申请流程
لاستخدام واجهة برمجة تطبيقات Midjourney Imagine، يمكنك أولاً زيارة صفحة Midjourney Imagine API والنقر على زر “Acquire” للحصول على الشهادات المطلوبة: إذا لم تكن قد قمت بتسجيل الدخول أو التسجيل بعد، فسيتم تحويلك تلقائيًا إلى صفحة تسجيل الدخول لدعوتك للتسجيل وتسجيل الدخول، وبعد تسجيل الدخول، سيتم إرجاعك تلقائيًا إلى الصفحة الحالية.
عند التقديم لأول مرة، ستحصل على رصيد مجاني يمكن استخدامه مجانًا مع هذه الواجهة.
إذا لم تكن قد قمت بتسجيل الدخول أو التسجيل بعد، فسيتم تحويلك تلقائيًا إلى صفحة تسجيل الدخول لدعوتك للتسجيل وتسجيل الدخول، وبعد تسجيل الدخول، سيتم إرجاعك تلقائيًا إلى الصفحة الحالية.
عند التقديم لأول مرة، ستحصل على رصيد مجاني يمكن استخدامه مجانًا مع هذه الواجهة.
基本使用
بعد ذلك، يمكنك ملء المحتوى المقابل في الواجهة، كما هو موضح في الصورة: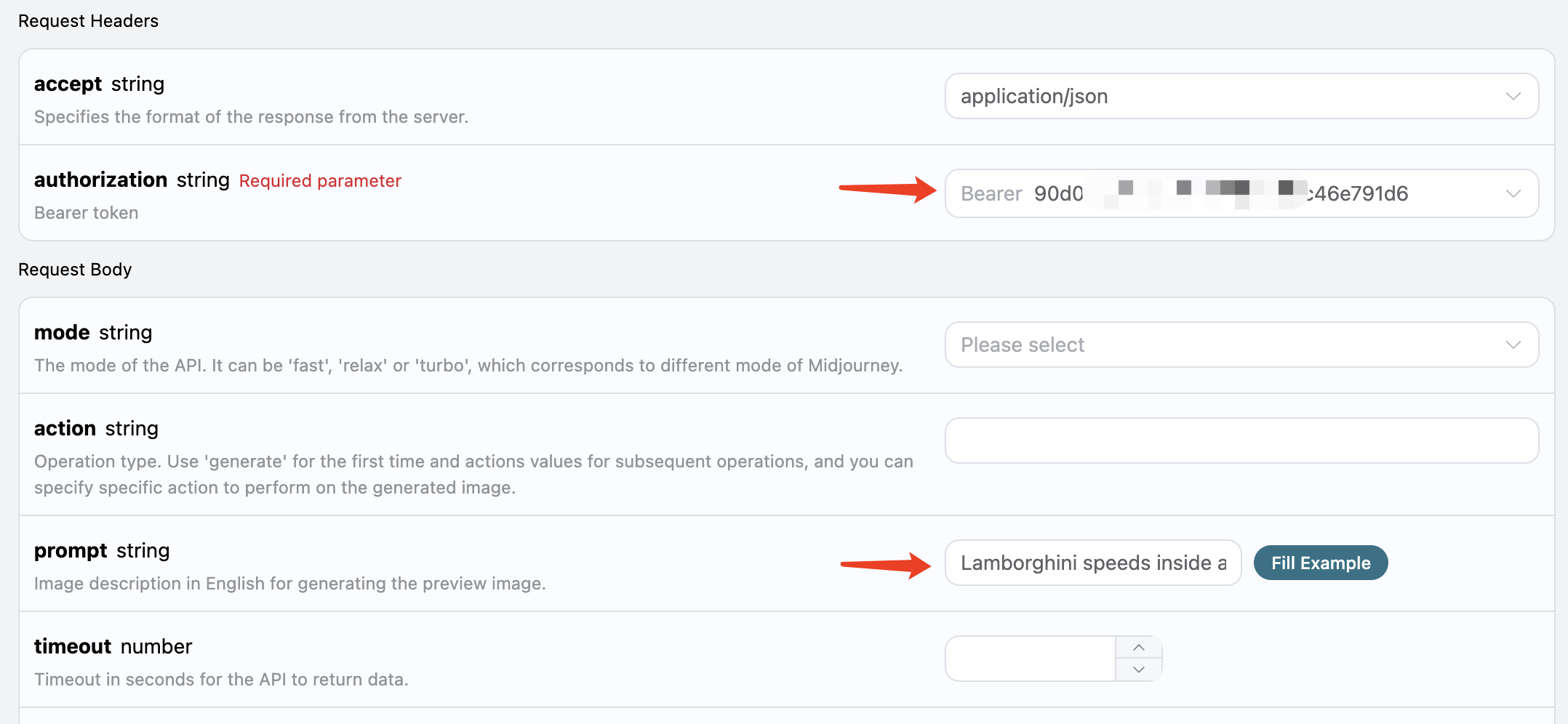 عند استخدام هذه الواجهة لأول مرة، نحتاج على الأقل إلى ملء محتويين، أحدهما هو
عند استخدام هذه الواجهة لأول مرة، نحتاج على الأقل إلى ملء محتويين، أحدهما هو authorization، والذي يمكن اختياره مباشرة من القائمة المنسدلة. المعامل الآخر هو prompt، حيث أن prompt هو وصف الصورة التي نريد توليدها، يُنصح باستخدام وصف باللغة الإنجليزية، حيث ستكون الصورة الناتجة أكثر دقة. هنا استخدمنا محتوى مثال هو Lamborghini speeds inside a volcano، والذي يمثل أننا نريد رسم لامبورغيني تتسابق داخل بركان.
يمكنك أيضًا ملاحظة وجود كود استدعاء مطابق على الجانب الأيمن، يمكنك نسخه وتشغيله مباشرة، أو يمكنك النقر على زر “Try” للاختبار.
المعلمات الرئيسية المطلوبة:
