Processo di richiesta
Per utilizzare l’API OpenAI Chat Completion, è possibile visitare la pagina OpenAI Chat Completion API e fare clic sul pulsante “Acquire” per ottenere le credenziali necessarie per la richiesta: Se non si è ancora registrati o loggati, si verrà automaticamente reindirizzati alla pagina di accesso per registrarsi e accedere; dopo aver effettuato la registrazione e l’accesso, si tornerà automaticamente alla pagina corrente.
Alla prima richiesta, verrà fornito un credito gratuito, che consente di utilizzare l’API senza costi.
Se non si è ancora registrati o loggati, si verrà automaticamente reindirizzati alla pagina di accesso per registrarsi e accedere; dopo aver effettuato la registrazione e l’accesso, si tornerà automaticamente alla pagina corrente.
Alla prima richiesta, verrà fornito un credito gratuito, che consente di utilizzare l’API senza costi.
Utilizzo di base
Successivamente, è possibile compilare i contenuti corrispondenti nell’interfaccia, come mostrato nell’immagine: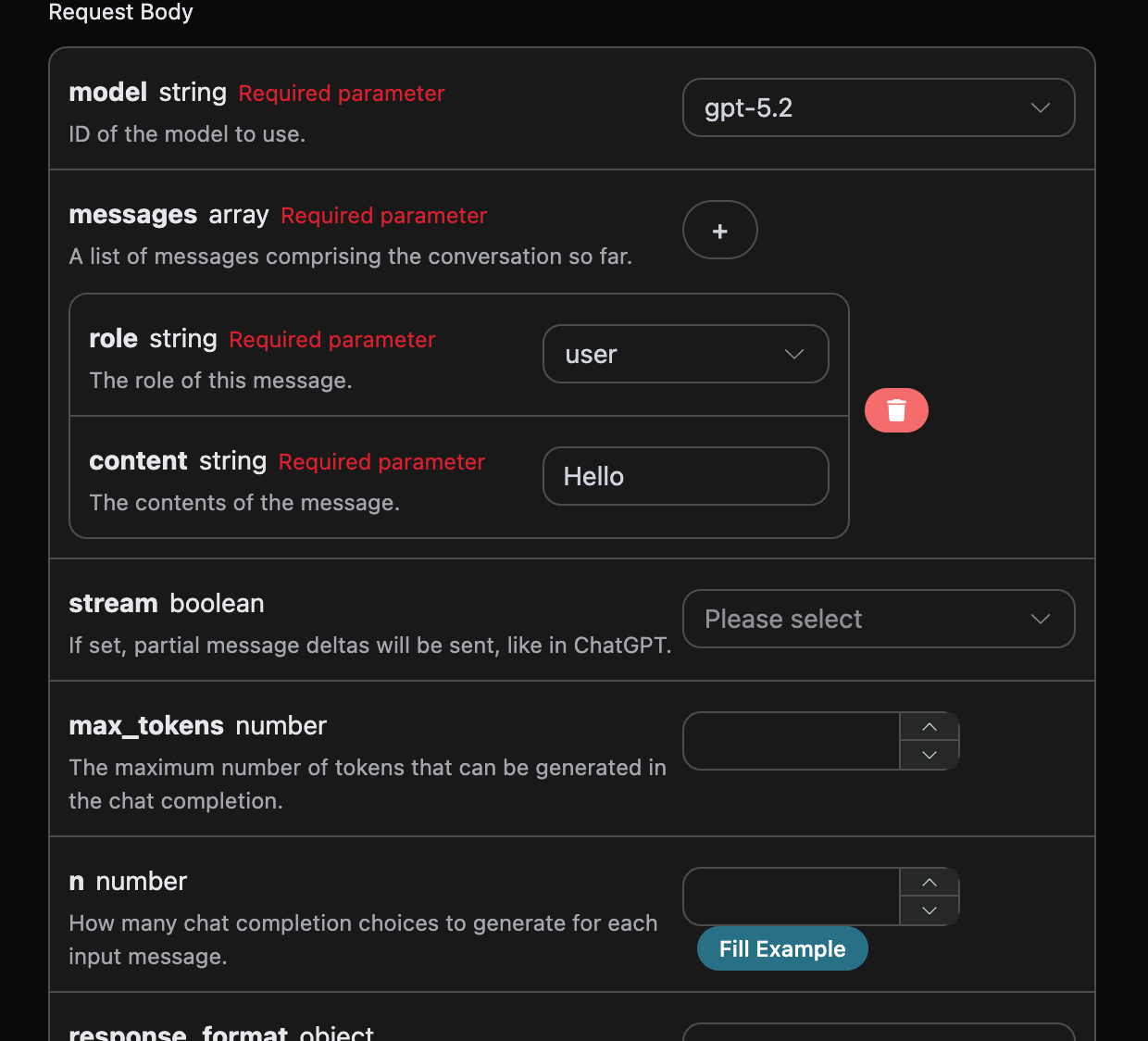
authorization, che può essere selezionato direttamente dal menu a discesa. Un altro parametro è model, che rappresenta la categoria del modello di OpenAI ChatGPT che si desidera utilizzare; qui abbiamo principalmente 20 modelli, i dettagli possono essere consultati