messages. Per completare una conversazione continua, dobbiamo trasmettere tutta la storia del contesto e gestire anche il problema del superamento del limite di Token.
L’API di domande e risposte AI fornita da AceDataCloud è stata ottimizzata per affrontare queste situazioni. Garantendo che l’efficacia delle risposte rimanga invariata, ha incapsulato l’implementazione delle conversazioni continue, senza la necessità di preoccuparsi della trasmissione dei messaggi o del superamento del limite di Token (gestito automaticamente all’interno dell’API). Inoltre, offre funzionalità per la consultazione e la modifica delle conversazioni, semplificando notevolmente l’integrazione complessiva.
Questo documento presenterà le istruzioni per l’integrazione dell’API di domande e risposte AI.
Processo di Richiesta
Per utilizzare l’API, è necessario prima andare alla pagina corrispondente dell’API di domande e risposte AI per richiedere il servizio corrispondente. Una volta entrati nella pagina, cliccare sul pulsante “Acquire”, come mostrato nell’immagine: Se non sei ancora loggato o registrato, verrai automaticamente reindirizzato alla pagina di accesso per invitarti a registrarti e accedere. Dopo aver effettuato il login o la registrazione, verrai automaticamente riportato alla pagina corrente.
Alla prima richiesta, verrà offerto un credito gratuito, che ti consente di utilizzare l’API senza costi.
Se non sei ancora loggato o registrato, verrai automaticamente reindirizzato alla pagina di accesso per invitarti a registrarti e accedere. Dopo aver effettuato il login o la registrazione, verrai automaticamente riportato alla pagina corrente.
Alla prima richiesta, verrà offerto un credito gratuito, che ti consente di utilizzare l’API senza costi.
Utilizzo di Base
Iniziamo a comprendere il modo di utilizzo di base, che consiste nell’inserire una domanda e ottenere una risposta, basta semplicemente trasmettere un campoquestion e specificare il modello corrispondente.
Ad esempio, chiedendo: “What’s your name?”, possiamo quindi compilare il contenuto corrispondente nell’interfaccia, come mostrato nell’immagine:
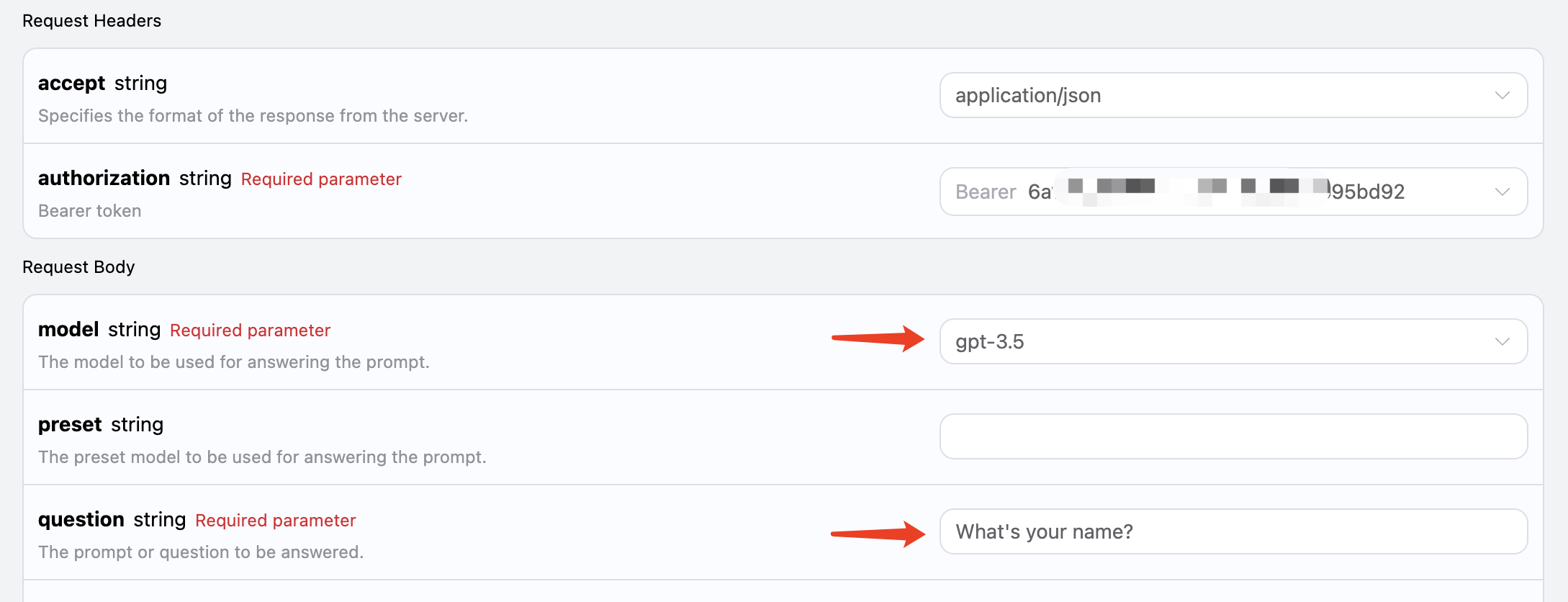 Possiamo vedere che qui abbiamo impostato le intestazioni della richiesta, tra cui:
Possiamo vedere che qui abbiamo impostato le intestazioni della richiesta, tra cui:
accept: il formato della risposta desiderata, qui impostato suapplication/json, ovvero formato JSON.authorization: la chiave per chiamare l’API, che può essere selezionata direttamente dopo la richiesta.