prompt: وصف الصورة (يدعم الترجمة التلقائية).mode: وضع التوليد، يمكن أن يكونfast/relax/turbo، الافتراضي هو fast.timeout: وقت المهلة (بالثواني)، سيتم إرجاع النتيجة مباشرة عند انتهاء المهلة.translation: ما إذا كان يجب ترجمةpromptغير الإنجليزية تلقائيًا.split_images: ما إذا كان يجب تقسيم نتائج 2x2 وإرجاع صورة واحدة.action/image_id: يجب تحديدها عند إجراء عمليات على الصور التاريخية.callback_url: عنوان رد الاتصال غير المتزامن.

task_id: معرف المهمة الخاصة بتوليد هذه الصورة، يستخدم لتحديد مهمة توليد الصورة هذه بشكل فريد.image_id: المعرف الفريد للصورة، يجب تمرير هذه المعلمة عند الحاجة إلى إجراء تغييرات على الصورة في المرة القادمة.image_url: عنوان URL للصورة المصغرة، يمكن فتحه مباشرة لمشاهدة التأثير الناتج.image_width: عرض الصورة المصغرة بالبكسل.image_height: ارتفاع الصورة المصغرة بالبكسل.raw_image_url: عنوان URL للصورة الأصلية، ومحتواها مشابه لمحتوى الصورة المصغرة، ولكنها بدقة أعلى، وقد تكون أبطأ في التحميل.raw_image_width: عرض الصورة الأصلية بالبكسل.raw_image_height: ارتفاع الصورة الأصلية بالبكسل.actions: قائمة العمليات الإضافية الممكنة على الصورة المولدة. هنا تم إدراج 8 عمليات، حيث يمثلupscaleالتكبير، ويمثلvariationالتغيير. لذا، فإنupscale1تعني إجراء عملية تكبير على الصورة الأولى في الزاوية اليسرى العليا، وvariation3تعني إجراء تغيير بناءً على الصورة الثالثة في الزاوية اليسرى السفلية.
image_url أو raw_image_url، يمكن ملاحظة ما هو موضح في الصورة.
 يمكنك رؤية أنه تم توليد صورة معاينة 2x2. حتى الآن، تم الانتهاء من أول استدعاء للواجهة.
يمكنك رؤية أنه تم توليد صورة معاينة 2x2. حتى الآن، تم الانتهاء من أول استدعاء للواجهة.
