Proces aplikacji
Aby korzystać z OpenAI Chat Completion API, najpierw można przejść na stronę OpenAI Chat Completion API i kliknąć przycisk „Acquire”, aby uzyskać potrzebne poświadczenia do żądania: Jeśli nie jesteś zalogowany lub zarejestrowany, automatycznie zostaniesz przekierowany na stronę logowania, aby zarejestrować się i zalogować, a po zalogowaniu lub rejestracji automatycznie wrócisz na bieżącą stronę.
Podczas pierwszej aplikacji otrzymasz darmowy limit, który pozwala na bezpłatne korzystanie z tego API.
Jeśli nie jesteś zalogowany lub zarejestrowany, automatycznie zostaniesz przekierowany na stronę logowania, aby zarejestrować się i zalogować, a po zalogowaniu lub rejestracji automatycznie wrócisz na bieżącą stronę.
Podczas pierwszej aplikacji otrzymasz darmowy limit, który pozwala na bezpłatne korzystanie z tego API.
Podstawowe użycie
Następnie możesz wypełnić odpowiednie treści na interfejsie, jak pokazano na obrazku: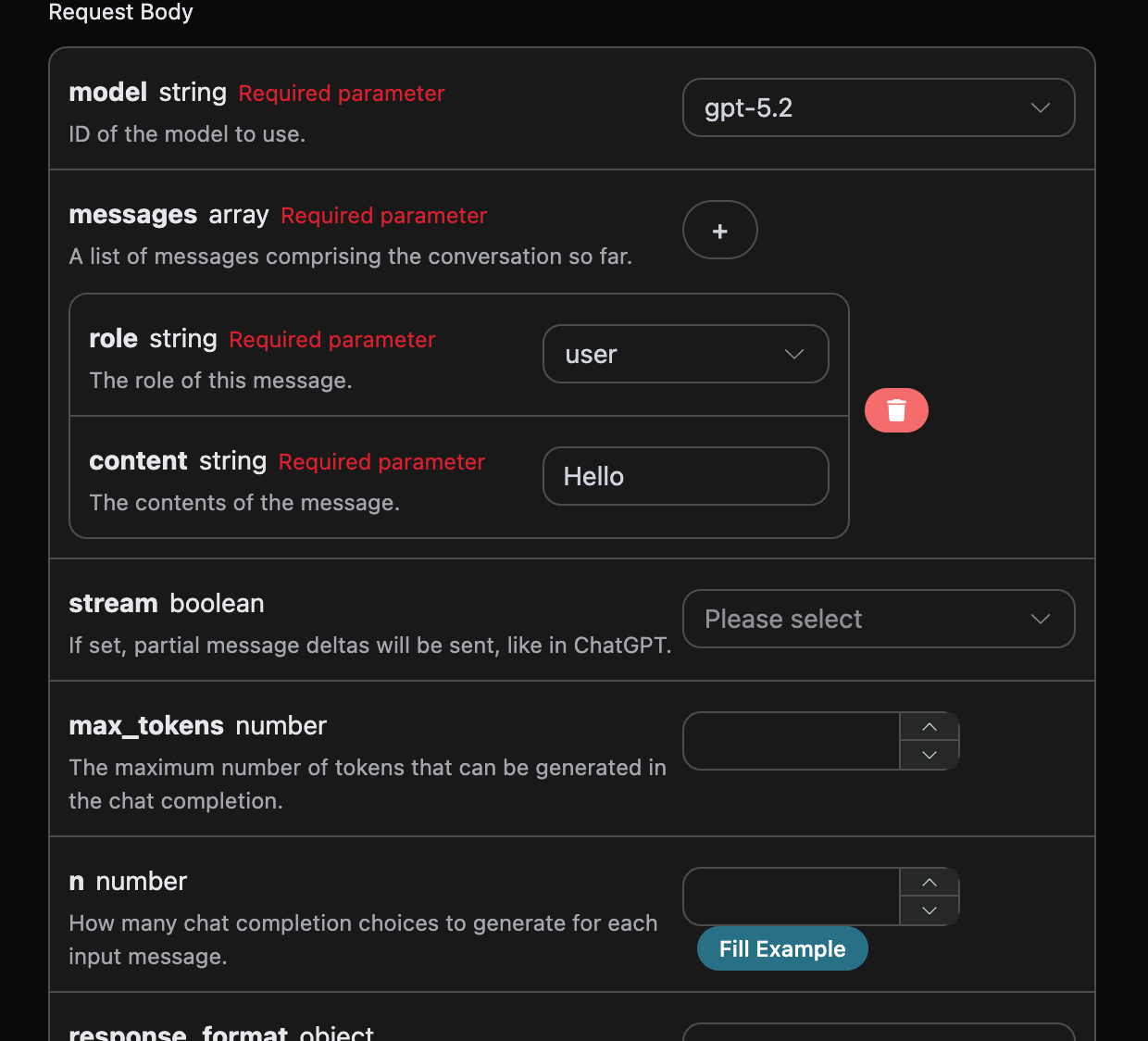
authorization, które można wybrać bezpośrednio z rozwijanej listy. Kolejnym parametrem jest model, który oznacza wybór modelu OpenAI ChatGPT z oficjalnej strony, mamy tutaj głównie 20 modeli, szczegóły można zobaczyć w dostarczonych