Ansökningsprocess
För att använda OpenAI Embeddings API kan du först gå till OpenAI Embeddings API sidan och klicka på “Acquire”-knappen för att få de nödvändiga autentiseringsuppgifterna: Om du inte har loggat in eller registrerat dig kommer du automatiskt att omdirigeras till inloggningssidan där du blir inbjuden att registrera dig och logga in. Efter inloggning eller registrering kommer du automatiskt att återvända till den aktuella sidan.
Vid första ansökan kommer det att finnas en gratis kvot som kan användas för att gratis använda API:et.
Om du inte har loggat in eller registrerat dig kommer du automatiskt att omdirigeras till inloggningssidan där du blir inbjuden att registrera dig och logga in. Efter inloggning eller registrering kommer du automatiskt att återvända till den aktuella sidan.
Vid första ansökan kommer det att finnas en gratis kvot som kan användas för att gratis använda API:et.
Grundläggande Användning
Därefter kan du fylla i motsvarande innehåll på gränssnittet, som visas i bilden: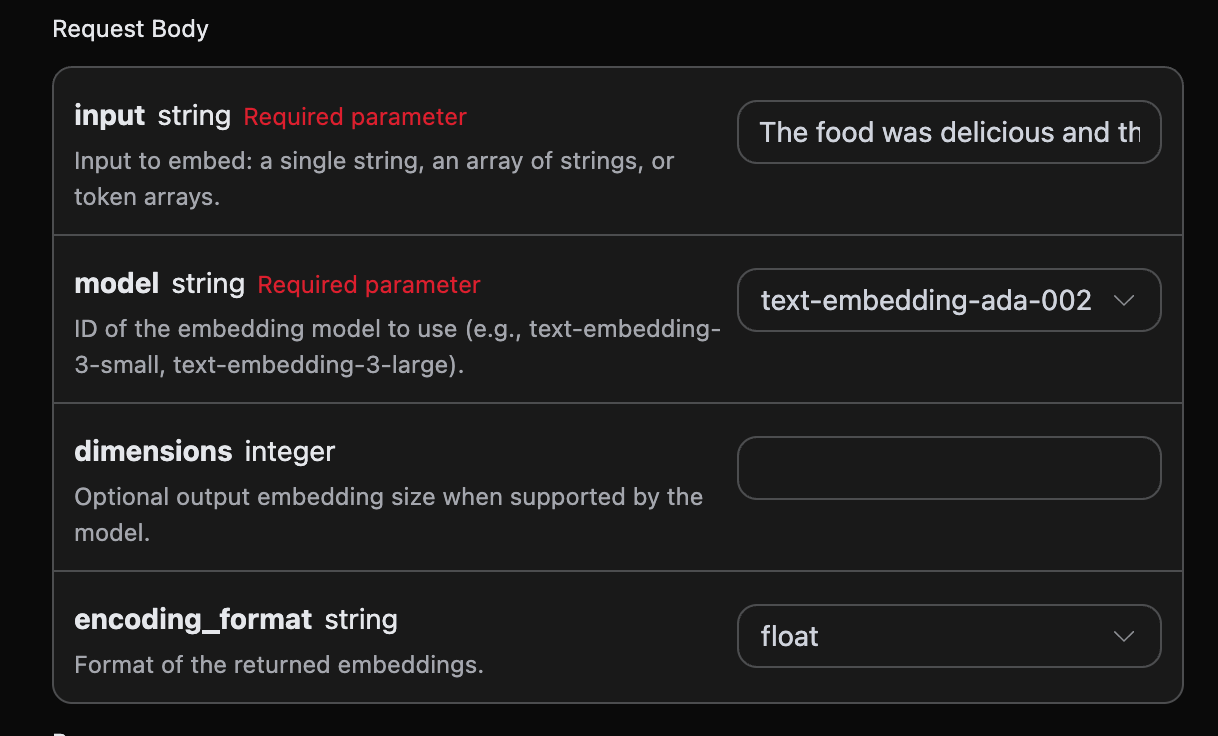
authorization, som du direkt väljer från rullgardinsmenyn. Den andra parametern är model, model är den vi väljer att använda från OpenAI:s officiella modellkategorier, här har vi huvudsakligen 3 modeller, detaljer kan ses i de modeller vi tillhandahåller. Den sista parametern är input, input är den text som vi behöver konvertera till en ordvektor.
