신청 프로세스
OpenAI Embeddings API를 사용하려면 먼저 OpenAI Embeddings API 페이지에서 “Acquire” 버튼을 클릭하여 요청에 필요한 자격 증명을 얻습니다: 로그인 또는 등록이 되어 있지 않은 경우 자동으로 로그인 페이지로 리디렉션되어 등록 및 로그인을 초대합니다. 로그인 및 등록 후에는 자동으로 현재 페이지로 돌아옵니다.
첫 번째 신청 시 무료 크레딧이 제공되며, 이 API를 무료로 사용할 수 있습니다.
로그인 또는 등록이 되어 있지 않은 경우 자동으로 로그인 페이지로 리디렉션되어 등록 및 로그인을 초대합니다. 로그인 및 등록 후에는 자동으로 현재 페이지로 돌아옵니다.
첫 번째 신청 시 무료 크레딧이 제공되며, 이 API를 무료로 사용할 수 있습니다.
기본 사용
다음으로 인터페이스에 해당 내용을 입력할 수 있습니다. 아래 그림과 같이: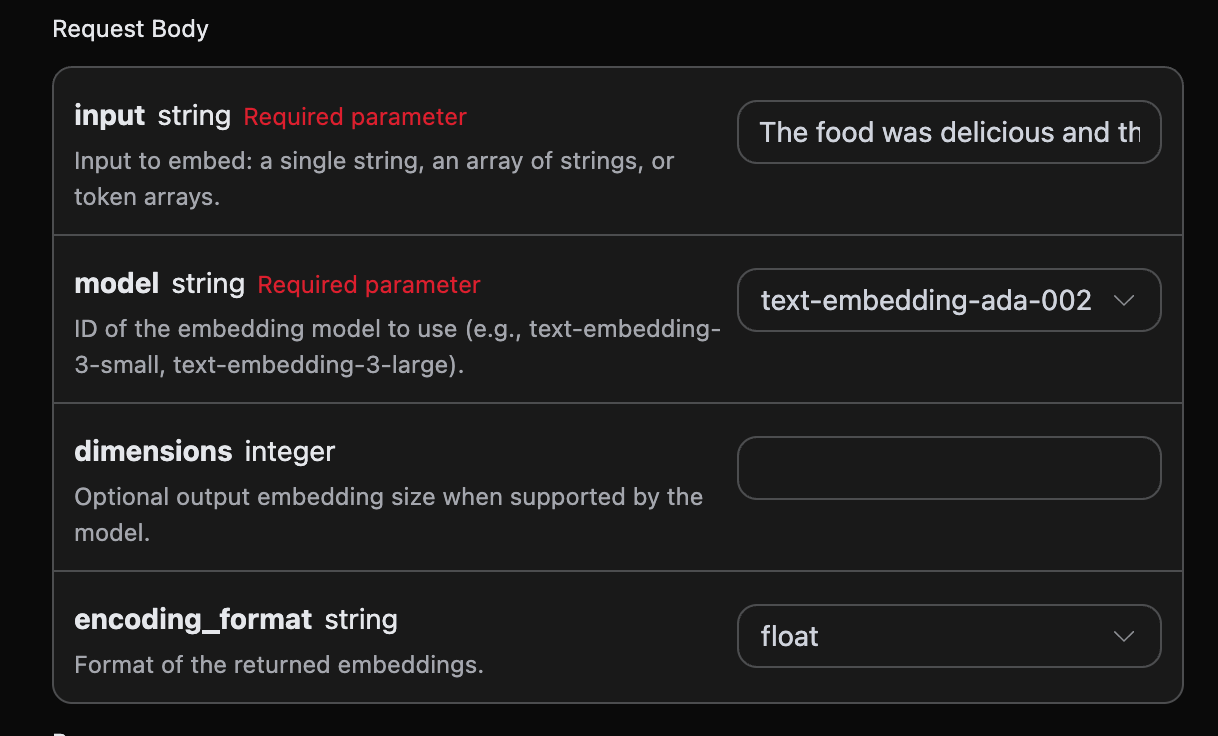
authorization으로, 드롭다운 목록에서 선택하면 됩니다. 다른 매개변수는 model이며, model은 OpenAI 공식 모델 카테고리를 선택하는 것입니다. 여기에는 주로 3가지 모델이 있으며, 자세한 내용은 제공된 모델을 참조할 수 있습니다. 마지막 매개변수는 input으로, input은 변환할 단어 벡터 텍스트입니다.
또한 오른쪽에 해당 호출 코드 생성이 있으며, 코드를 복사하여 직접 실행할 수도 있고, “Try” 버튼을 클릭하여 테스트할 수도 있습니다.
선택적 매개변수:
dimensions: 벡터 차원 자르기, 기본적으로 전체 차원을 출력합니다.encoding_format: 반환 형식, 선택 사항으로float또는base64가 있습니다.
model, 이번 텍스트를 단어 벡터로 변환하는 데 사용된 모델입니다.usage, 이번 텍스트를 단어 벡터로 변환하는 데 사용된 토큰 정보입니다.data, 텍스트 변환 후의 단어 벡터 결과입니다.
data는 텍스트에 해당하는 단어 벡터의 구체적인 정보를 포함하고 있으며, 그 안의 embedding은 생성된 단어 벡터의 구체적인 결과입니다.
오류 처리
API를 호출할 때 오류가 발생하면 API는 해당 오류 코드와 정보를 반환합니다. 예를 들어:400 token_mismatched: 잘못된 요청, 누락되었거나 잘못된 매개변수 때문일 수 있습니다.400 api_not_implemented: 잘못된 요청, 누락되었거나 잘못된 매개변수 때문일 수 있습니다.401 invalid_token: 권한 없음, 잘못되었거나 누락된 인증 토큰입니다.429 too_many_requests: 너무 많은 요청, 비율 한도를 초과했습니다.500 api_error: 내부 서버 오류, 서버에서 문제가 발생했습니다.