messagesフィールドがあり、連続した対話を完了するには、すべてのコンテキスト履歴を渡す必要があり、同時にトークンの制限を超える問題を処理する必要があります。
AceDataCloudが提供するAI Q&A APIは、上記の状況に対して最適化されており、Q&Aの効果を変えずに連続対話の実装をカプセル化しています。接続時にmessagesの渡し方を気にする必要はなく、トークンの制限を超える問題も心配する必要はありません(API内部で自動的に処理されます)。また、対話のクエリ、修正などの機能も提供されており、全体の接続が大幅に簡素化されています。
この文書では、AI Q&A APIの接続説明を紹介します。
申請プロセス
APIを使用するには、まずAI Q&A APIの該当ページでサービスを申請する必要があります。ページに入ったら、「Acquire」ボタンをクリックします。以下の図のように: まだログインまたは登録していない場合は、自動的にログインページにリダイレクトされ、登録とログインを促されます。ログインまたは登録後、現在のページに自動的に戻ります。
初回申請時には無料のクレジットが付与され、このAPIを無料で使用できます。
まだログインまたは登録していない場合は、自動的にログインページにリダイレクトされ、登録とログインを促されます。ログインまたは登録後、現在のページに自動的に戻ります。
初回申請時には無料のクレジットが付与され、このAPIを無料で使用できます。
基本使用
まず、基本的な使用方法を理解します。つまり、質問を入力し、回答を得るためには、単純にquestionフィールドを渡し、対応するモデルを指定するだけです。
