Proces aplikacji
Aby skorzystać z API, należy najpierw przejść do strony Wan Videos Generation API i złożyć wniosek o odpowiednią usługę. Po wejściu na stronę, kliknij przycisk „Acquire”, jak pokazano na obrazku: Jeśli nie jesteś zalogowany lub zarejestrowany, automatycznie zostaniesz przekierowany na stronę logowania, aby zarejestrować się i zalogować. Po zalogowaniu lub rejestracji automatycznie wrócisz na bieżącą stronę.
Podczas pierwszej aplikacji otrzymasz darmowy limit, który pozwala na bezpłatne korzystanie z tego API.
Jeśli nie jesteś zalogowany lub zarejestrowany, automatycznie zostaniesz przekierowany na stronę logowania, aby zarejestrować się i zalogować. Po zalogowaniu lub rejestracji automatycznie wrócisz na bieżącą stronę.
Podczas pierwszej aplikacji otrzymasz darmowy limit, który pozwala na bezpłatne korzystanie z tego API.
Podstawowe użycie
Najpierw zapoznaj się z podstawowym sposobem użycia, czyli wprowadzeniem słowa kluczowegoprompt, działania action, linku do obrazu referencyjnego image_url oraz modelu model, aby uzyskać przetworzony wynik. Najpierw musisz przekazać pole action, którego wartość to text2video. Zawiera ono dwa rodzaje działań: generowanie wideo z tekstu (text2video) oraz generowanie wideo z obrazu (image2video). Następnie musimy wprowadzić model model, który obecnie obejmuje modele wan2.6-i2v, wan2.6-r2v, wan2.6-i2v-flash, wan2.6-t2v, szczegóły są następujące:
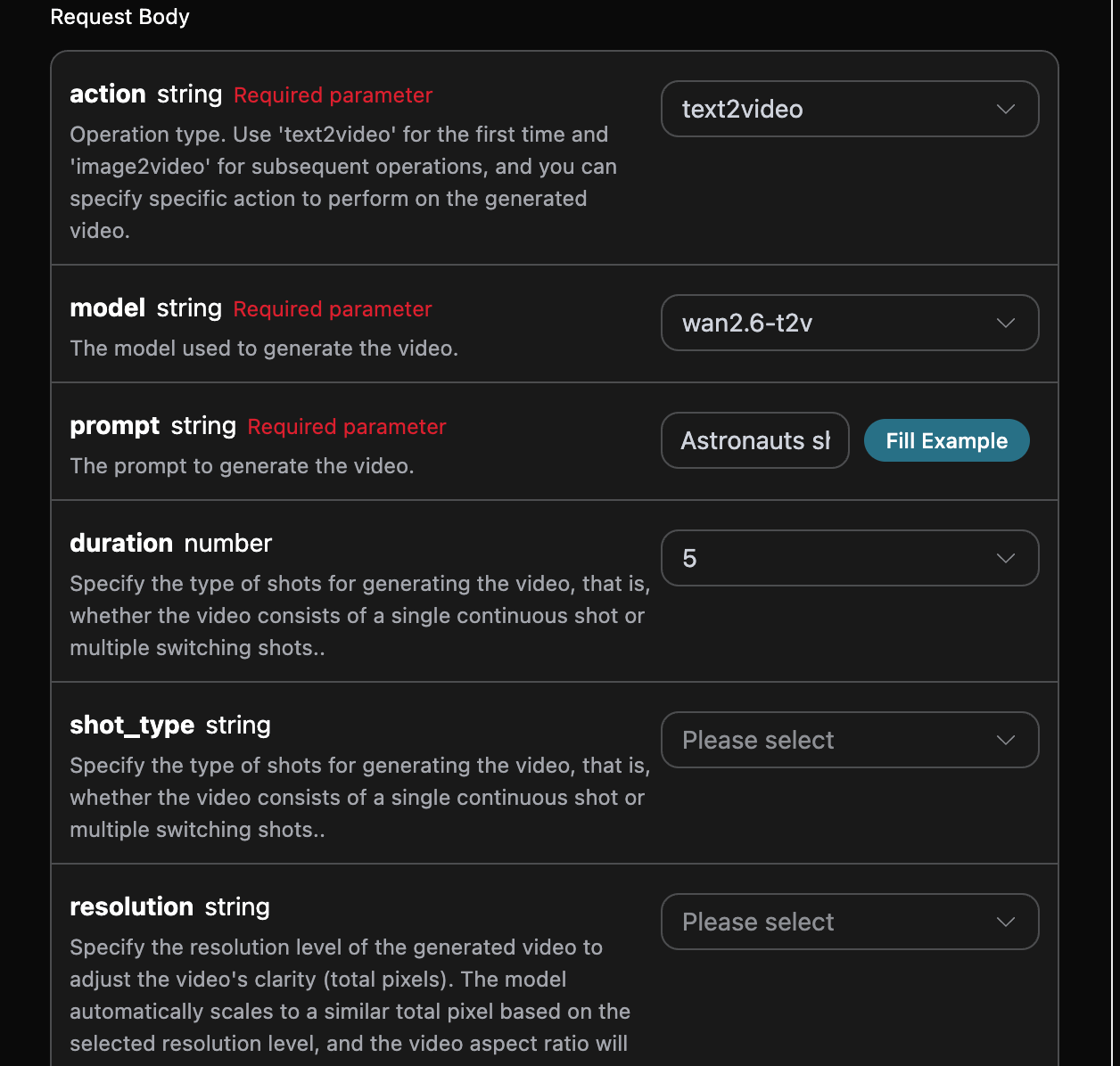