图像放大与变换
الآن، سنحاول إجراء عمليات إضافية على الصورة المولدة الحالية، على سبيل المثال، إذا كنا نعتقد أن الصورة الثانية في الزاوية اليمنى العليا جيدة، ولكننا نريد إجراء بعض التعديلات، يمكننا ملءaction كـ variation2، مع تمرير image_id:
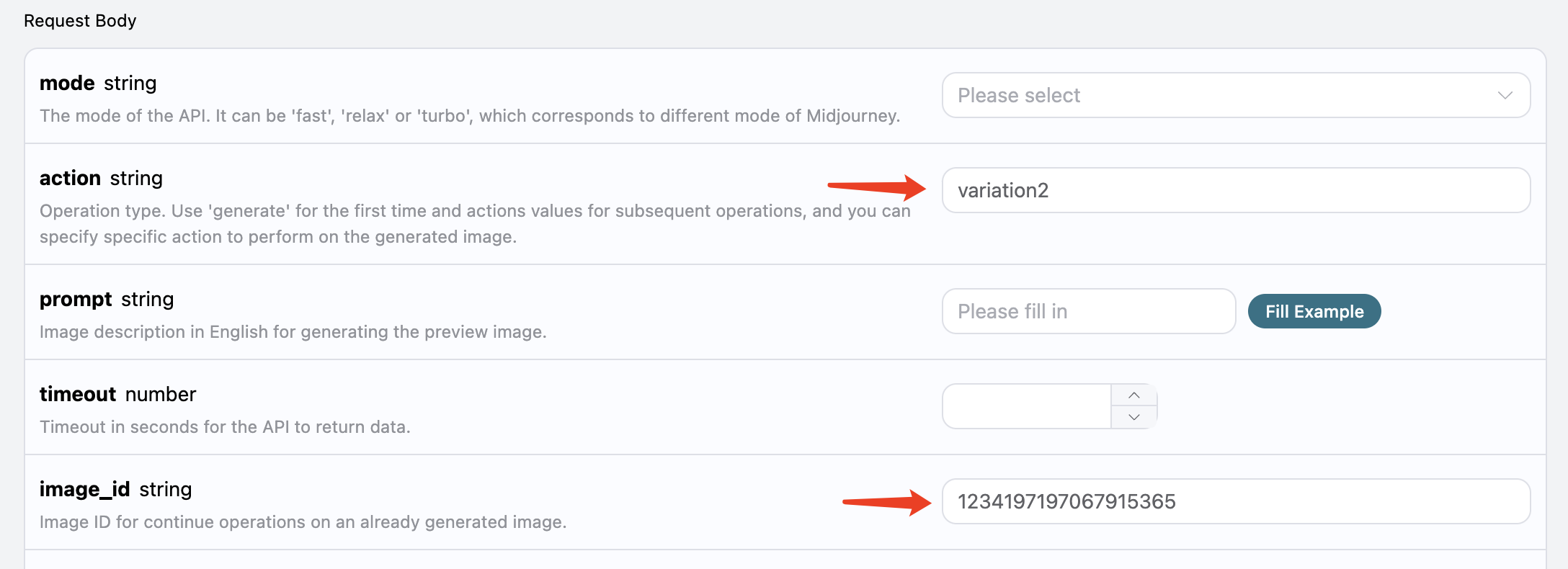 ستكون النتيجة كما يلي:
ستكون النتيجة كما يلي:
image_url، الصورة التي تم إنشاؤها جديدة كما هو موضح أدناه:
 يمكننا أن نرى أنه بالنسبة للصورة السابقة في الزاوية اليمنى العليا، حصلنا مرة أخرى على أربع صور مشابهة.
في هذه المرحلة، يمكننا اختيار واحدة منها لإجراء عملية تكبير دقيقة، على سبيل المثال، إذا اخترنا الصورة الرابعة، يمكننا تمرير
يمكننا أن نرى أنه بالنسبة للصورة السابقة في الزاوية اليمنى العليا، حصلنا مرة أخرى على أربع صور مشابهة.
