申请流程
لاستخدام OpenAI Embeddings API، يمكنك أولاً الذهاب إلى صفحة OpenAI Embeddings API والنقر على زر “Acquire” للحصول على الشهادات المطلوبة: إذا لم تكن قد قمت بتسجيل الدخول أو التسجيل بعد، سيتم تحويلك تلقائيًا إلى صفحة تسجيل الدخول لدعوتك للتسجيل وتسجيل الدخول، وبعد تسجيل الدخول سيتم العودة تلقائيًا إلى الصفحة الحالية.
عند التقديم لأول مرة، سيكون هناك حد مجاني متاح، يمكنك استخدام هذه API مجانًا.
إذا لم تكن قد قمت بتسجيل الدخول أو التسجيل بعد، سيتم تحويلك تلقائيًا إلى صفحة تسجيل الدخول لدعوتك للتسجيل وتسجيل الدخول، وبعد تسجيل الدخول سيتم العودة تلقائيًا إلى الصفحة الحالية.
عند التقديم لأول مرة، سيكون هناك حد مجاني متاح، يمكنك استخدام هذه API مجانًا.
基本使用
بعد ذلك، يمكنك ملء المحتوى المقابل في الواجهة، كما هو موضح في الصورة: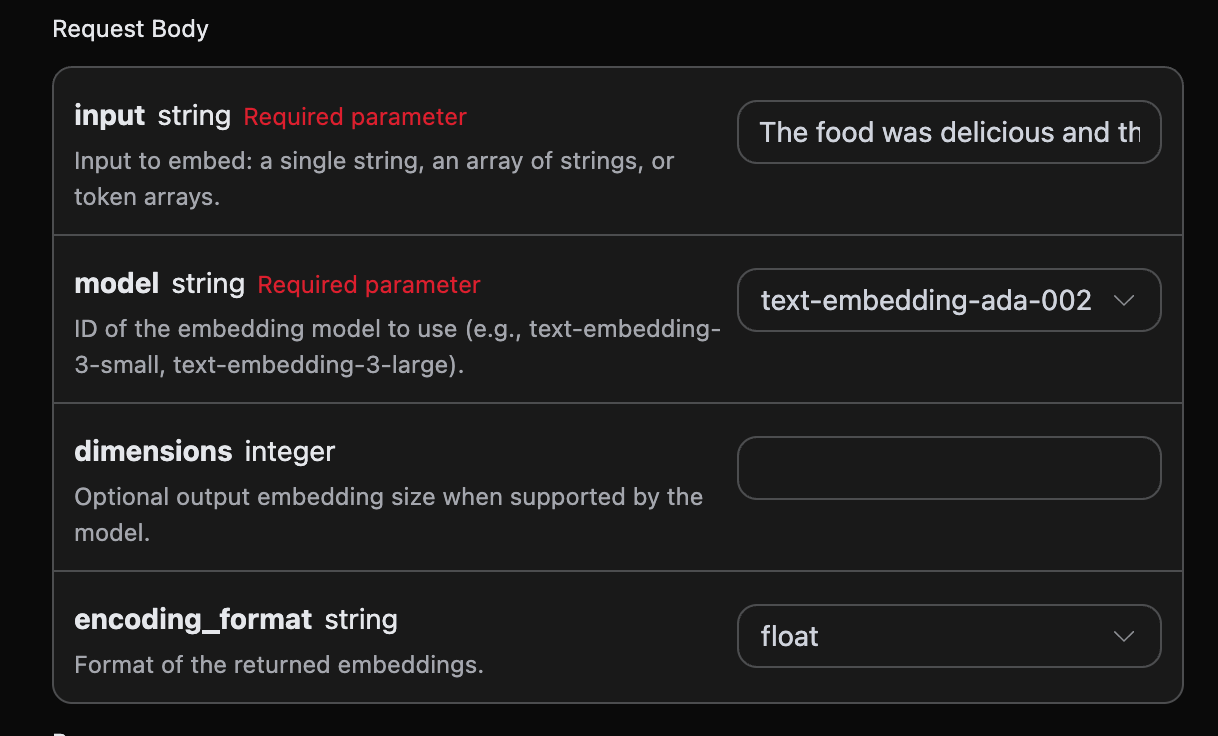
authorization، يمكنك اختياره مباشرة من القائمة المنسدلة. المعامل الآخر هو model، حيث أن model هو نوع النموذج الذي نختار استخدامه من موقع OpenAI الرسمي، هنا لدينا ثلاثة نماذج رئيسية، يمكنك الاطلاع على النماذج التي نقدمها. المعامل الأخير هو input، حيث أن input هو النص الذي نحتاج إلى تحويله إلى تمثيل كلمات.
يمكنك أيضًا ملاحظة أن هناك كود استدعاء متوافق على الجانب الأيمن، يمكنك نسخ الكود وتشغيله مباشرة، أو يمكنك النقر على زر “Try” للاختبار.
可选参数:
dimensions:裁剪向量维度,默认输出完整维度。encoding_format:返回格式,可选float或base64。
model، النموذج المستخدم لتحويل النص إلى تمثيل كلمات.usage، معلومات توكن المستخدمة في تحويل النص إلى تمثيل كلمات.data، نتائج تمثيل الكلمات بعد تحويل النص.
data تحتوي على معلومات دقيقة حول تمثيل الكلمات للنص، وembedding هو النتيجة المحددة للتمثيل.
错误处理
عند استدعاء API، إذا واجهت خطأ، ستقوم API بإرجاع رمز الخطأ والمعلومات ذات الصلة. على سبيل المثال:400 token_mismatched:طلب غير صحيح، ربما بسبب معلمات مفقودة أو غير صالحة.400 api_not_implemented:طلب غير صحيح، ربما بسبب معلمات مفقودة أو غير صالحة.401 invalid_token:غير مصرح به، رمز التفويض غير صالح أو مفقود.429 too_many_requests:عدد كبير جدًا من الطلبات، لقد تجاوزت الحد الأقصى للطلبات.500 api_error:خطأ في الخادم الداخلي، حدث خطأ ما على الخادم.