accept: jakiego formatu odpowiedzi oczekujesz, tutaj wpiszapplication/json, czyli format JSON.authorization: klucz do wywołania API, po złożeniu wniosku można go bezpośrednio wybrać z rozwijanej listy.
model: model do generowania wideo, główniewan2.6-i2v,wan2.6-r2v,wan2.6-i2v-flash,wan2.6-t2v.action: działanie związane z generowaniem wideo, głównie obejmujące trzy rodzaje działań: generowanie wideo z tekstu (text2video), generowanie wideo z obrazu (image2video). W przypadku generowania wideo z tekstu obecnie obsługiwany jest tylko modelwan2.6-t2v, a w przypadku generowania wideo z obrazu obsługiwane są modelewan2.6-i2v,wan2.6-r2v,wan2.6-i2v-flash.image_url: w przypadku wyboru działania generowania wideo z obrazuimage2videokonieczne jest przesłanie linku do obrazu referencyjnego, obecnie obsługiwane są modelewan2.6-i2v,wan2.6-i2v-flash.reference_video_urls: opcjonalne w przypadku generowania wideo z obrazu, określa linki do referencyjnych filmów do generacji, obecnie obsługiwany jest modelwan2.6-r2v.size: określa rozdzielczość generowanego wideo, format to szerokość*wysokość. Domyślna wartość tego parametru oraz dostępne wartości enum zależą od parametru modelu, szczegółowe zasady można znaleźć w dokumentacji.duration: czas trwania generowanego wideo, głównie obsługiwane wartości to 5, 10, 15.shot_type: opcjonalne, określa typ ujęcia generowanego wideo, czyli czy wideo składa się z jednego ciągłego ujęcia, czy z wielu przełączających się