modelach. Ostatnim parametrem jest messages, który jest tablicą naszych zapytań, oznaczającą możliwość przesyłania wielu zapytań jednocześnie, gdzie każde zapytanie zawiera role i content, przy czym role oznacza rolę pytającego, a my oferujemy trzy tożsamości: user, assistant, system. Drugim content jest konkretna treść naszego zapytania.
Możesz również zauważyć, że po prawej stronie znajduje się odpowiedni kod do wywołania, który możesz skopiować i uruchomić, lub możesz bezpośrednio kliknąć przycisk „Try”, aby przetestować.
Często używane opcjonalne parametry:
max_tokens: ogranicza maksymalną liczbę tokenów w pojedynczej odpowiedzi.temperature: generuje losowość, w zakresie od 0 do 2, im wyższa wartość, tym bardziej rozproszone odpowiedzi.n: ile kandydatów odpowiedzi generować jednocześnie.response_format: ustawienia formatu odpowiedzi.
id, identyfikator generowanego zadania rozmowy, używany do unikalnej identyfikacji tego zadania.model, wybrany model OpenAI ChatGPT.choices, informacje o odpowiedziach ChatGPT na zapytania.usage: statystyki dotyczące tokenów dla tej sesji pytań i odpowiedzi.
choices zawiera informacje o odpowiedziach ChatGPT, a w nim choices to odpowiedzi ChatGPT, co można zobaczyć na obrazku.