たとえば、「What’s your name?」と尋ねる場合、次に画面上に対応する内容を入力できます。以下の図のように:
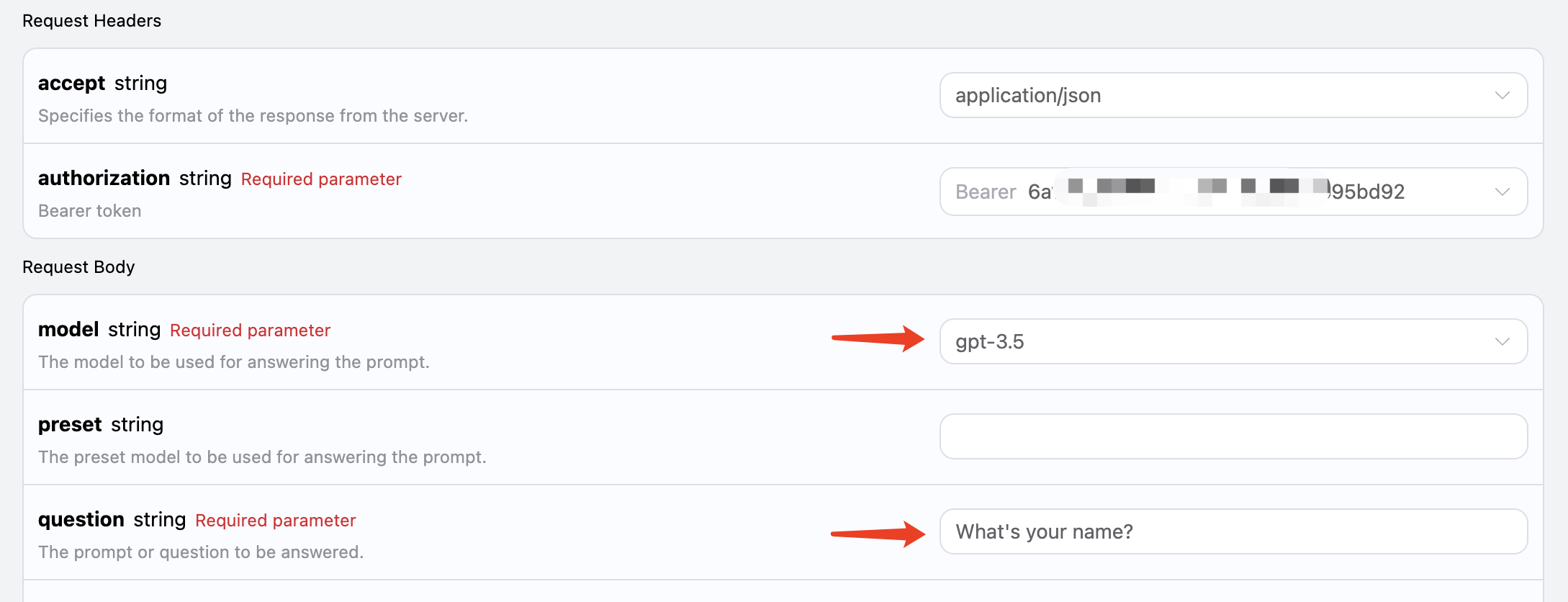 ここでは、リクエストヘッダーを設定しています。含まれるのは:
ここでは、リクエストヘッダーを設定しています。含まれるのは:
accept:受け取りたいレスポンス結果の形式。ここではapplication/json、つまりJSON形式を記入します。authorization:APIを呼び出すためのキー。申請後、直接ドロップダウンから選択できます。
model:モデルの選択。たとえば、主流のGPT 3.5、GPT 4など。question:尋ねたい質問。任意のプレーンテキストで構いません。
answerフィールドがあり、これはその質問の回答です。任意の質問を入力すれば、任意の回答が得られます。
もし多段階の対話のサポートが不要であれば、このAPIは接続を大いに便利にします。
また、対応する接続コードを生成したい場合は、生成されたものを直接コピーできます。たとえば、CURLのコードは以下の通りです:
多段階対話
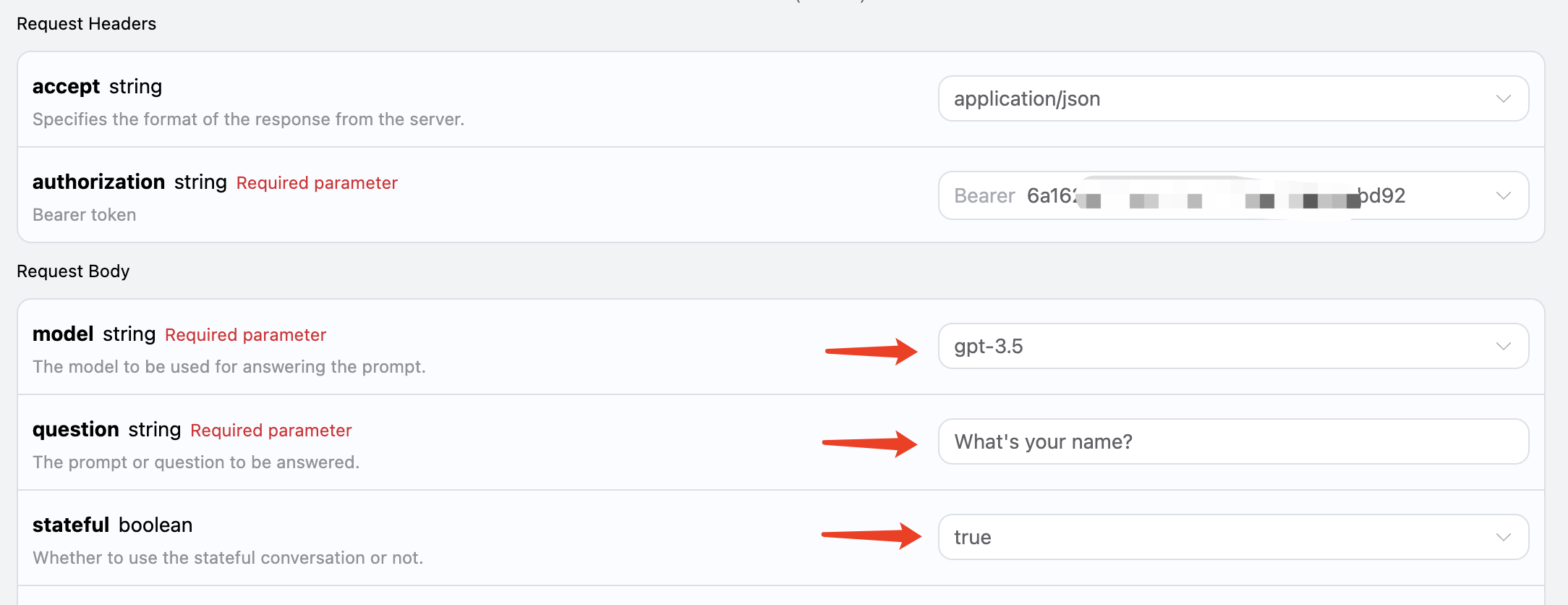
多段階対話機能を接続したい場合は、追加のパラメータstatefulを渡す必要があります。その値はtrueであり、以降の各リクエストにはこのパラメータを含める必要があります。statefulパラメータを渡すと、APIは追加でidパラメータを返し、現在の対話のIDを表します。以降は、このIDをパラメータとして渡すだけで簡単に多段階対話を実現できます。
以下に具体的な操作を示します。