ujęć. Warunki działania: działa tylko wtedy, gdy “prompt_extend”: true. Priorytet parametrów: shot_type > prompt. Na przykład, jeśli shot_type jest ustawione na “single”, nawet jeśli prompt zawiera „generuj wideo z wieloma ujęciami”, model nadal wygeneruje wideo z jednym ujęciem, szczegółowe zasady można znaleźć w dokumentacji.negative_prompt: opcjonalne, odwrotne słowo kluczowe, używane do opisu treści, których nie chcemy widzieć w obrazie wideo, może ograniczać obraz wideo. Obsługuje język chiński i angielski, długość nie przekracza 500 znaków, nadmiar zostanie automatycznie obcięty. Przykładowe wartości: niska rozdzielczość, błędy, najgorsza jakość, niska jakość, uszkodzenia, nadmiarowe palce, złe proporcje itp.resolution: określa poziom rozdzielczości generowanego wideo, używany do dostosowania ostrości wideo (całkowita liczba pikseli). Model automatycznie skaluje do zbliżonej całkowitej liczby pikseli w zależności od wybranego poziomu rozdzielczości, a proporcje wideo będą starały się zachować zgodność z proporcjami obrazu img_url, więcej informacji można znaleźć w dokumentacji.audio_url: URL pliku audio, model użyje tego audio do generowania wideo. Sposób użycia można znaleźć w dokumentacji.audio: czy generować wideo z dźwiękiem. Priorytet parametrów: audio > audio_url. Gdy audio=false, nawet jeśli podano audio_url, wynik nadal będzie wideo bez dźwięku, a opłaty będą naliczane jak za wideo bez dźwięku, domyślna wartość to true.prompt_extend: czy włączyć inteligentne przekształcanie promptów. Po włączeniu używa dużego modelu do inteligentnego przekształcania wprowadzonego promptu. Dla krótszych promptów efekty generacji są znacznie lepsze, ale zwiększa to czas przetwarzania, domyślna wartość to true.prompt: słowo kluczowe.callback_url: URL, na który mają być zwracane wyniki.
success, status zadania generowania wideo.task_id, ID zadania generowania wideo.video_url, link do wideo wygenerowanego w ramach zadania.state, status zadania generowania wideo.
video_url w wyniku.
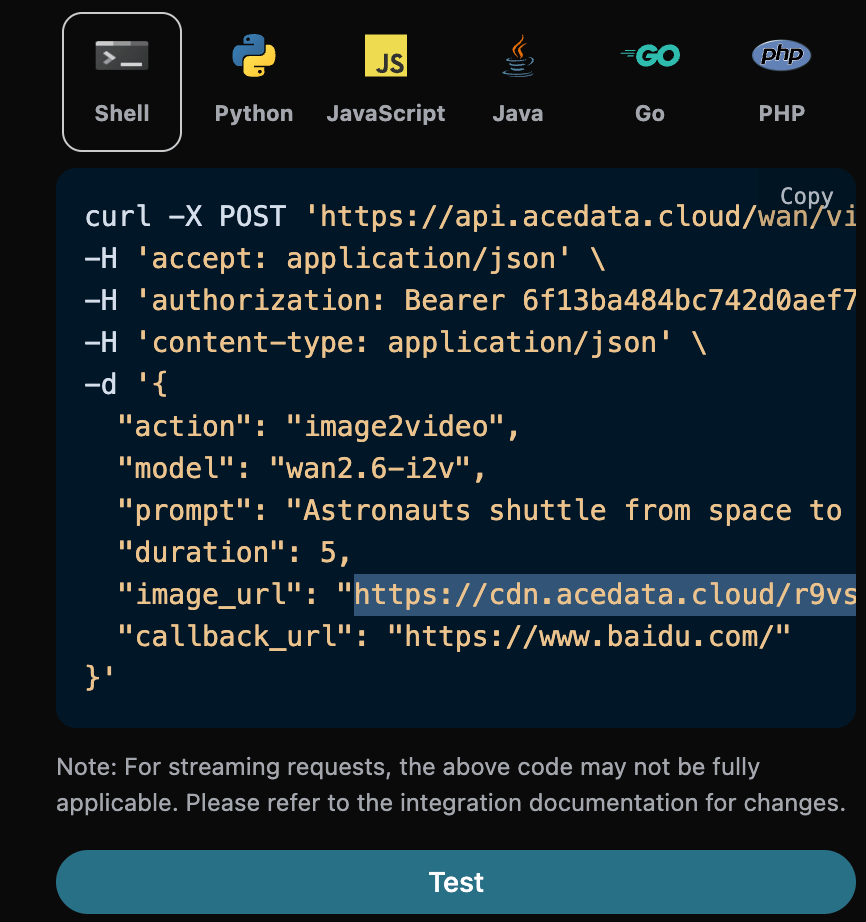
Dodatkowo, jeśli chcesz wygenerować odpowiedni kod integracyjny, możesz go bezpośrednio skopiować, na przykład kod CURL wygląda następująco:
Funkcja generowania wideo z obrazu
Jeśli chcesz wygenerować wideo na podstawie obrazu referencyjnego lub wideo referencyjnego, możesz ustawić parametraction na image2video, a następnie wprowadzić link do obrazu referencyjnego lub link do wideo referencyjnego. Następnie musimy wypełnić kolejne wymagane słowa kluczowe, aby dostosować generowane wideo, co pozwala na określenie następujących treści:
model: model generujący wideo, główniewan2.6-i2v,wan2.6-r2v,wan2.6-i2v-flash,wan2.6-t2v.image_url: gdy wybierasz działanie generowania wideo z obrazuimage2video, musisz przesłać link do referencyjnego obrazu klatki początkowej, obecnie obsługiwane są tylko modelewan2.6-i2v,wan2.6-i2v-flash.reference_video_urls: opcjonalne podczas generowania wideo z obrazu, określa link do referencyjnego wideo, obecnie obsługiwane są tylko modelewan2.6-r2v.prompt: słowa kluczowe.