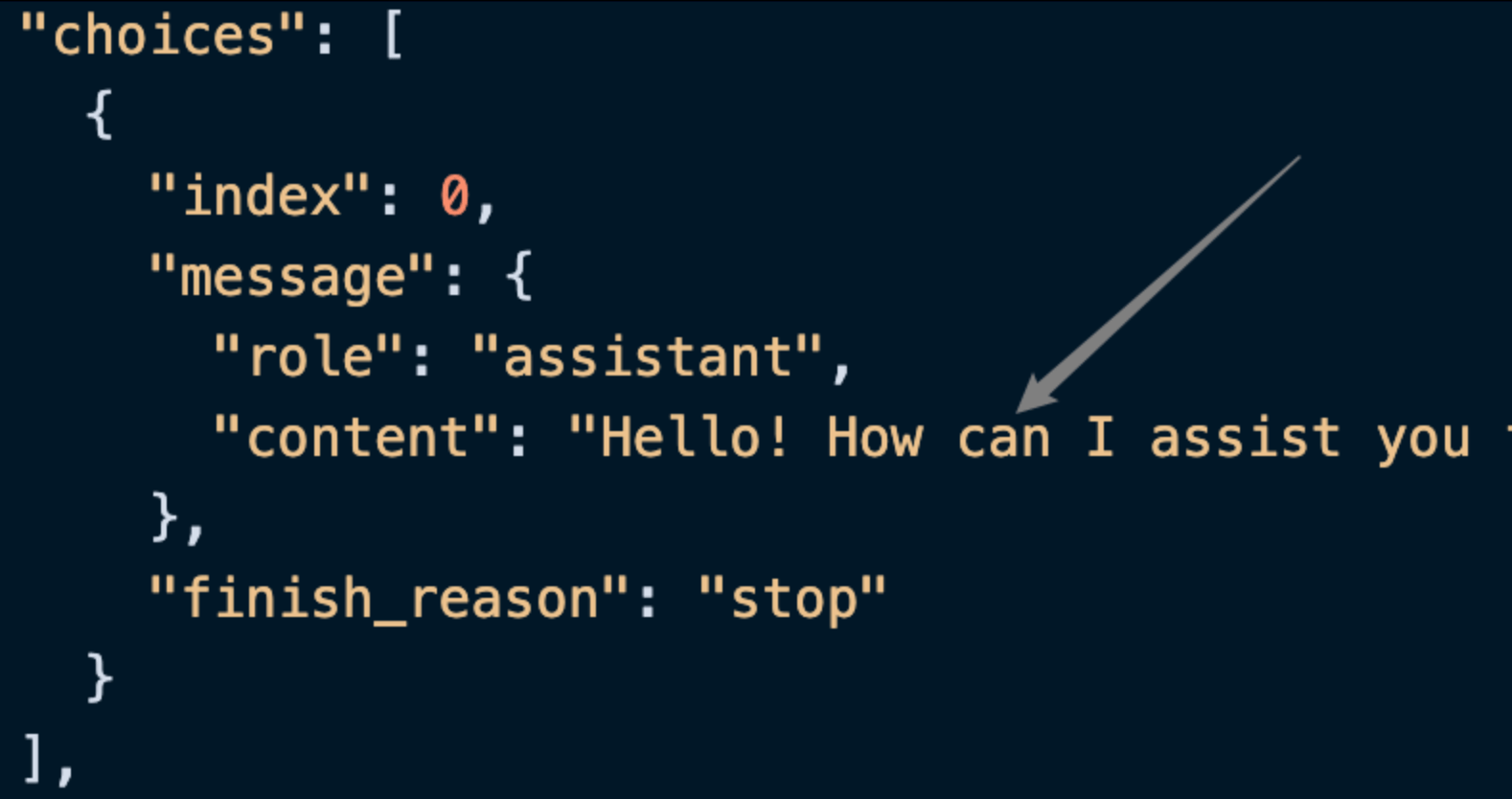
content w choices zawiera konkretną treść odpowiedzi ChatGPT.
Odpowiedzi strumieniowe
Ten interfejs obsługuje również odpowiedzi strumieniowe, co jest bardzo przydatne w integracji z stronami internetowymi, umożliwiając wyświetlanie efektu literowego. Aby uzyskać odpowiedzi strumieniowe, można zmienić parametrstream w nagłówku żądania na true.
Zmiana jak na obrazku, jednak kod wywołania musi być odpowiednio zmieniony, aby obsługiwał odpowiedzi strumieniowe.
