申請プロセス
OpenAI Embeddings API を使用するには、まず OpenAI Embeddings API ページにアクセスし、「Acquire」ボタンをクリックして、リクエストに必要な資格情報を取得します: まだログインまたは登録していない場合は、自動的にログインページにリダイレクトされ、登録とログインを促されます。ログインまたは登録後、現在のページに自動的に戻ります。
初回申請時には無料のクレジットが付与され、この API を無料で使用できます。
まだログインまたは登録していない場合は、自動的にログインページにリダイレクトされ、登録とログインを促されます。ログインまたは登録後、現在のページに自動的に戻ります。
初回申請時には無料のクレジットが付与され、この API を無料で使用できます。
基本使用
次に、画面上に対応する内容を入力します。以下の図のように: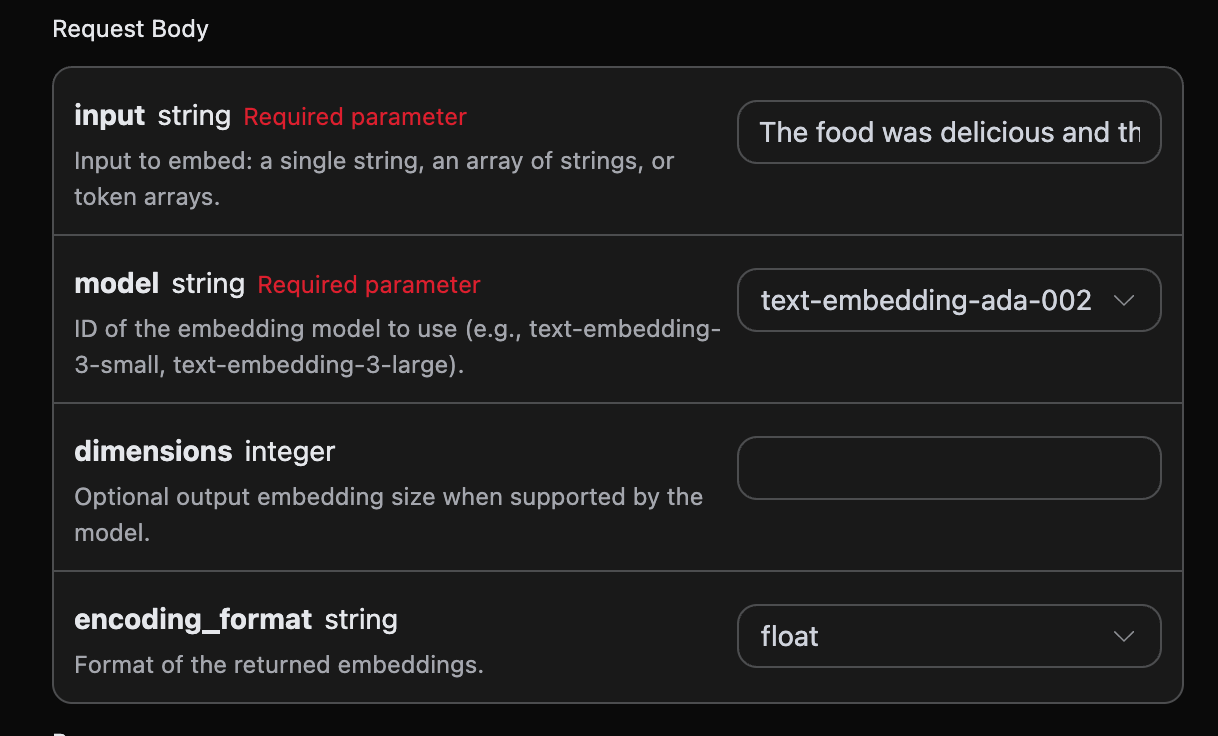
authorization で、ドロップダウンリストから選択できます。もう一つのパラメータは model で、model は OpenAI の公式モデルカテゴリを選択するものです。ここでは主に3種類のモデルがあります。詳細は提供されたモデルを参照してください。最後のパラメータは input で、input は変換する単語ベクトルテキストです。
また、右側には対応する呼び出しコードが生成されていることに注意してください。コードをコピーして直接実行することも、直接「Try」ボタンをクリックしてテストすることもできます。
オプションのパラメータ:
dimensions:ベクトルの次元を切り詰める。デフォルトでは完全な次元を出力します。encoding_format:返却形式。floatまたはbase64のいずれかを選択できます。
model、今回のテキストから単語ベクトルに変換するために使用されたモデル。usage、今回のテキストから単語ベクトルに変換するために使用されたトークン情報。data、テキスト変換後の単語ベクトル結果。
data はテキストに対応する単語ベクトルの具体的な情報を含んでおり、その中の embedding は生成された単語ベクトルの具体的な結果です。
エラー処理
API を呼び出す際にエラーが発生した場合、API は対応するエラーコードと情報を返します。例えば:400 token_mismatched:不正なリクエスト、パラメータが不足しているか無効である可能性があります。400 api_not_implemented:不正なリクエスト、パラメータが不足しているか無効である可能性があります。401 invalid_token:未認証、無効または不足している認証トークン。429 too_many_requests:リクエストが多すぎます、レート制限を超えました。500 api_error:内部サーバーエラー、サーバーで何かがうまくいきませんでした。