最初のリクエストでは、statefulパラメータをtrueに設定し、modelとquestionパラメータを正常に渡します。以下の図のように:
 対応するコードは以下の通りです:
対応するコードは以下の通りです:
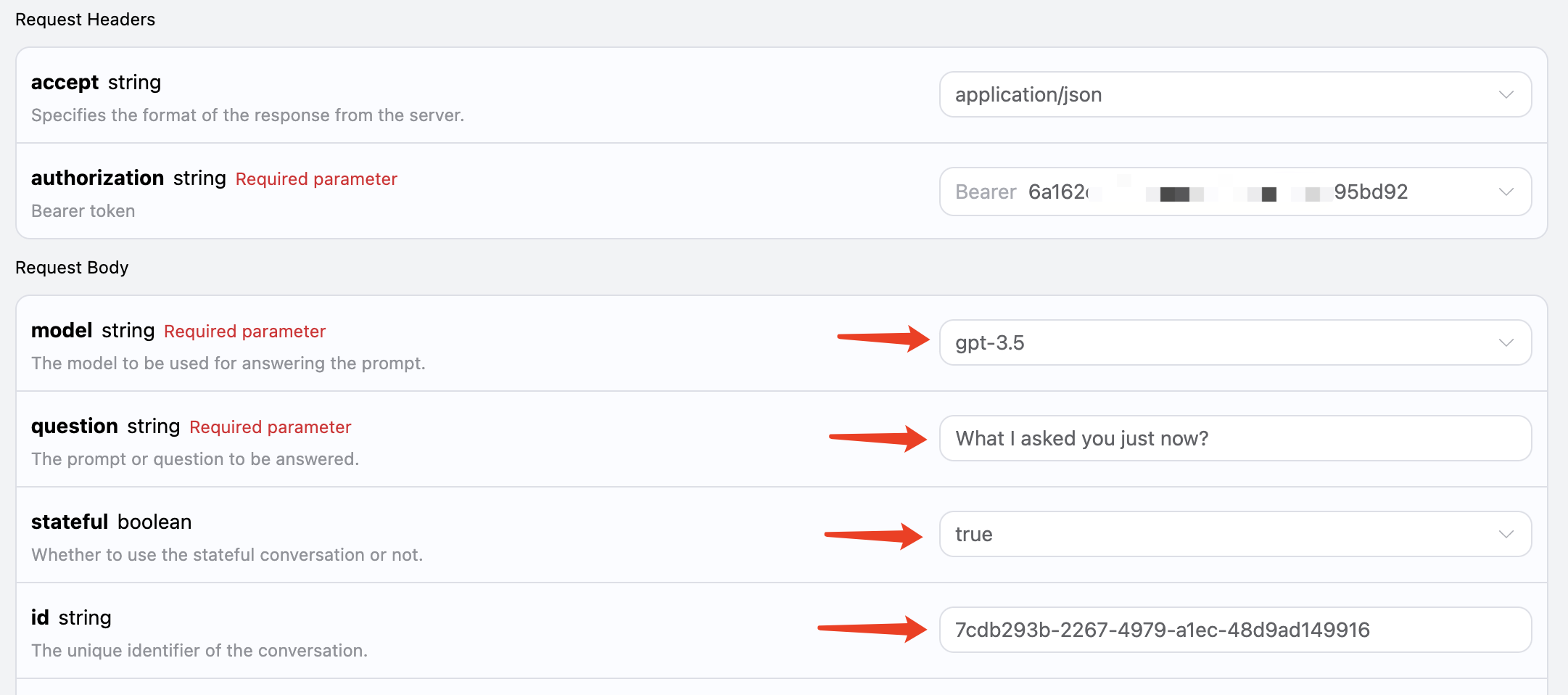
idフィールドをパラメータとして渡し、statefulパラメータは引き続きtrueに設定し、「What I asked you just now?」と尋ねます。以下の図のように:
 対応するコードは以下の通りです:
対応するコードは以下の通りです:
ストリーミングレスポンス
このインターフェースはストリーミングレスポンスもサポートしており、ウェブ接続に非常に便利で、ウェブページで逐次表示効果を実現できます。 ストリーミングでレスポンスを返したい場合は、リクエストヘッダー内のacceptパラメータをapplication/x-ndjsonに変更します。
変更は以下の図のように行いますが、呼び出しコードにはストリーミングレスポンスをサポートするための対応する変更が必要です。
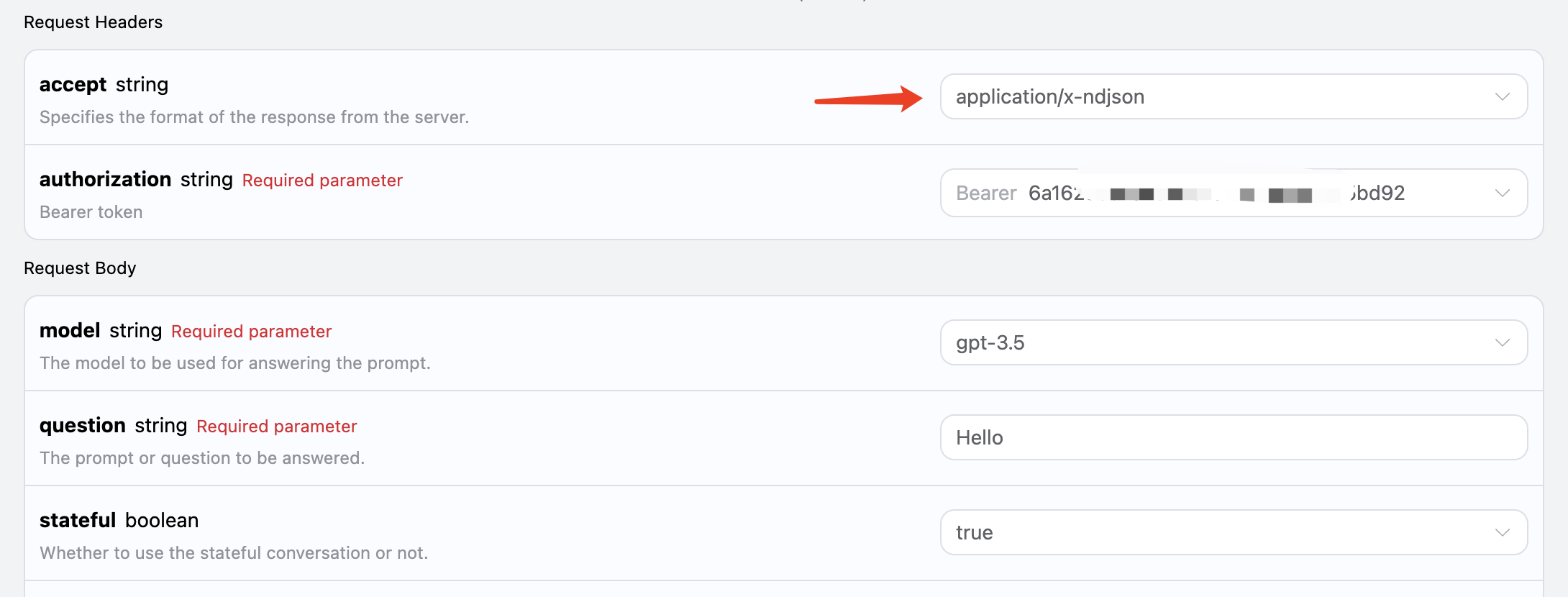
acceptをapplication/x-ndjsonに変更すると、APIは対応するJSONデータを行ごとに返します。コードレベルで逐行の結果を得るために、相応の変更を行う必要があります。
Pythonのサンプル呼び出しコード:
answer は最新の回答内容であり、delta_answer は新たに追加された回答内容です。結果に基づいて、システムに接続することができます。
