungültiger Parameter.401 invalid_token: Unbefugt, ungültiger oder fehlender Autorisierungstoken.429 too_many_requests: Zu viele Anfragen, Sie haben das Rate-Limit überschritten.500 api_error: Interner Serverfehler, etwas ist auf dem Server schiefgelaufen.