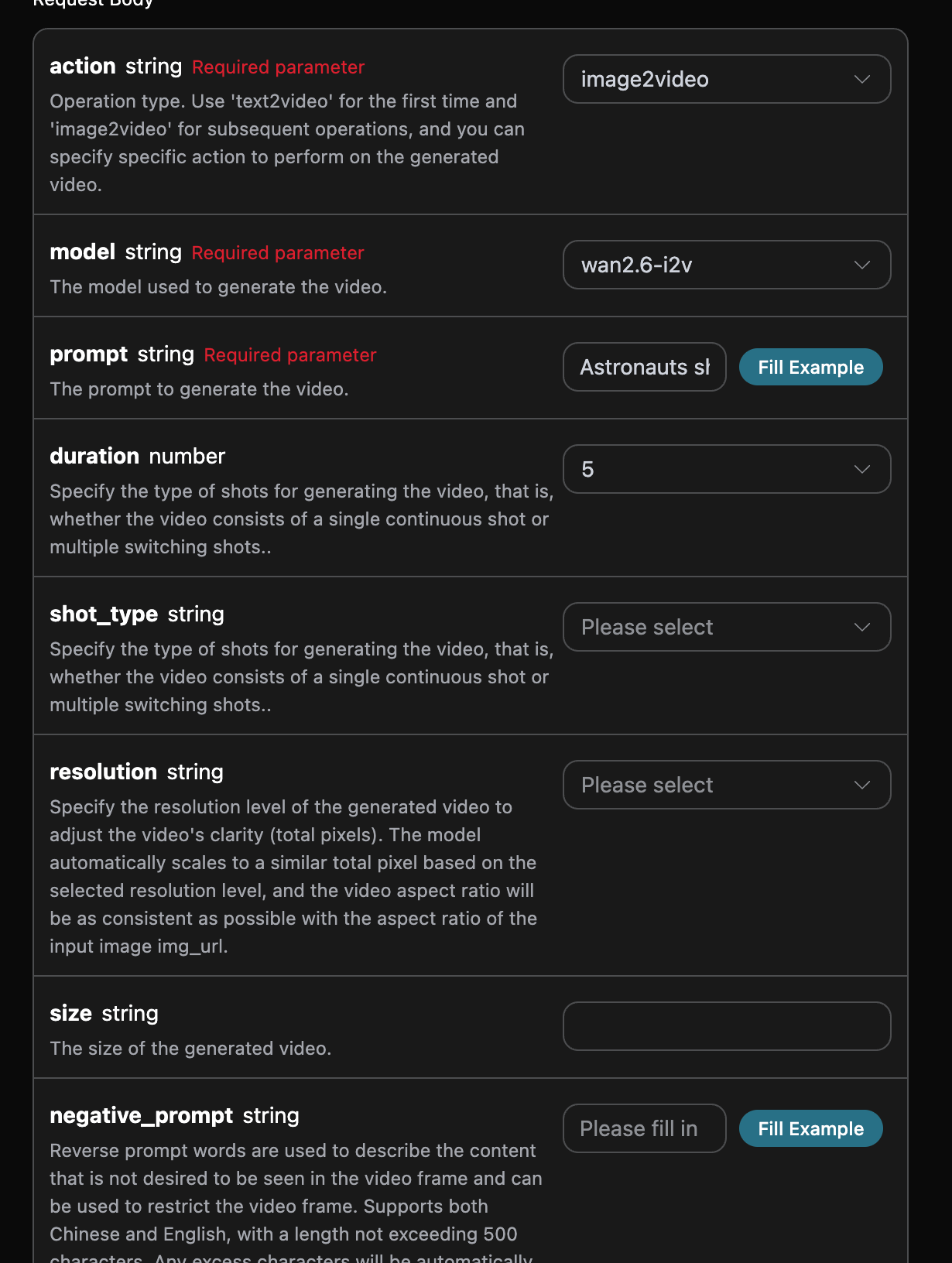
Asynchroniczny callback
Ponieważ czas generacji API Wan Videos jest stosunkowo długi, wynosi około 1-2 minut, jeśli API nie odpowiada przez dłuższy czas, żądanie HTTP będzie utrzymywać połączenie, co prowadzi do dodatkowego zużycia zasobów systemowych, dlatego to API oferuje również wsparcie dla asynchronicznych callbacków. Cały proces polega na tym, że gdy klient wysyła żądanie, dodatkowo określa polecallback_url. Po wysłaniu żądania API natychmiast zwraca wynik, zawierający pole task_id, które reprezentuje bieżące ID zadania. Po zakończeniu zadania wynik generowania wideo zostanie wysłany do określonego przez klienta callback_url w formie POST JSON, w tym również pole task_id, co pozwala na powiązanie wyników zadania za pomocą ID.
Poniżej przedstawiamy przykład, aby zrozumieć, jak to działa.
Po pierwsze, callback Webhook to usługa, która może odbierać żądania HTTP, deweloperzy powinni zastąpić to URL swojego serwera HTTP. W celu wygodnej demonstracji używamy publicznej strony przykładowej Webhook https://webhook.site/, otwierając tę stronę można uzyskać URL Webhook, jak pokazano na obrazku:
 Skopiuj ten URL, aby użyć go jako Webhook, przykładowy URL to
Skopiuj ten URL, aby użyć go jako Webhook, przykładowy URL to https://webhook.site/624b2c78-6dbd-4618-9d2b-b32eade6d8c3.