nei modelli forniti. L’ultimo parametro è messages, che è un array di parole chiave che inseriamo; rappresenta un array che consente di caricare più parole chiave contemporaneamente, ogni parola chiave contiene role e content, dove role indica il ruolo del richiedente; abbiamo fornito tre identità: user, assistant, system. L’altro content è il contenuto specifico della nostra domanda.
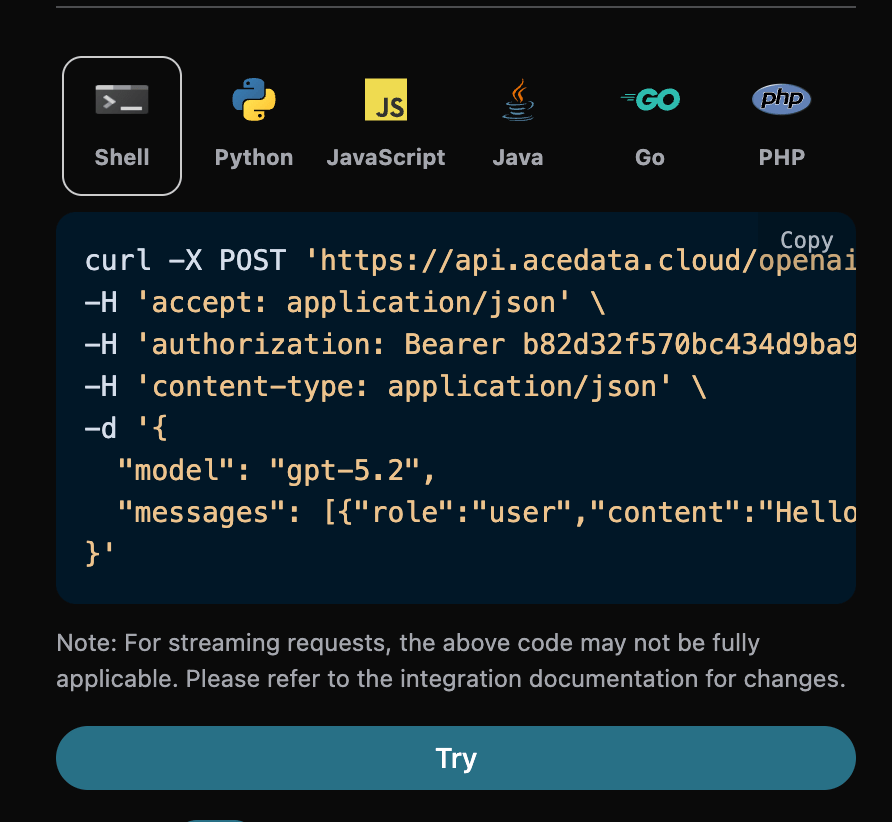
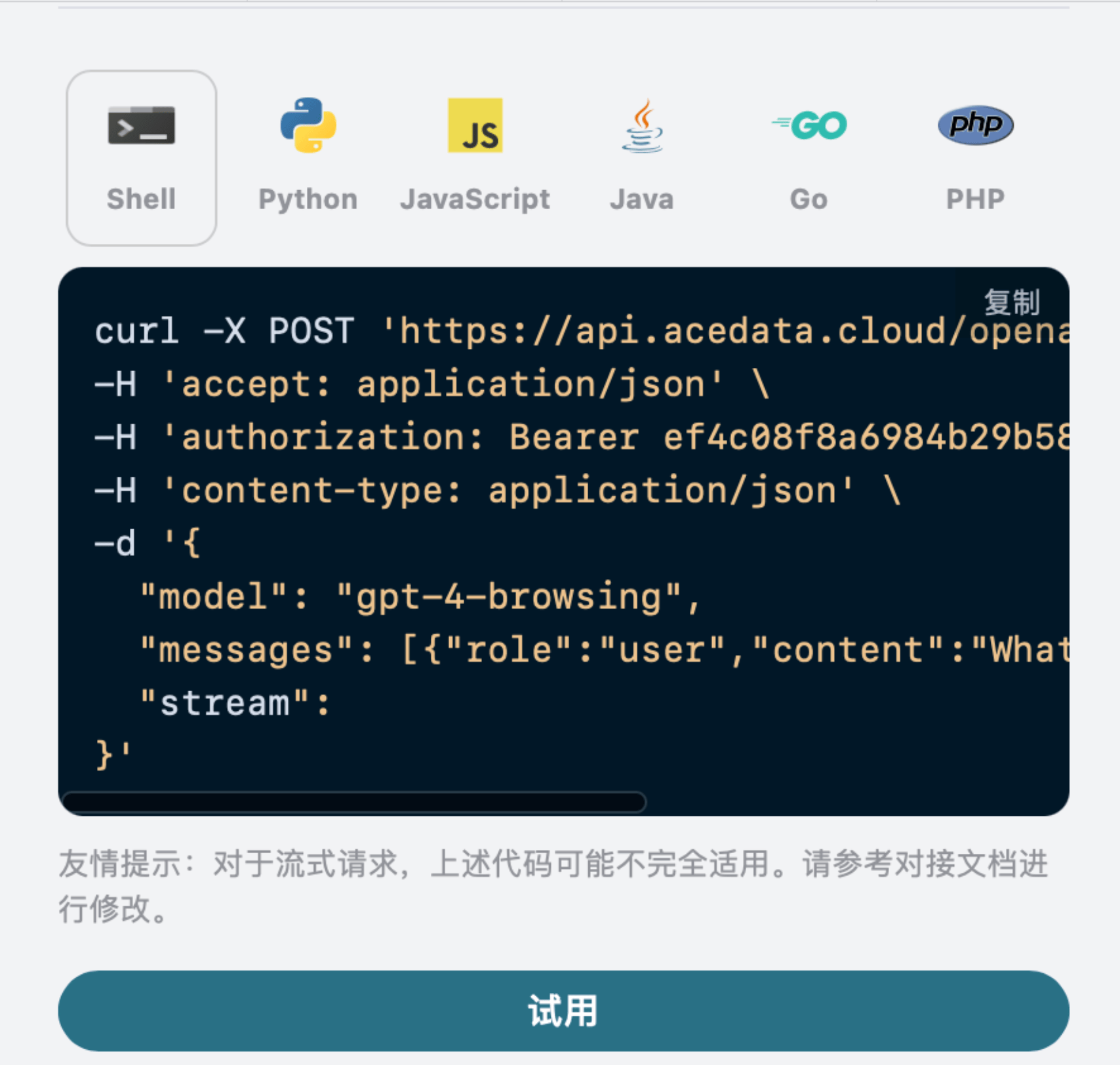
Inoltre, si può notare che a destra c’è un codice di chiamata corrispondente generato; è possibile copiare il codice e eseguirlo direttamente, oppure fare clic sul pulsante “Try” per testarlo.
