Процес заявки
Щоб використовувати OpenAI Embeddings API, спочатку можна перейти на сторінку OpenAI Embeddings API і натиснути кнопку «Acquire», щоб отримати необхідні для запиту облікові дані: Якщо ви ще не увійшли в систему або не зареєстровані, вас автоматично перенаправлять на сторінку входу, запрошуючи вас зареєструватися та увійти. Після входу або реєстрації ви автоматично повернетеся на цю сторінку.
При першій заявці буде надано безкоштовний ліміт, який дозволяє безкоштовно використовувати цей API.
Якщо ви ще не увійшли в систему або не зареєстровані, вас автоматично перенаправлять на сторінку входу, запрошуючи вас зареєструватися та увійти. Після входу або реєстрації ви автоматично повернетеся на цю сторінку.
При першій заявці буде надано безкоштовний ліміт, який дозволяє безкоштовно використовувати цей API.
Основне використання
Далі ви можете заповнити відповідні поля на інтерфейсі, як показано на малюнку: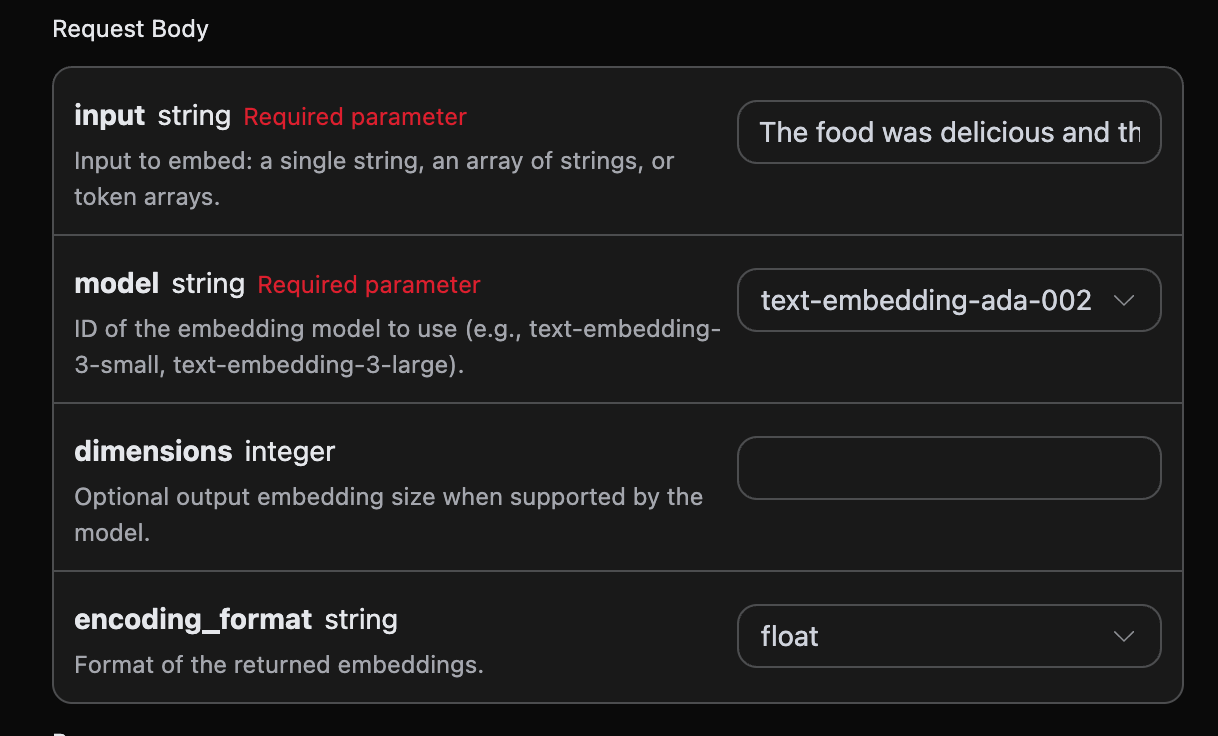
authorization, яке можна вибрати безпосередньо зі списку. Інший параметр - model, model - це категорія моделі, яку ми вибираємо для використання з сайту OpenAI, тут у нас є 3 основні моделі, деталі можна переглянути в наданих моделях. Останній параметр - input, input - це текст, який ми хочемо перетворити на вектор слів.
Також ви можете помітити, що праворуч є відповідний код виклику, який ви можете скопіювати та запустити, або просто натиснути кнопку «Try» для тестування.
Додаткові параметри:
dimensions: обрізка розмірності вектора, за замовчуванням виводиться повна розмірність.encoding_format: формат повернення, можна вибратиfloatабоbase64.
model, модель, що використовується для перетворення тексту на вектор слів.usage, інформація про токени, що використовуються для перетворення тексту на вектор слів.data, результати перетворення тексту на вектори слів.
data міститься конкретна інформація про вектори слів, а embedding - це конкретні результати згенерованих векторів слів.
Обробка помилок
При виклику API, якщо виникає помилка, API повертає відповідний код помилки та інформацію. Наприклад:400 token_mismatched: Неправильний запит, можливо, через відсутні або недійсні параметри.400 api_not_implemented: Неправильний запит, можливо, через відсутні або недійсні параметри.401 invalid_token: Неавторизовано, недійсний або відсутній токен авторизації.429 too_many_requests: Занадто багато запитів, ви перевищили ліміт запитів.500 api_error: Внутрішня помилка сервера, щось пішло не так на сервері.