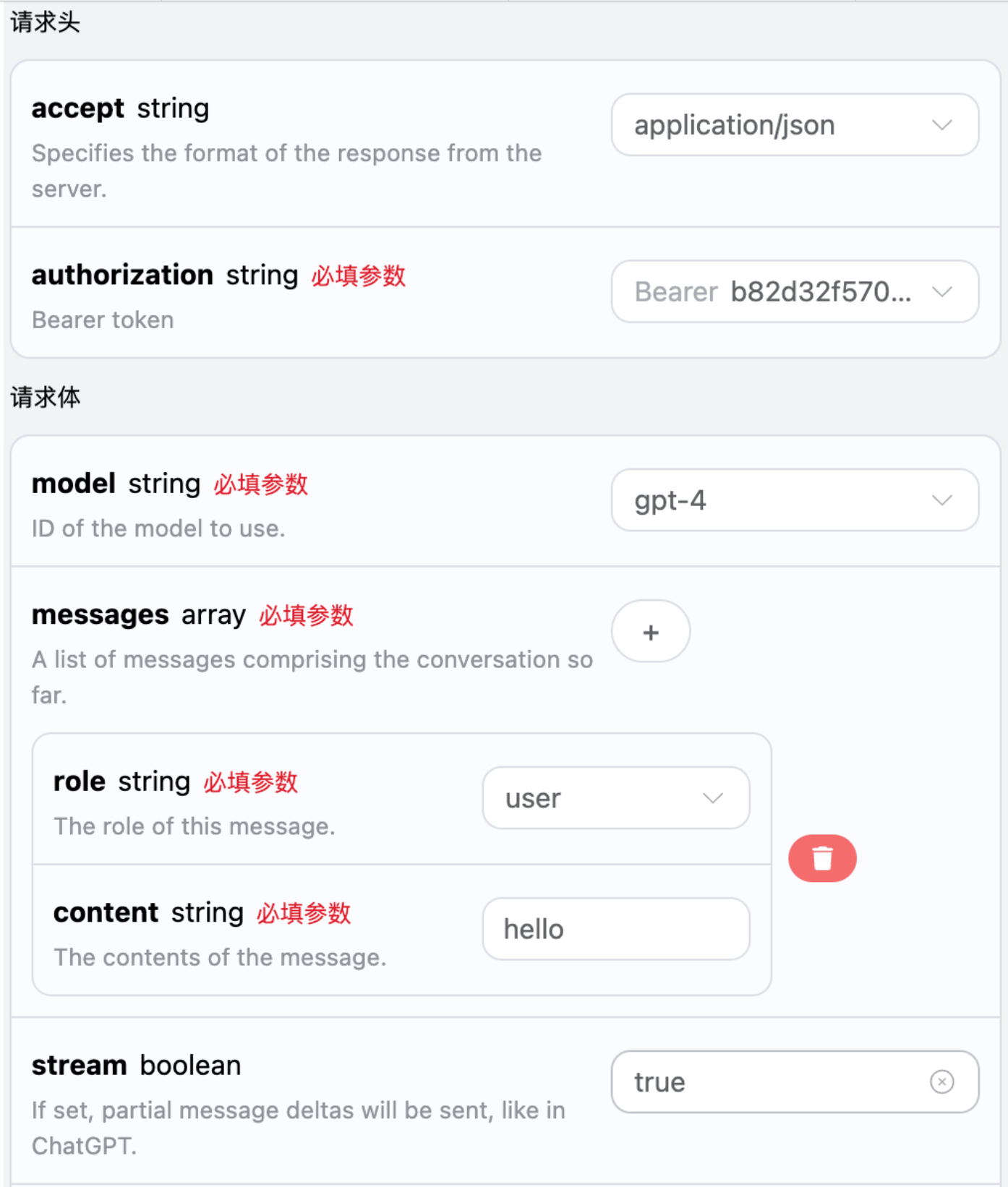
stream na true, API będzie zwracać odpowiednie dane JSON w wierszach, a na poziomie kodu musimy wprowadzić odpowiednie zmiany, aby uzyskać wyniki w wierszach.