Parametri opzionali comuni:
max_tokens: limita il numero massimo di token nella risposta.temperature: genera casualità, tra 0-2, valori più alti portano a maggiore dispersione.n: quante risposte candidate generare in una volta.response_format: impostazione del formato di ritorno.
id, l’ID della generazione di questo compito di dialogo, utilizzato per identificare univocamente questo compito di dialogo.model, il modello di OpenAI ChatGPT selezionato.choices, le informazioni di risposta fornite da ChatGPT in base alle parole chiave.usage: informazioni statistiche sui token per questa domanda e risposta.
choices contiene le informazioni di risposta di ChatGPT, dove si può notare come mostrato nell’immagine.
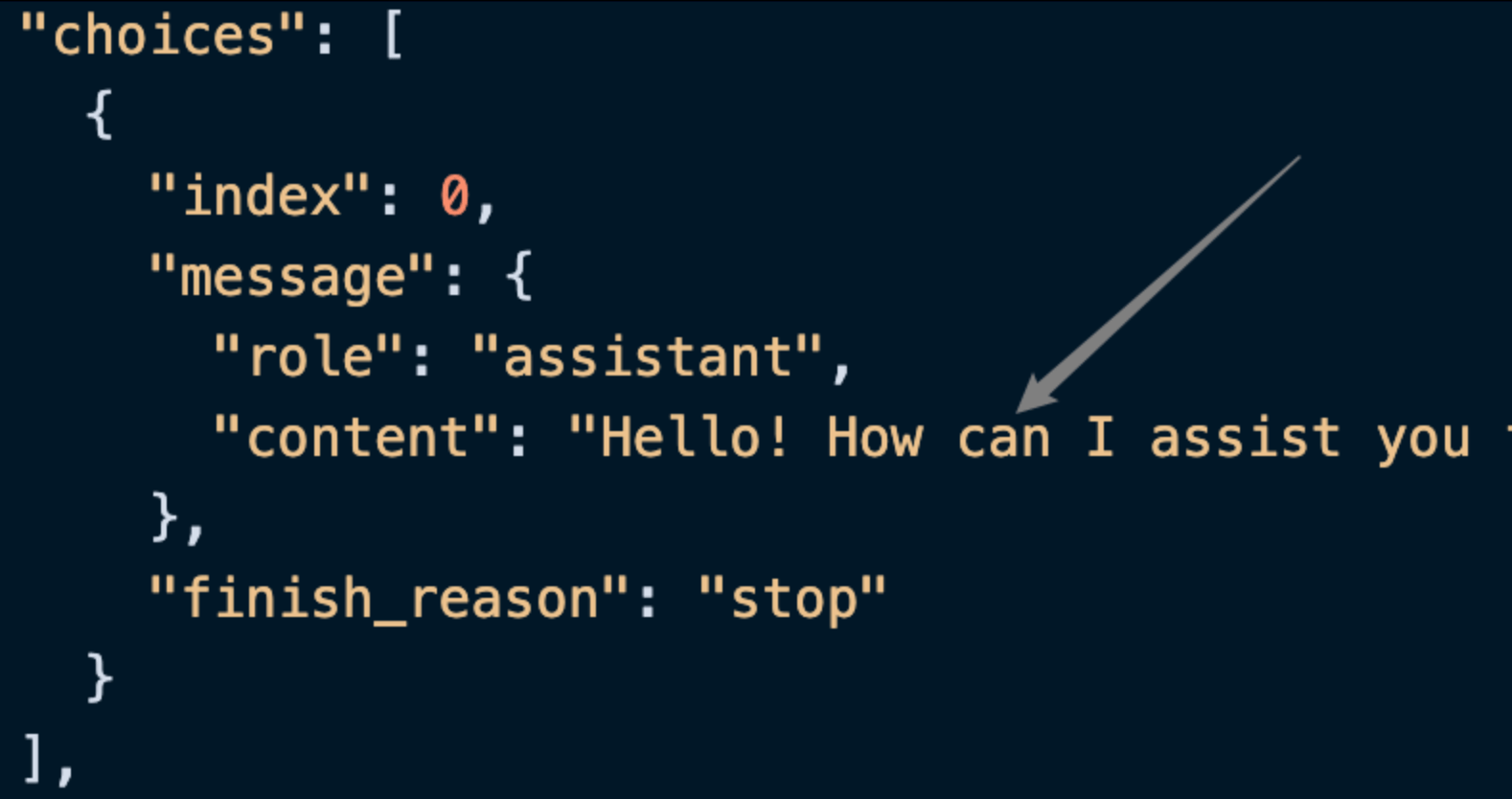
content all’interno di choices contiene il contenuto specifico della risposta di ChatGPT.