model: la scelta del modello, come i popolari GPT 3.5, GPT 4, ecc.question: la domanda da porre, che può essere qualsiasi testo semplice.
answer, che è la risposta a quella domanda. Possiamo inserire qualsiasi domanda e ottenere qualsiasi risposta.
Se non hai bisogno di alcun supporto per conversazioni multiple, questa API può semplificare notevolmente la tua integrazione.
Inoltre, se desideri generare il codice di integrazione corrispondente, puoi semplicemente copiarlo, ad esempio il codice CURL è il seguente:
Conversazione Multipla
Se desideri integrare la funzionalità di conversazione multipla, è necessario trasmettere un parametro aggiuntivostateful, il cui valore deve essere true. Ogni richiesta successiva deve includere questo parametro. Dopo aver trasmesso il parametro stateful, l’API restituirà un parametro id aggiuntivo, che rappresenta l’ID della conversazione corrente. Successivamente, dovremo semplicemente trasmettere questo ID come parametro per realizzare facilmente conversazioni multiple.
Di seguito mostriamo un’operazione specifica.
La prima richiesta imposta il parametro stateful su true e trasmette normalmente i parametri model e question, come mostrato nell’immagine:
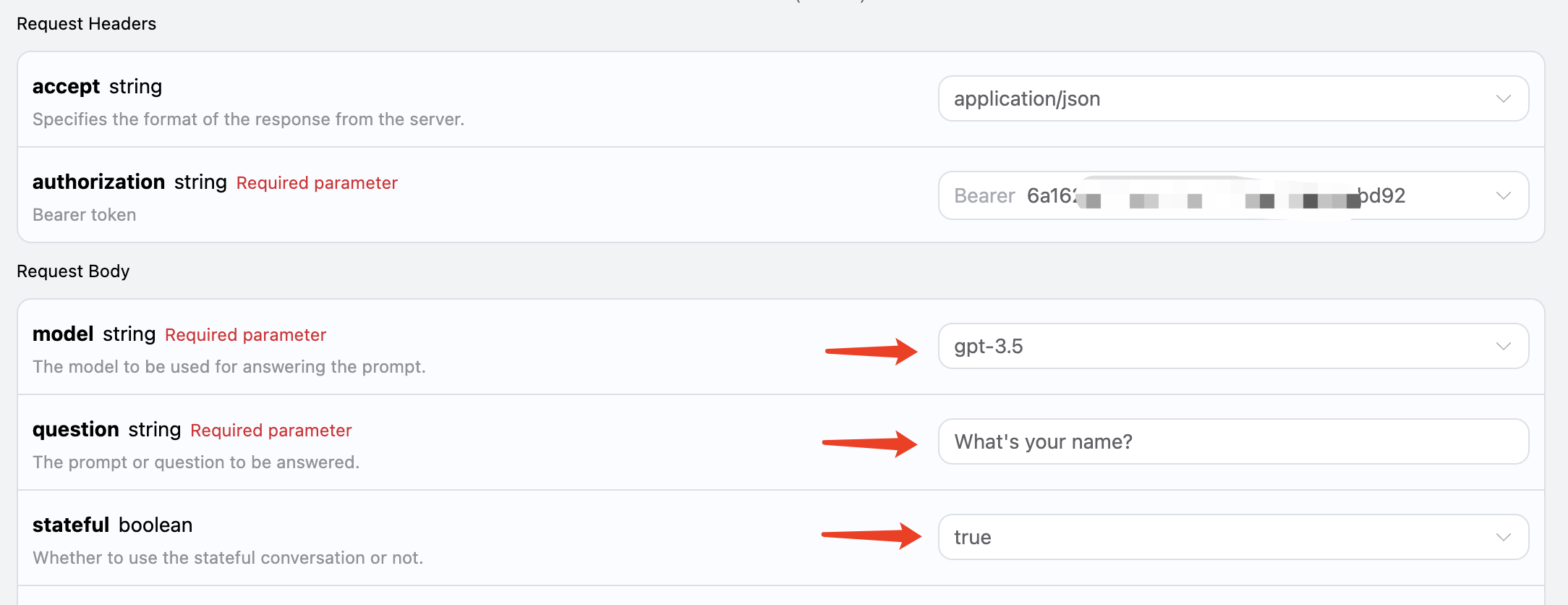 Il codice corrispondente è il seguente:
Il codice corrispondente è il seguente:
id restituito dalla prima richiesta come parametro, mantenendo il parametro stateful impostato su true, e chiediamo “What I asked you just now?”, come mostrato nell’immagine:
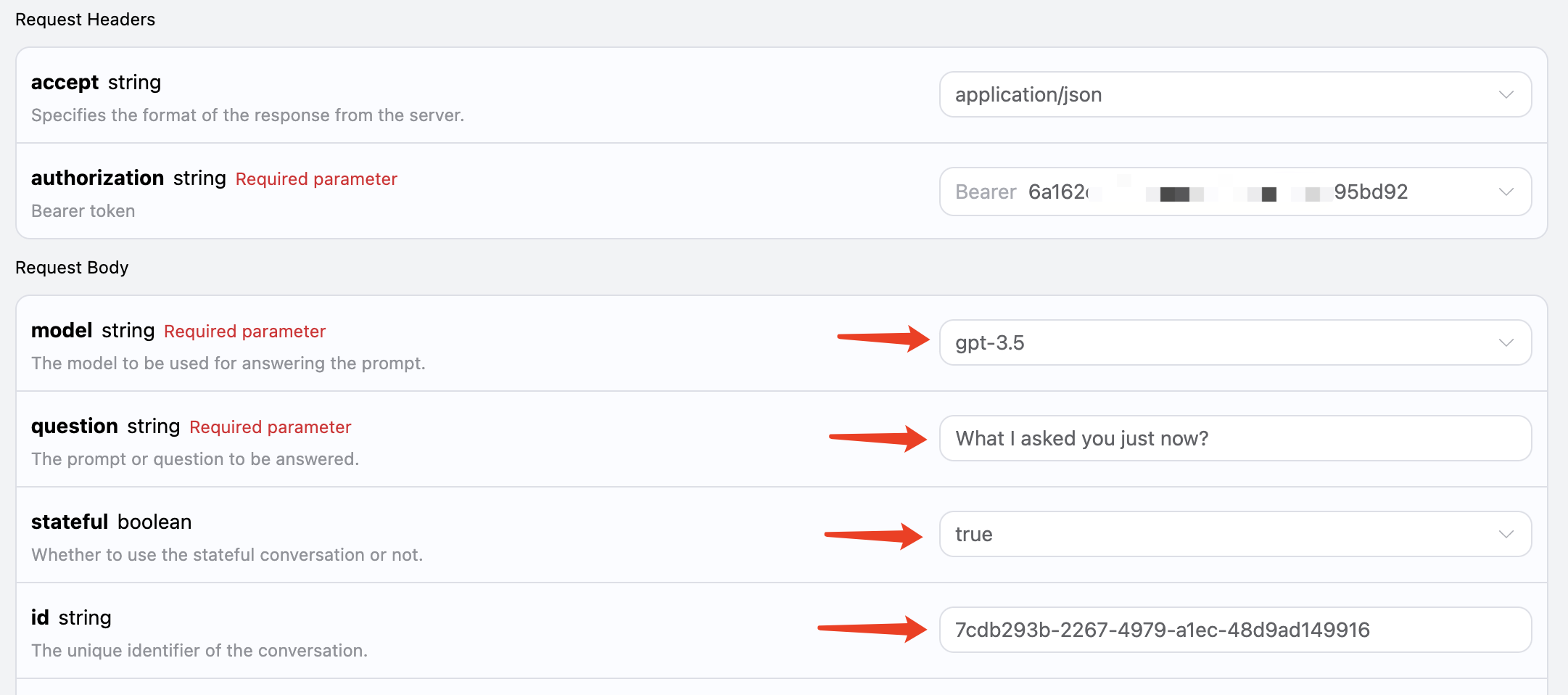 Il codice corrispondente è il seguente:
Il codice corrispondente è il seguente:
Risposta in Streaming
Questa interfaccia supporta anche la risposta in streaming, che è molto utile per l’integrazione web, consentendo di visualizzare il contenuto parola per parola. Se desideri restituire una risposta in streaming, puoi modificare il parametroaccept nell’intestazione della richiesta, impostandolo su application/x-ndjson.
La modifica è mostrata nell’immagine, ma il codice di chiamata deve essere adeguatamente modificato per supportare la risposta in streaming.
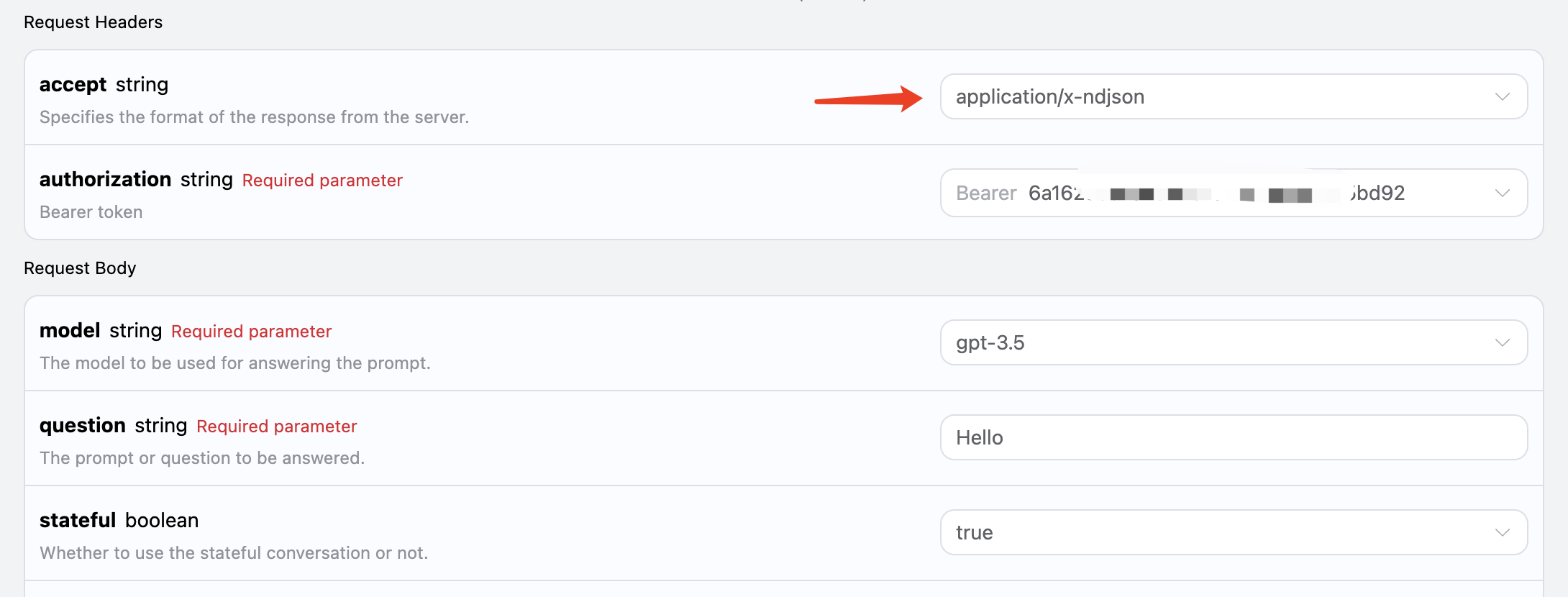 Dopo aver modificato
Dopo aver modificato accept in application/x-ndjson, l’API restituirà i dati JSON riga per riga. A livello di codice, dobbiamo apportare le modifiche necessarie per ottenere i risultati riga per riga.