Przykładowy kod wywołania w Pythonie:
data, a data wewnątrz choices to najnowsza treść odpowiedzi, zgodna z wcześniej przedstawioną treścią. choices to nowa treść odpowiedzi, którą można zintegrować z systemem. Zakończenie strumieniowej odpowiedzi można ocenić na podstawie zawartości data; jeśli zawartość to [DONE], oznacza to, że strumieniowa odpowiedź została zakończona. Zwracane wyniki data mają wiele pól, które są opisane poniżej:
id, identyfikator generowanego zadania rozmowy, używany do unikalnego oznaczenia tego zadania.model, wybrany model OpenAI ChatGPT.choices, informacje o odpowiedzi ChatGPT na zadane pytanie.
Wieloetapowa rozmowa
Jeśli chcesz zintegrować funkcję wieloetapowej rozmowy, musisz przesłać wiele pytań w polumessages, konkretne przykłady wielu pytań są pokazane na poniższym obrazku:
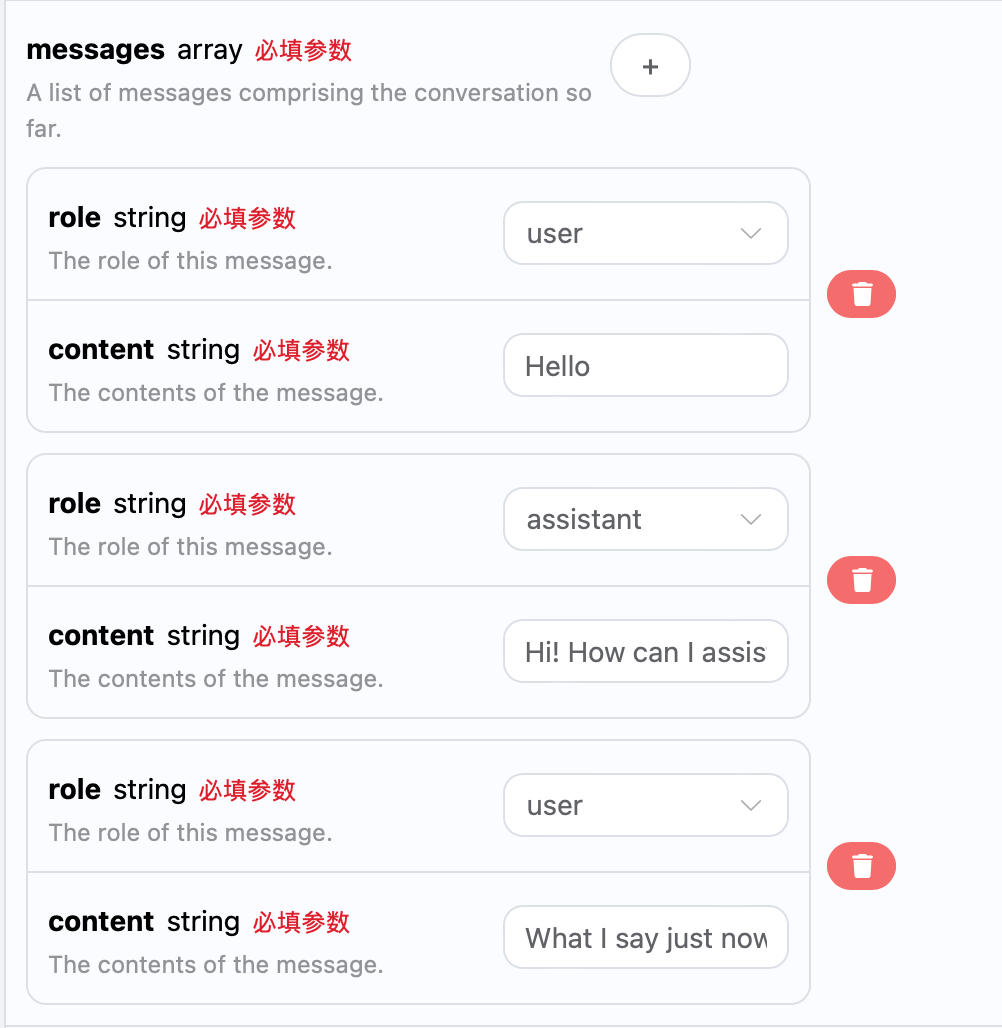
choices są zgodne z podstawowym użyciem, zawierają one konkretne odpowiedzi ChatGPT na wiele rozmów, co pozwala na odpowiadanie na odpowiednie pytania na podstawie wielu treści rozmowy.