Risposta in streaming
Questa interfaccia supporta anche le risposte in streaming, il che è molto utile per l’integrazione web, consentendo di visualizzare il contenuto parola per parola. Se si desidera restituire una risposta in streaming, è possibile modificare il parametrostream nell’intestazione della richiesta, impostandolo su true.
La modifica è mostrata nell’immagine, ma il codice di chiamata deve essere adeguatamente modificato per supportare la risposta in streaming.
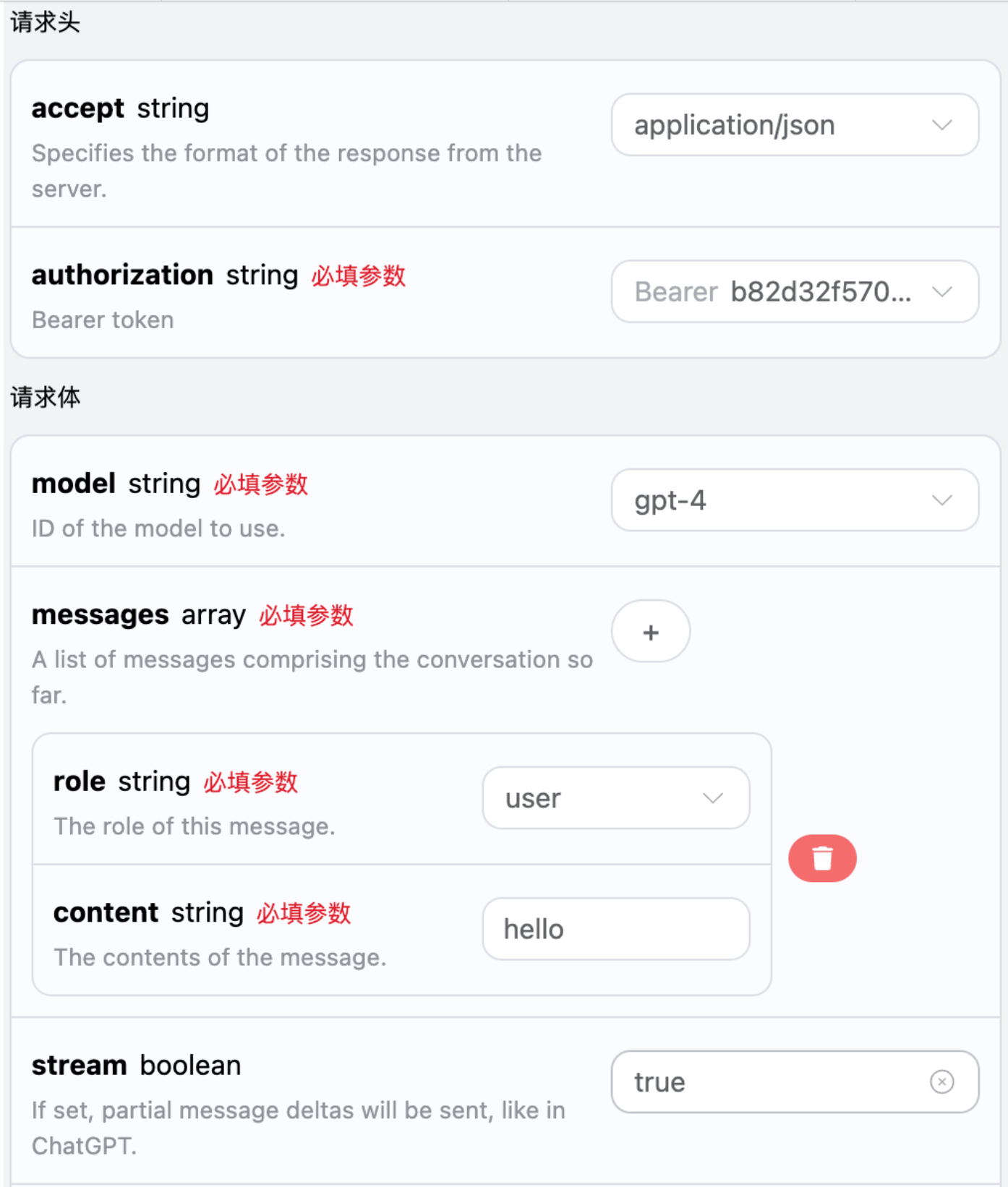
stream in true, l’API restituirà i dati JSON riga per riga; a livello di codice, è necessario apportare le modifiche necessarie per ottenere i risultati riga per riga.