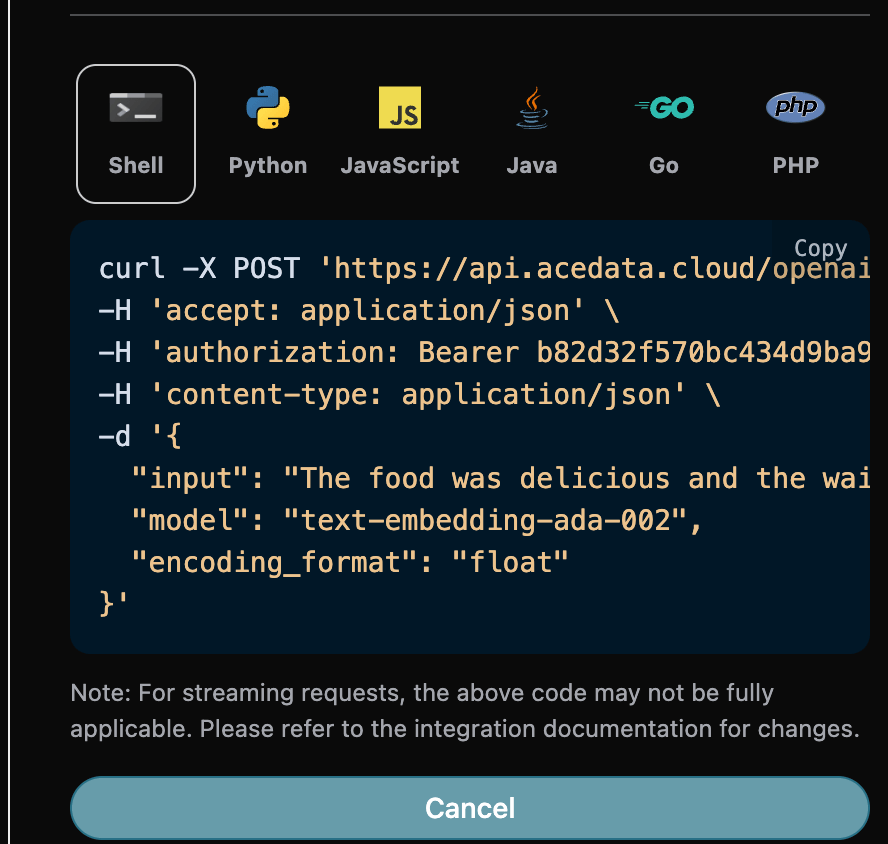
Samtidigt kan du notera att det finns motsvarande kod för anrop på höger sida, du kan kopiera koden och köra den direkt, eller klicka på “Try”-knappen för att testa.
Valfria parametrar:
dimensions: Beskär vektorens dimensioner, standardutgången är full dimension.encoding_format: Återvändande format, valfrittfloatellerbase64.
model, modellen som användes för att konvertera text till ordvektor.usage, tokeninformation som användes för att konvertera text till ordvektor.data, resultatet av textens konvertering till ordvektor.
data innehåller den specifika informationen om ordvektorn som motsvarar texten, där embedding är det genererade ordvektorns specifika resultat.
Felhantering
Vid anrop av API:et, om ett fel uppstår, kommer API:et att returnera motsvarande felkod och information. Till exempel:400 token_mismatched: Felaktig begäran, möjligtvis på grund av saknade eller ogiltiga parametrar.400 api_not_implemented: Felaktig begäran, möjligtvis på grund av saknade eller ogiltiga parametrar.401 invalid_token: Obefogad, ogiltig eller saknad autentiseringstoken.429 too_many_requests: För många begärningar, du har överskridit hastighetsgränsen.500 api_error: Intern serverfel, något gick fel på servern.