Процесс заявки
Чтобы использовать OpenAI Embeddings API, сначала перейдите на страницу OpenAI Embeddings API и нажмите кнопку «Acquire», чтобы получить необходимые для запроса учетные данные: Если вы еще не вошли в систему или не зарегистрированы, вас автоматически перенаправят на страницу входа, пригласив зарегистрироваться и войти в систему. После входа или регистрации вы автоматически вернетесь на текущую страницу.
При первой подаче заявки вам будет предоставлен бесплатный лимит, который можно использовать для работы с этим API.
Если вы еще не вошли в систему или не зарегистрированы, вас автоматически перенаправят на страницу входа, пригласив зарегистрироваться и войти в систему. После входа или регистрации вы автоматически вернетесь на текущую страницу.
При первой подаче заявки вам будет предоставлен бесплатный лимит, который можно использовать для работы с этим API.
Основное использование
Теперь вы можете заполнить соответствующие поля на интерфейсе, как показано на изображении: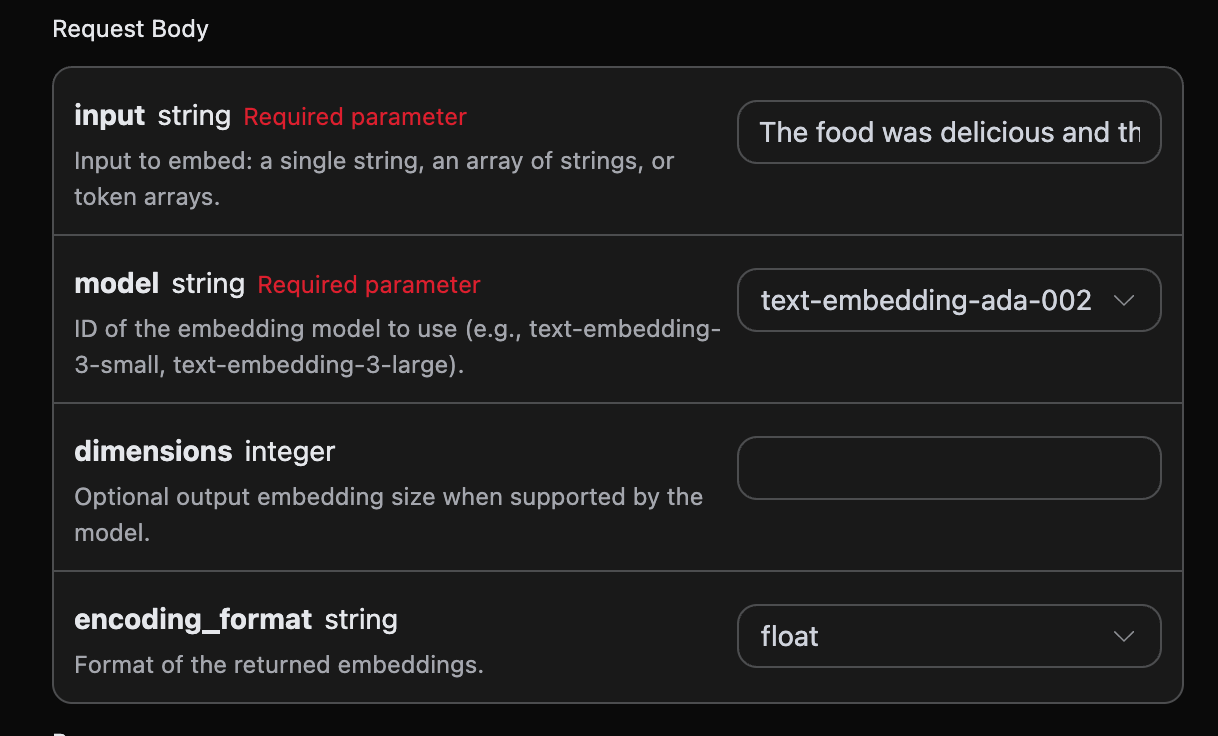
authorization, которое можно выбрать прямо из выпадающего списка. Другой параметр — model, model — это категория модели, которую мы выбираем для использования с сайта OpenAI, здесь у нас в основном есть 3 модели, подробности можно посмотреть в предоставленных моделях. Последний параметр — input, input — это текст, который мы хотим преобразовать в вектор слов.