Esempio di codice di chiamata in Python:
data, data contiene choices che rappresentano il contenuto della risposta più recente, coerente con quanto descritto in precedenza. choices è il contenuto della risposta aggiunto, che puoi integrare nel tuo sistema. Inoltre, la fine della risposta in streaming è determinata dal contenuto di data; se il contenuto è [FINE], significa che la risposta in streaming è completamente terminata. I risultati restituiti da data hanno diversi campi, descritti come segue:
id, l’ID generato per questa attività di conversazione, utilizzato per identificare univocamente questa attività di conversazione.model, il modello scelto dal sito ufficiale di OpenAI ChatGPT.choices, le informazioni di risposta fornite da ChatGPT in base alla domanda.
Conversazione a più turni
Se desideri integrare la funzionalità di conversazione a più turni, devi caricare più domande nel campomessages, un esempio specifico di più domande è mostrato nell’immagine sottostante:
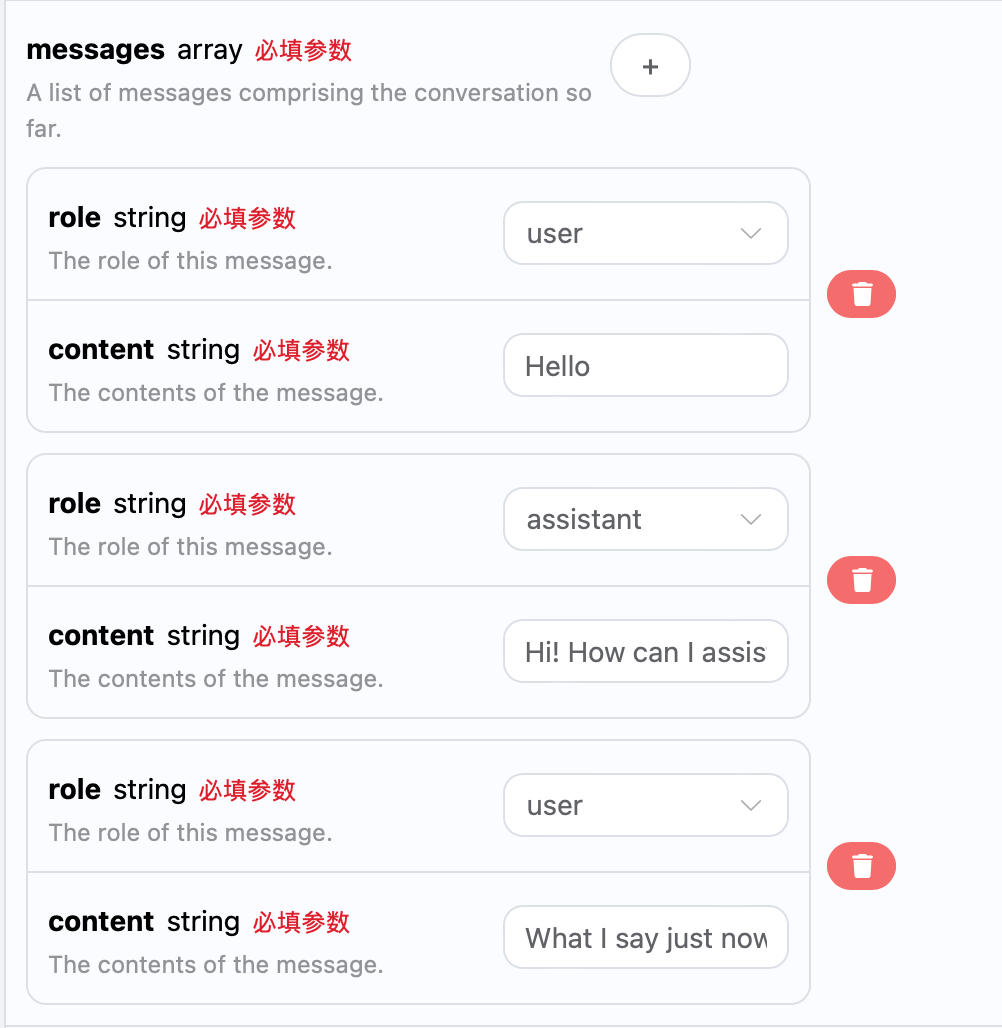
choices sono coerenti con il contenuto di base utilizzato, includendo il contenuto specifico delle risposte di ChatGPT a più dialoghi, permettendo così di rispondere a domande corrispondenti in base ai contenuti di più dialoghi.