Integracja z OpenAI-Python
Usługa OpenAI Chat Completion API jest oparta na oficjalnej usłudze OpenAI, szczegóły można znaleźć w oficjalnym OpenAI-Python, w tym artykule krótko omówimy, jak korzystać z oficjalnie dostarczonej usługi.- Najpierw należy zbudować lokalne środowisko
Python, ten proces można wyszukać w Google. - Zainstaluj i skonfiguruj środowisko deweloperskie, na przykład zainstaluj edytor VSCode.
- Skonfiguruj zmienne środowiskowe
OpenAI.
- W folderze projektu utwórz plik o nazwie
.envi zapisz - Zawartość pliku
.env:
sk-xxx swoim kluczem. OPENAI_BASE_URL to adres do proxy API OpenAI.
- Zainstaluj zależności projektu
- Utwórz przykładowy plik źródłowy
index.py, którego zawartość jest następująca:
Model z dostępem do internetu
Modele gpt-3.5-browsing i gpt-4-browsing różnią się od innych modeli, mogą one przeprowadzać wyszukiwanie w internecie na podstawie zadanych pytań i odpowiednio dostosowywać wyniki wyszukiwania, aby je zwrócić. W artykule tym zaprezentujemy funkcję dostępu do internetu na konkretnym przykładzie, a następnie można wypełnić odpowiednie treści w interfejsie OpenAI Chat Completion API, jak pokazano na obrazku: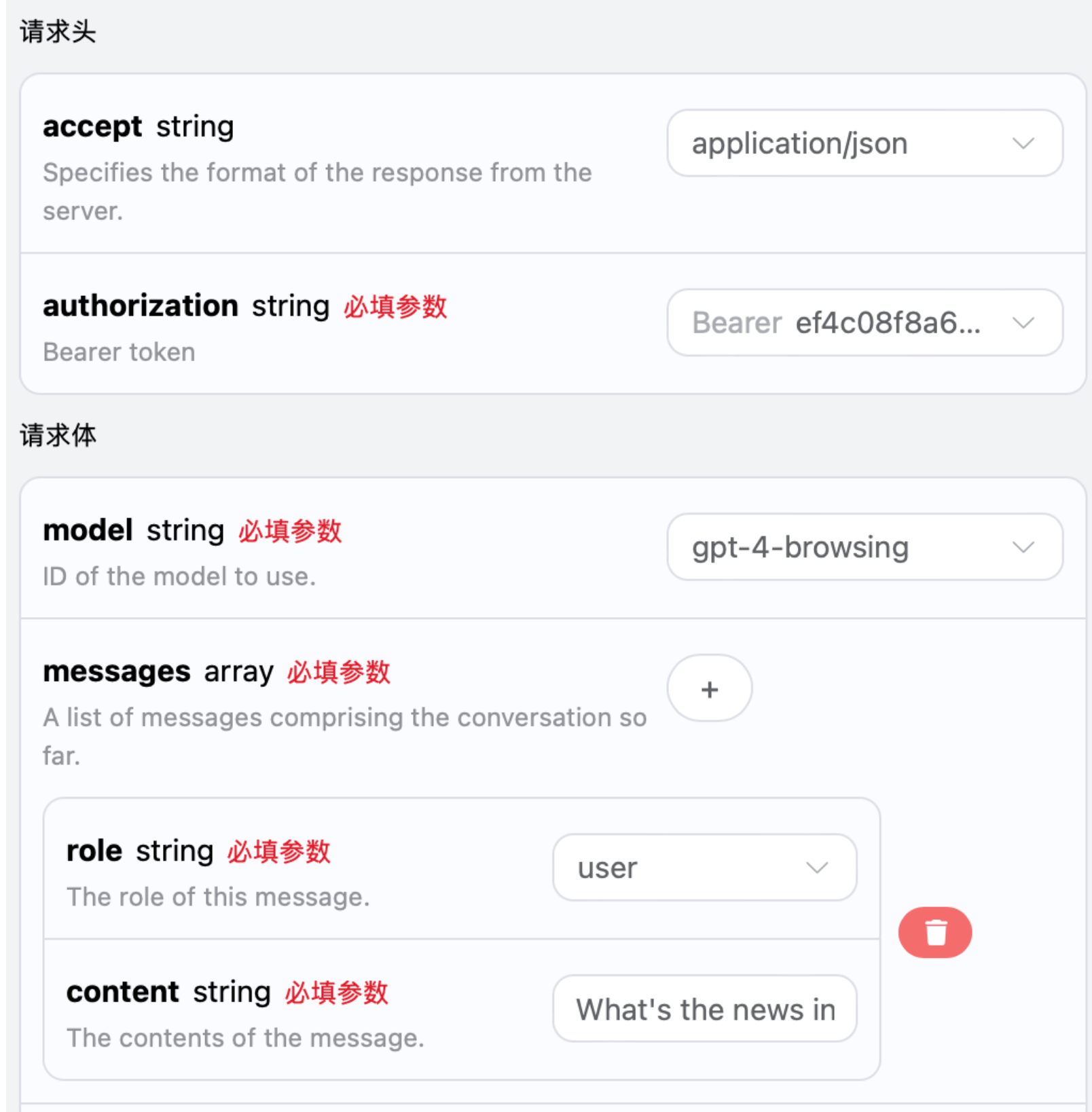
choices są oparte na wynikach wyszukiwania w internecie i zawierają odpowiednie linki. Informacje odpowiedzi w choices powinny być renderowane za pomocą składni markdown, aby uzyskać najlepsze doświadczenie, co również podkreśla potężną zaletę funkcji dostępu do internetu w naszym modelu.