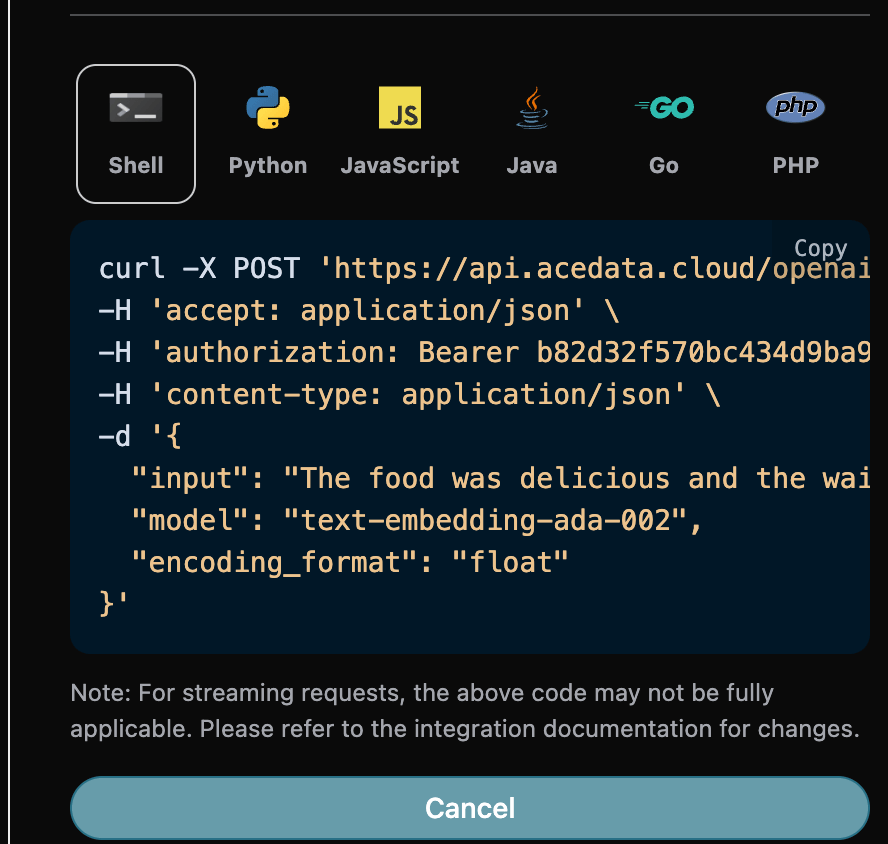
Также вы можете заметить, что справа есть соответствующий код вызова, который вы можете скопировать и запустить, или просто нажать кнопку «Try» для тестирования.
Дополнительные параметры:
dimensions: обрезка размерности вектора, по умолчанию выводится полная размерность.encoding_format: формат возврата, можно выбратьfloatилиbase64.
model, модель, использованная для преобразования текста в вектор слов.usage, информация о токенах, использованных для преобразования текста в вектор слов.data, результат преобразования текста в вектор слов.
data содержит конкретную информацию о векторе слов, соответствующем тексту, а embedding — это конкретный результат сгенерированного вектора слов.
Обработка ошибок
При вызове API, если возникнет ошибка, API вернет соответствующий код ошибки и информацию. Например:400 token_mismatched: Неверный запрос, возможно, из-за отсутствующих или недействительных параметров.400 api_not_implemented: Неверный запрос, возможно, из-за отсутствующих или недействительных параметров.401 invalid_token: Неавторизовано, недействительный или отсутствующий токен авторизации.429 too_many_requests: Слишком много запросов, вы превысили лимит частоты.500 api_error: Внутренняя ошибка сервера, что-то пошло не так на сервере.