Integrazione con OpenAI-Python
Il servizio OpenAI Chat Completion API è alimentato dal servizio ufficiale di OpenAI, per dettagli si può consultare il OpenAI-Python ufficiale, in questo articolo verrà fornita una breve introduzione su come utilizzare il servizio fornito ufficialmente.- Prima di tutto, è necessario impostare un ambiente
Pythonlocale, questo processo può essere cercato su Google. - Scaricare e installare l’ambiente di sviluppo, ad esempio installare l’editor VSCode.
- Configurare le variabili d’ambiente
OpenAI.
- Nella cartella del progetto, creare un file chiamato
.enve salvarlo. - Contenuto del file
.env:
sk-xxx con la tua chiave. OPENAI_BASE_URL è l’interfaccia proxy per accedere a OpenAI.
- Installare i pacchetti dipendenti del progetto
- Creare un file di codice sorgente di esempio
index.py, il contenuto specifico è il seguente:
Modello di navigazione
I modelli gpt-3.5-browsing e gpt-4-browsing sono diversi dagli altri modelli, possono effettuare ricerche online in base alle domande e restituire i risultati della ricerca online con le dovute modifiche, in questo articolo verrà mostrato un esempio concreto per dimostrare la funzionalità di navigazione, successivamente si possono compilare i contenuti corrispondenti nell’interfaccia OpenAI Chat Completion API, come mostrato nell’immagine: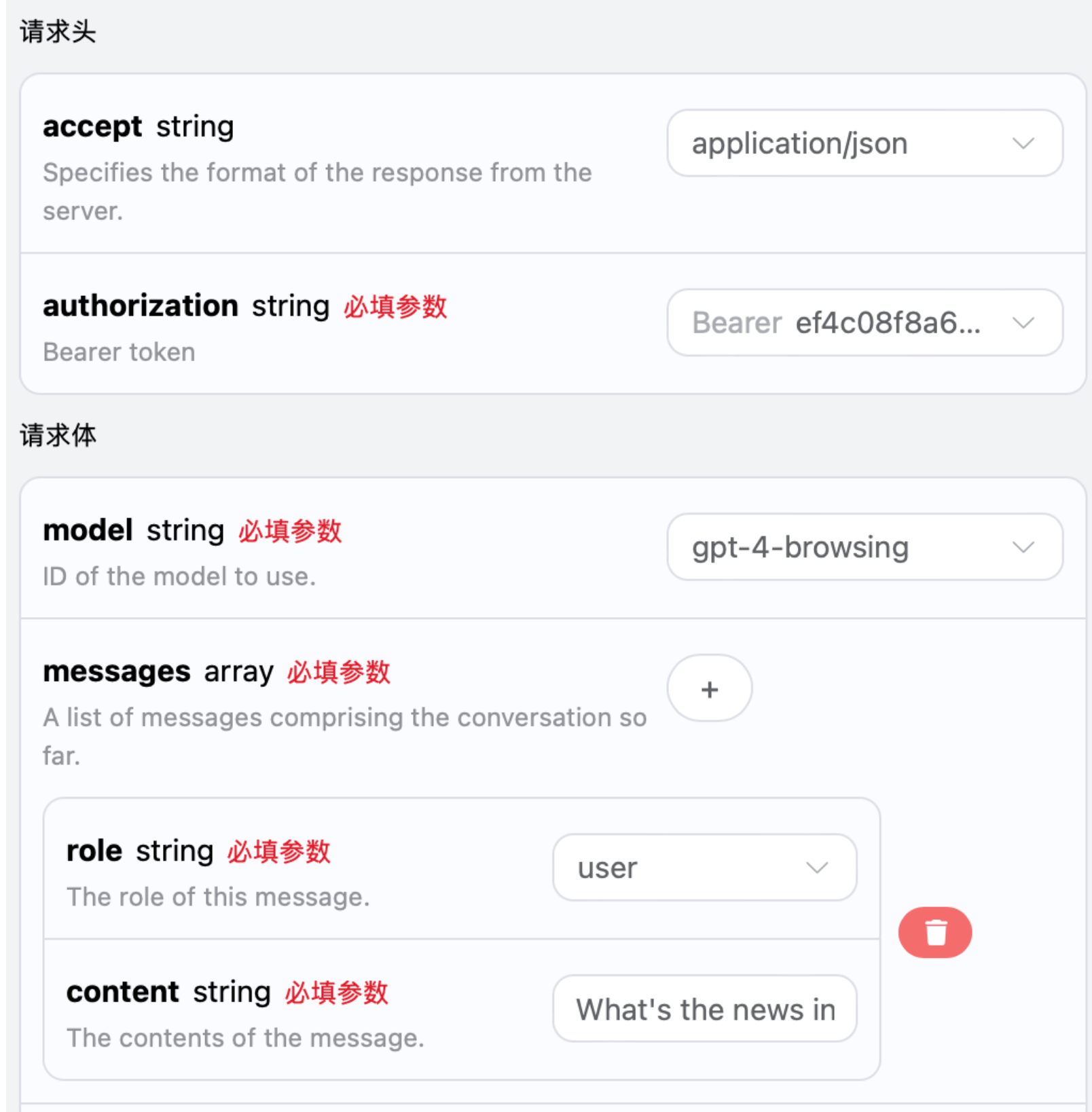
choices sono state ottenute in base alla ricerca online e sono stati forniti anche i link pertinenti, le informazioni di risposta all’interno di choices devono essere renderizzate utilizzando la sintassi markdown, in modo da ottenere la migliore esperienza, infine questo dimostra anche il potente vantaggio della funzionalità di navigazione del nostro modello.
