申请流程
Aby korzystać z OpenAI Embeddings API, najpierw można przejść na stronę OpenAI Embeddings API i kliknąć przycisk „Acquire”, aby uzyskać potrzebne poświadczenia: Jeśli nie jesteś zalogowany lub zarejestrowany, automatycznie zostaniesz przekierowany na stronę logowania, aby zarejestrować się i zalogować, a po zalogowaniu zostaniesz automatycznie przekierowany z powrotem na bieżącą stronę.
Podczas pierwszej aplikacji otrzymasz darmowy limit, który pozwala na bezpłatne korzystanie z tego API.
Jeśli nie jesteś zalogowany lub zarejestrowany, automatycznie zostaniesz przekierowany na stronę logowania, aby zarejestrować się i zalogować, a po zalogowaniu zostaniesz automatycznie przekierowany z powrotem na bieżącą stronę.
Podczas pierwszej aplikacji otrzymasz darmowy limit, który pozwala na bezpłatne korzystanie z tego API.
基本使用
Następnie możesz wypełnić odpowiednie pola na interfejsie, jak pokazano na obrazku: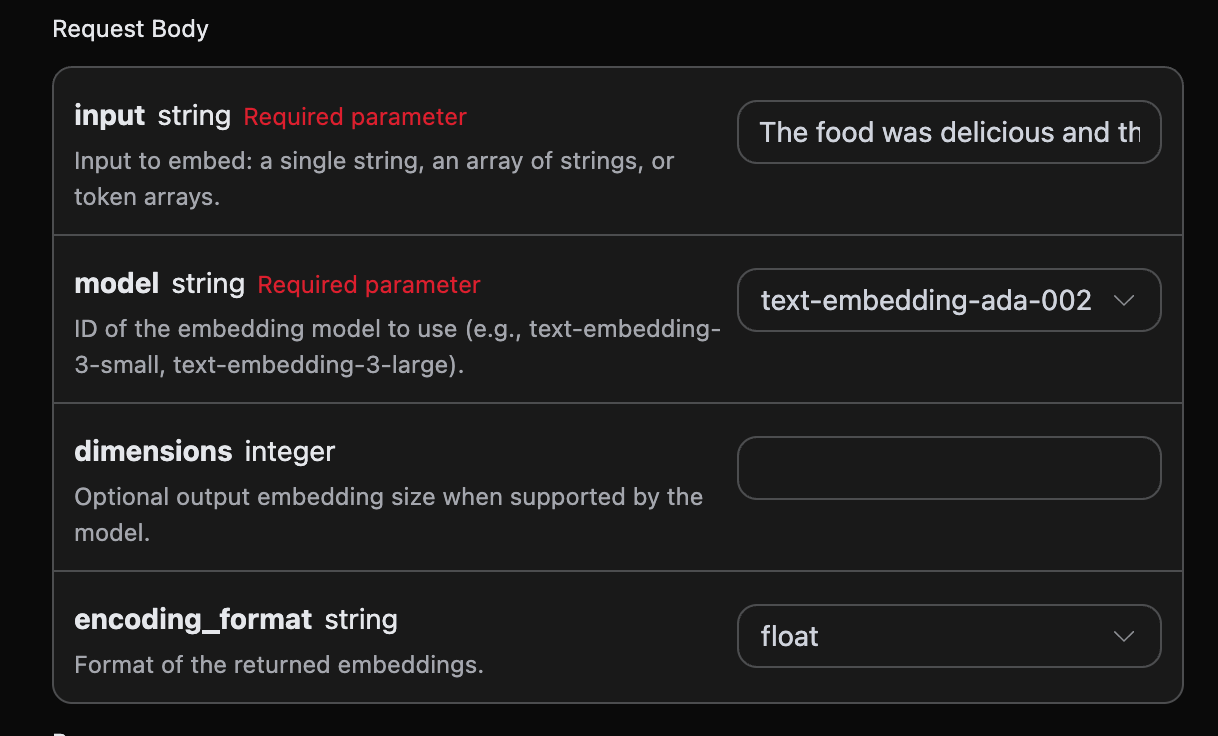
authorization, które można wybrać bezpośrednio z rozwijanej listy. Drugim parametrem jest model, model to kategoria modelu, którą wybieramy z oficjalnej strony OpenAI, mamy tutaj głównie 3 rodzaje modeli, szczegóły można znaleźć w dostarczonych modelach. Ostatnim parametrem jest input, input to tekst, który chcemy przekształcić w wektor słów.
Możesz również zauważyć, że po prawej stronie znajduje się odpowiedni kod do wywołania, który możesz skopiować i uruchomić, lub możesz po prostu kliknąć przycisk „Try”, aby przetestować.
Opcjonalne parametry:
dimensions: przycinanie wymiarów wektora, domyślnie zwraca pełne wymiary.encoding_format: format zwracany, opcjonalniefloatlubbase64.
model, model użyty do przekształcenia tekstu w wektor słów.usage, informacje o tokenach użytych do przekształcenia tekstu w wektor słów.data, wyniki wektora słów po przekształceniu tekstu.
data zawiera szczegółowe informacje o wektorze słów odpowiadającym tekstowi, a embedding to konkretne wyniki wygenerowanego wektora słów.
错误处理
Podczas wywoływania API, jeśli napotkasz błąd, API zwróci odpowiedni kod błędu i informacje. Na przykład:400 token_mismatched: Złe żądanie, prawdopodobnie z powodu brakujących lub nieprawidłowych parametrów.400 api_not_implemented: Złe żądanie, prawdopodobnie z powodu brakujących lub nieprawidłowych parametrów.401 invalid_token: Nieautoryzowany, nieprawidłowy lub brakujący token autoryzacyjny.429 too_many_requests: Zbyt wiele żądań, przekroczono limit szybkości.500 api_error: Błąd wewnętrzny serwera, coś poszło nie tak na serwerze.