JavaScript もサポートされています。例えば、Node.js のストリーミング呼び出しコードは以下の通りです:
モデルのプリセット
OpenAI に関連する API には、全体のモデルにプリセットを設定するsystem_prompt の概念があります。例えば、モデルの名前などです。この AI 質問応答 API でもこのパラメータが公開されており、preset と呼ばれています。これを利用してモデルにプリセットを追加できます。例を使って体験してみましょう:
ここで、preset フィールドを追加し、内容を あなたはプロのアーティストです とします。
画像認識
この AI は、添付ファイルを追加して画像認識を行うこともサポートしています。references を通じて対応する画像リンクを渡すだけです。例えば、ここにリンゴの画像があります。
その画像のリンクは https://cdn.acedata.cloud/ht05g0.png で、これを references パラメータとして渡すだけです。同時に、モデルは視覚認識をサポートするモデルを選択する必要があります。現在サポートされているのは gpt-4-vision ですので、入力は以下の通りです:
インターネット質問応答
この API は、インターネットモデルもサポートしています。GPT-3.5、GPT-4 の両方がサポートされており、API の背後には自動的にインターネットを検索し、要約するプロセスがあります。モデルをgpt-3.5-browsing に設定して体験してみましょう。
モデルの回答品質に対する要求が高い場合は、モデルを gpt-4-browsing に変更すると、回答の効果が向上します。