Modello visivo
gpt-4o è un modello linguistico di grandi dimensioni multimodale sviluppato da OpenAI, che ha aumentato la capacità di comprensione visiva sulla base di GPT-4. Questo modello può gestire simultaneamente input di testo e immagini, realizzando una comprensione e generazione cross-modale. L’elaborazione del testo utilizzando il modello gpt-4o è coerente con il contenuto di base utilizzato in precedenza, di seguito verrà fornita una breve introduzione su come utilizzare la capacità di elaborazione delle immagini del modello. L’uso della capacità di elaborazione delle immagini del modello gpt-4o avviene principalmente aggiungendo un campotype al contenuto content originale, attraverso il quale si può sapere se ciò che viene caricato è testo o immagine, permettendo così di utilizzare la capacità di elaborazione delle immagini del modello gpt-4o, di seguito si parlerà principalmente di come chiamare questa funzionalità utilizzando Curl e Python.
- Metodo Curl
- Metodo Python
Modello di disegno GPT-4o
Esempio di richiesta:Gestione degli errori
Quando si chiama l’API, se si verifica un errore, l’API restituirà il codice di errore e le informazioni corrispondenti. Ad esempio:400 token_mismatched: Richiesta non valida, probabilmente a causa di parametri mancanti o non validi.400 api_not_implemented: Richiesta non valida, probabilmente a causa di parametri mancanti o non validi.401 invalid_token: Non autorizzato, token di autorizzazione non valido o mancante.429 too_many_requests: Troppe richieste, hai superato il limite di frequenza.500 api_error: Errore interno del server, qualcosa è andato storto sul server.