Esempio di codice di chiamata in Python:
answer che è il contenuto della risposta più recente, delta_answer è il contenuto della risposta aggiunto, puoi integrare i risultati nel tuo sistema.
Anche JavaScript è supportato, ad esempio il codice per la chiamata in streaming di Node.js è il seguente:
Modello predefinito
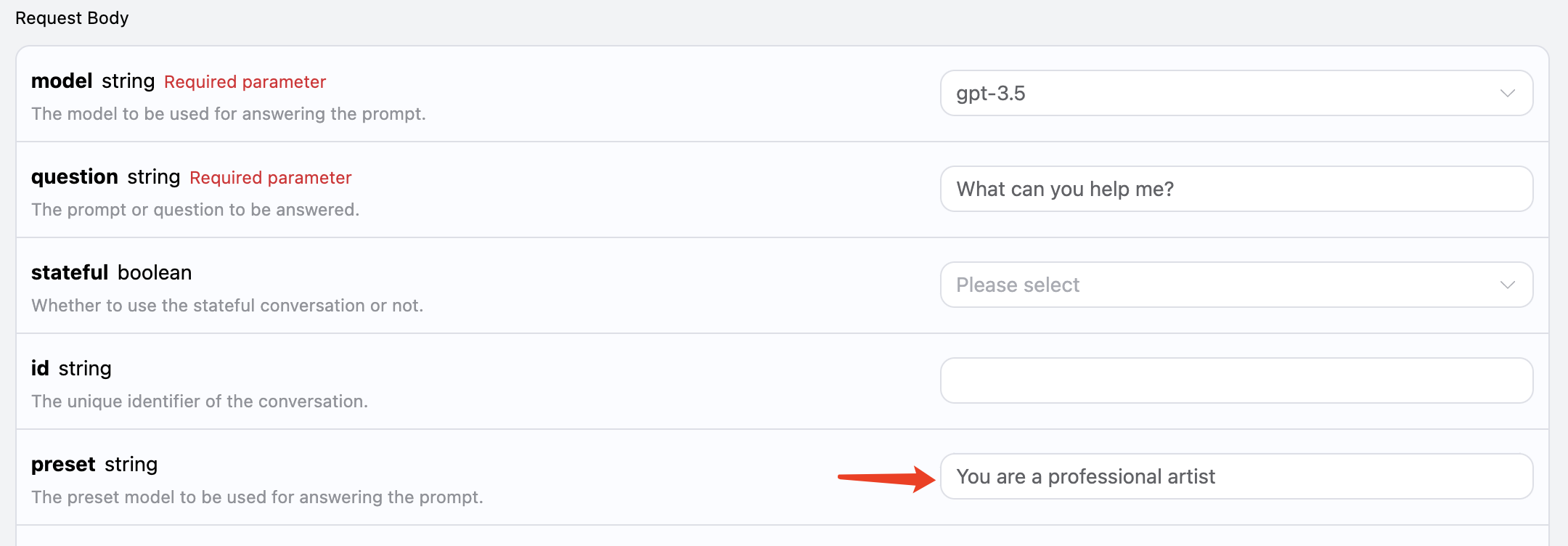
Sappiamo che le API correlate a OpenAI hanno un concetto disystem_prompt, che è impostare un predefinito per l’intero modello, come il suo nome, ecc. Anche questa API di domande e risposte AI espone questo parametro, chiamato preset, utilizzandolo possiamo aggiungere un predefinito al modello, proviamo con un esempio:
Qui aggiungiamo il campo preset, il contenuto è Sei un artista professionista, come mostrato nell’immagine:
 Il codice corrispondente è il seguente:
Il codice corrispondente è il seguente:
Riconoscimento delle immagini
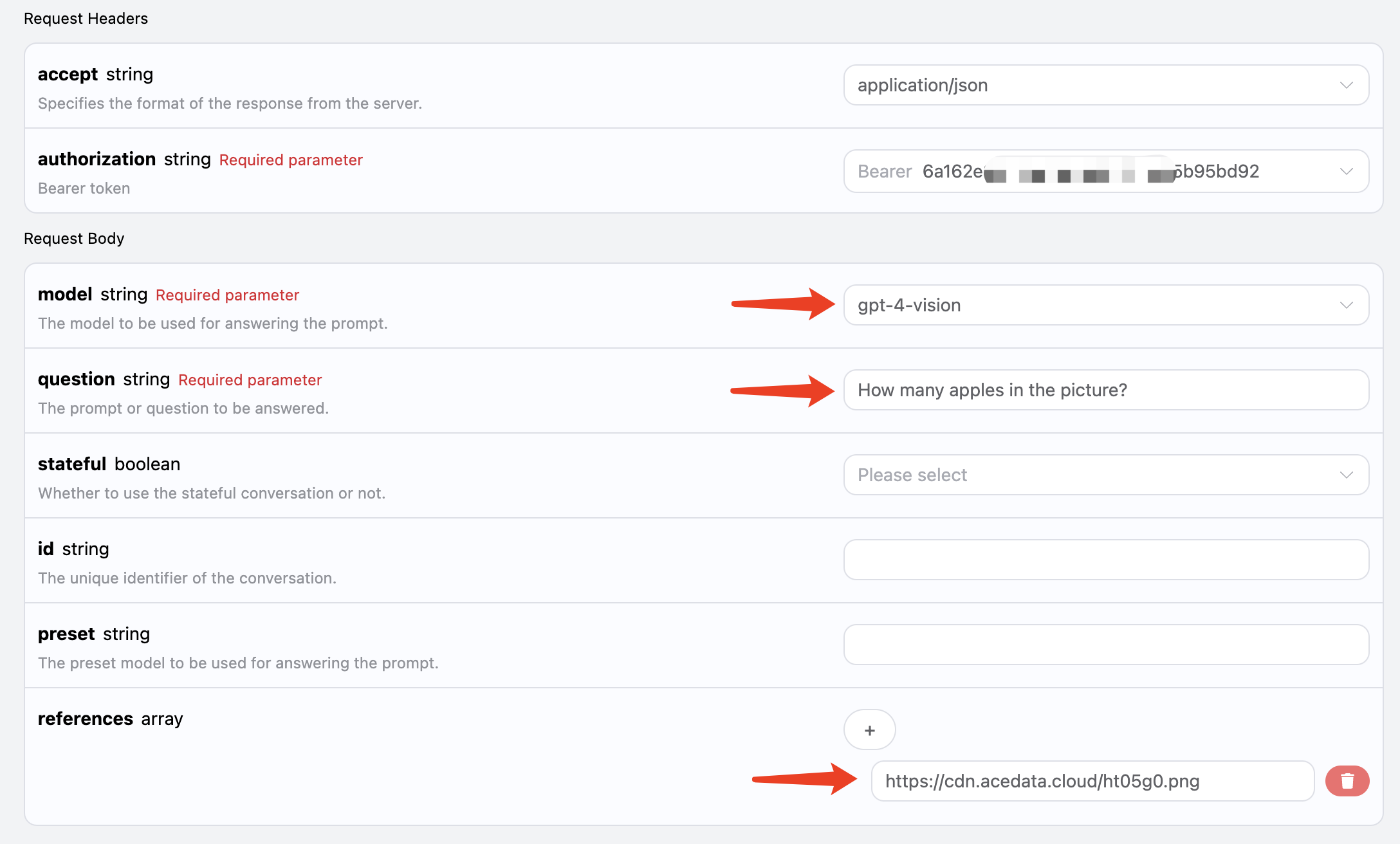
Questa AI supporta anche l’aggiunta di allegati per il riconoscimento delle immagini, passando il link dell’immagine corrispondente tramitereferences, ad esempio ho qui un’immagine di una mela, come mostrato nell’immagine:
 Il link dell’immagine è https://cdn.acedata.cloud/ht05g0.png, possiamo semplicemente passarlo come parametro
Il link dell’immagine è https://cdn.acedata.cloud/ht05g0.png, possiamo semplicemente passarlo come parametro references, e bisogna notare che il modello deve essere scelto per supportare il riconoscimento visivo, attualmente supportato è gpt-4-vision, quindi l’input è il seguente:
 Il codice corrispondente è il seguente:
Il codice corrispondente è il seguente:
Domande e risposte in rete
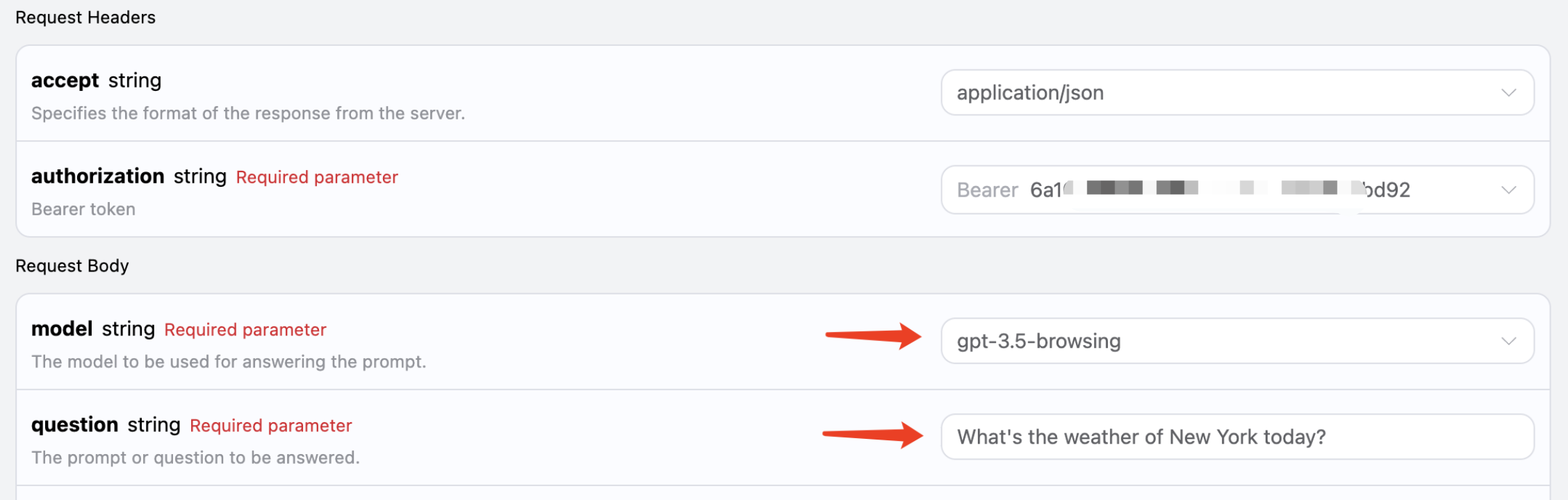
Questa API supporta anche modelli connessi a Internet, inclusi GPT-3.5 e GPT-4, entrambi possono supportare, dietro l’API c’è un processo automatico di ricerca su Internet e sintesi, possiamo scegliere il modello comegpt-3.5-browsing per provare, come mostrato nell’immagine:
 Il codice è il seguente:
Il codice è il seguente:
Se hai requisiti di qualità delle risposte del modello più elevati, puoi cambiare il modello in gpt-4-browsing, la qualità della risposta sarà migliore.