Następnie możemy ustawić pole callback_url na powyższy URL Webhook, a także wprowadzić odpowiednie parametry, szczegóły jak na obrazku:
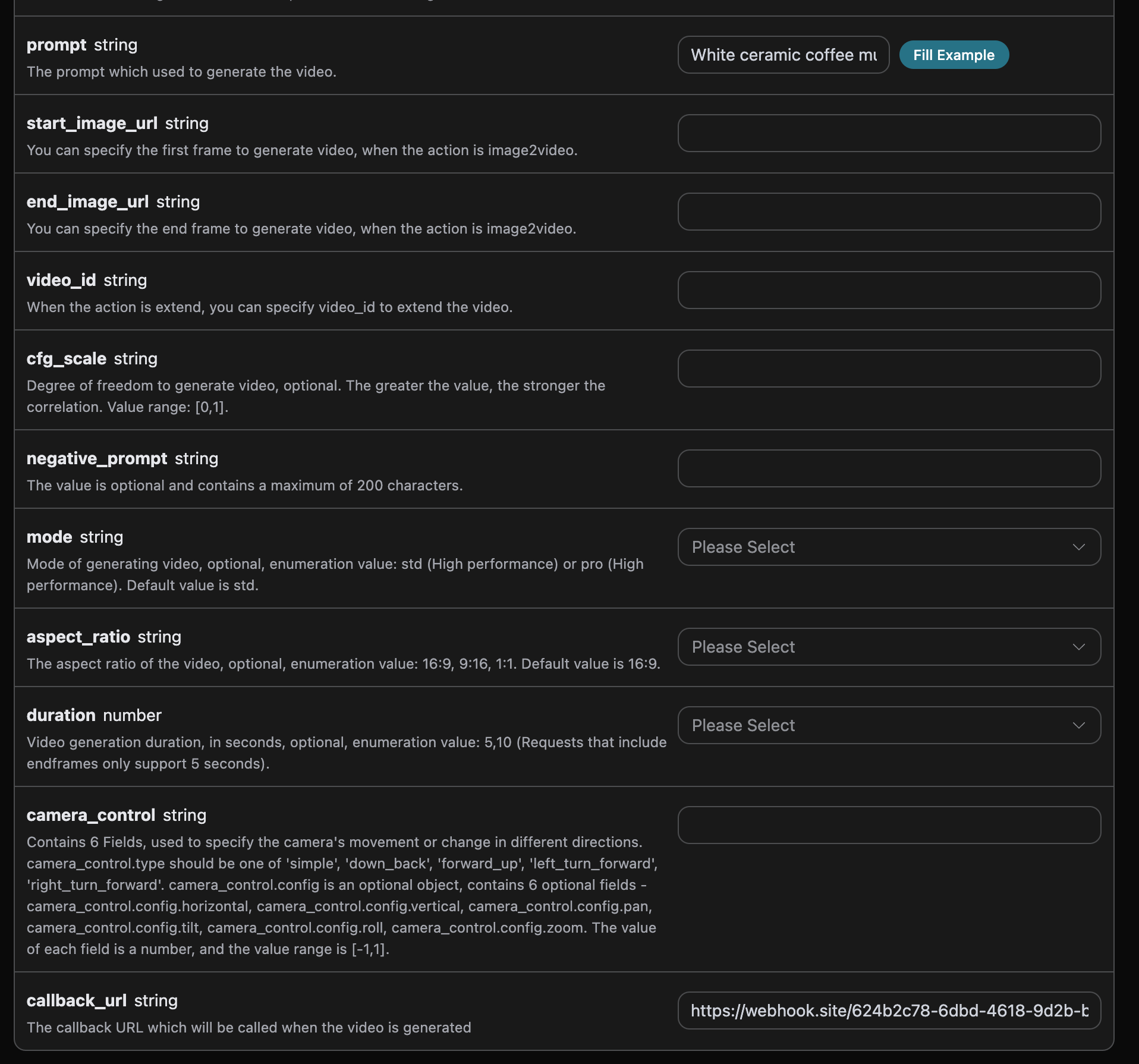
https://webhook.site/624b2c78-6dbd-4618-9d2b-b32eade6d8c3 zaobserwować wynik generowania wideo, jak pokazano na obrazku:
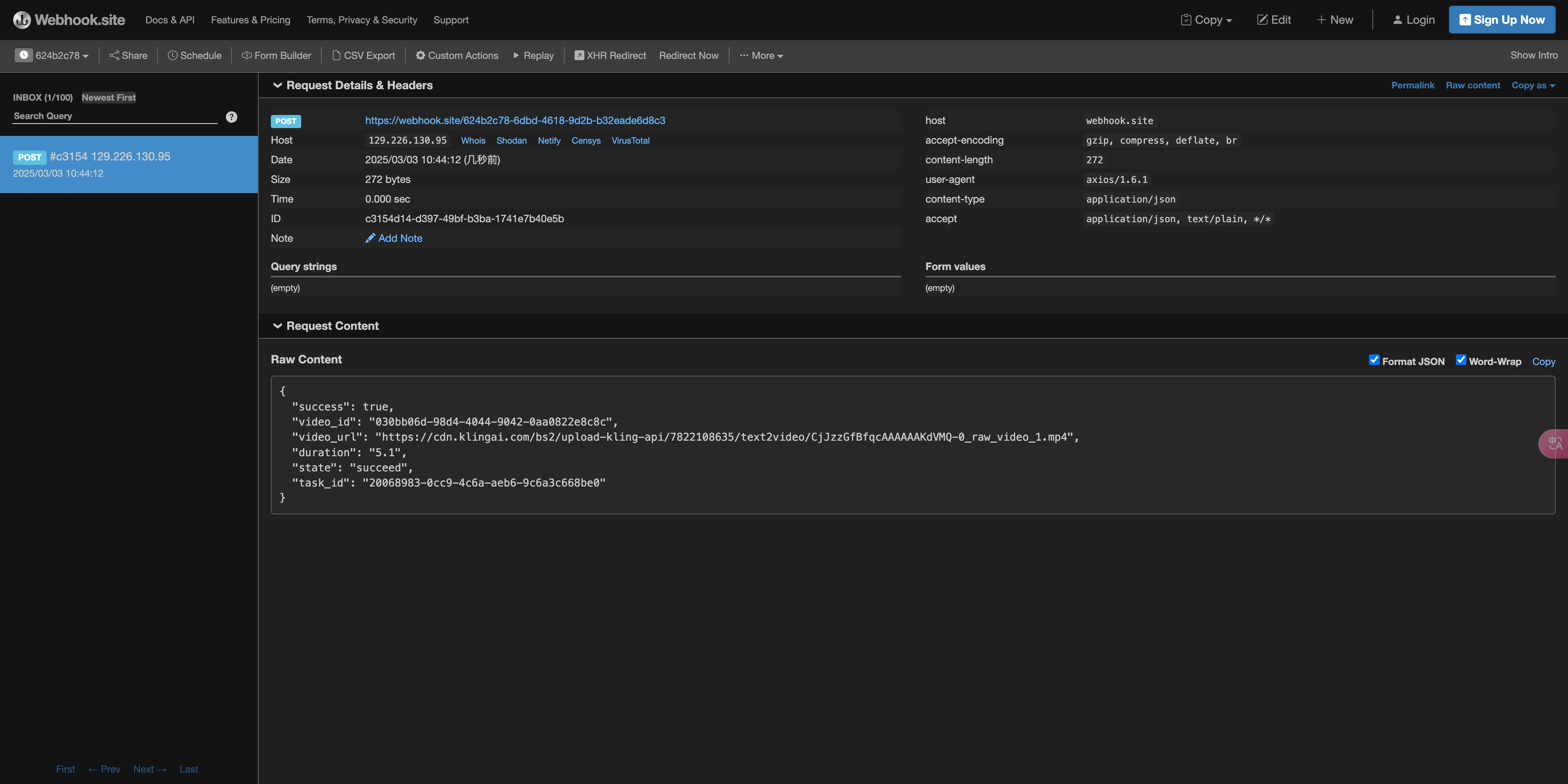 Treść wygląda następująco:
Treść wygląda następująco:
task_id, a pozostałe pola są podobne do powyższych, dzięki czemu można powiązać zadania za pomocą tego pola.
Obsługa błędów
Podczas wywoływania API, jeśli wystąpią błędy, API zwróci odpowiedni kod błędu i informacje. Na przykład:400 token_mismatched: Złe żądanie, prawdopodobnie z powodu brakujących lub nieprawidłowych parametrów.400 api_not_implemented: Złe żądanie, prawdopodobnie z powodu brakujących lub nieprawidłowych parametrów.401 invalid_token: Nieautoryzowany, nieprawidłowy lub brakujący token autoryzacji.429 too_many_requests: Zbyt wiele żądań, przekroczono limit szybkości.500 api_error: Błąd wewnętrzny serwera, coś poszło nie tak na serwerze.