Model wizualny
gpt-4o to wielomodalny model językowy opracowany przez OpenAI, który na podstawie GPT-4 zyskał zdolność rozumienia wizualnego. Model ten może jednocześnie przetwarzać tekst i obrazy, osiągając zrozumienie i generowanie w różnych modalnościach. Przetwarzanie tekstu w modelu gpt-4o jest zgodne z podstawowym użyciem opisanym powyżej, poniżej krótko omówimy, jak korzystać z możliwości przetwarzania obrazów tego modelu. Wykorzystanie możliwości przetwarzania obrazów w modelu gpt-4o polega głównie na dodaniu polatype do istniejącej treści content, dzięki któremu można określić, czy przesyłany jest tekst, czy obraz, co pozwala na wykorzystanie zdolności przetwarzania obrazów modelu gpt-4o. Poniżej omówimy, jak wywołać tę funkcję za pomocą Curl i Pythona.
- Metoda skryptu Curl
- Metoda skryptu Python
Model rysunkowy GPT-4o
Przykład żądania:Obsługa błędów
Podczas wywoływania API, jeśli wystąpi błąd, API zwróci odpowiedni kod błędu i informacje. Na przykład:400 token_mismatched: Złe żądanie, prawdopodobnie z powodu brakujących lub nieprawidłowych parametrów.400 api_not_implemented: Złe żądanie, prawdopodobnie z powodu brakujących lub nieprawidłowych parametrów.401 invalid_token: Nieautoryzowany, nieprawidłowy lub brakujący token autoryzacyjny.429 too_many_requests: Zbyt wiele żądań, przekroczono limit szybkości.500 api_error: Błąd wewnętrzny serwera, coś poszło nie tak na serwerze.