في هذه المرحلة، يمكننا اختيار واحدة منها لإجراء عملية تكبير دقيقة، على سبيل المثال، إذا اخترنا الصورة الرابعة، يمكننا تمرير action كـ upscale4، ومن ثم تمرير معرف الصورة الحالي مرة أخرى باستخدام image_id.

ملاحظة: عمليةنتيجة العودة كما يلي:upscaleتستغرق وقتًا أقل مقارنةً بـvariationفي Midjourney.
image_url كما هو موضح في الصورة:
 وبذلك حصلنا بنجاح على صورة لسيارة لامبورغيني.
كما نلاحظ أن
وبذلك حصلنا بنجاح على صورة لسيارة لامبورغيني.
كما نلاحظ أن actions تحتوي على عدة عمليات يمكن تنفيذها، كما هو موضح أدناه:
upscale_2x: تكبير الصورة بمقدار 2x، للحصول على صورة عالية الدقة بمقدار 2x.upscale_4x: تكبير الصورة بمقدار 4x، للحصول على صورة عالية الدقة بمقدار 4x.zoom_out_2x: إجراء عملية تصغير للصورة بمقدار 2x (ملء المنطقة المحيطة).zoom_out_1_5x: إجراء عملية تصغير للصورة بمقدار 1.5x (ملء المنطقة المحيطة).pan_left: إجراء عملية إزاحة للصورة إلى اليسار.pan_right: إجراء عملية إزاحة للصورة إلى اليمين.pan_up: إجراء عملية إزاحة للصورة إلى الأعلى.pan_down: إجراء عملية إزاحة للصورة إلى الأسفل.
إعادة كتابة الصورة (تحت الصورة)
تدعم هذه الواجهة البرمجية أيضًا إعادة كتابة الصورة، والمعروفة باسم تحت الصورة، يمكننا إدخال رابط صورة بالإضافة إلى وصف النص الذي نحتاج إلى إعادة كتابته، وستقوم هذه الواجهة البرمجية بإرجاع الصورة المعدلة.ملاحظة: يجب أن يكون رابط الصورة المدخل صورة نقية، ولا يمكن أن يكون صفحة تحتوي على صورة، وإلا فلن تتمكن من إجراء إعادة كتابة الصورة. يُنصح باستخدام مواقع رفع الصور للحصول على رابط الصورة.على سبيل المثال، لدينا هنا صورة لغروب الشمس على الطريق، بجانب الطريق بعض الأشجار والمباني، كما هو موضح في الصورة:
 الآن نريد أن نعيد كتابتها لتصبح بجانب الشاطئ، مع وجود سيارة متوقفة على جانب الطريق. يمكننا بناء
الآن نريد أن نعيد كتابتها لتصبح بجانب الشاطئ، مع وجود سيارة متوقفة على جانب الطريق. يمكننا بناء prompt كما يلي:
prompt لدينا هي رابط صورة يبدأ بـ HTTPS، ثم نضيف مسافة، تليها محتوى نص prompt. هنا استخدمنا أيضًا بعض المعلمات المتقدمة الإضافية، مثل —iw 2 لضبط وزن الصورة.
يمكننا تمرير المحتوى أعلاه ككل إلى حقل prompt، كما هو موضح في الصورة:
 نتيجة الإخراج كما يلي:
نتيجة الإخراج كما يلي:
 يمكننا أن نرى أنه، مع الحفاظ على الأسلوب العام والتكوين للصورة الأصلية، أصبح المشهد بأكمله بجانب الشاطئ، بينما ظهرت سيارة على الطريق، وهذا هو Prompt with Image.
يمكننا أن نرى أنه، مع الحفاظ على الأسلوب العام والتكوين للصورة الأصلية، أصبح المشهد بأكمله بجانب الشاطئ، بينما ظهرت سيارة على الطريق، وهذا هو Prompt with Image.
دمج الصور
تدعم هذه الواجهة البرمجية أيضًا دمج الصور، حيث يمكننا تمرير عدة صور لتحقيق تأثيرات دمج مختلفة. على سبيل المثال، لدينا هنا صورتان، واحدة لدب لعبة، والأخرى لمنشار كهربائي، كما هو موضح في الصور التالية:

prompt، والنتيجة كما يلي:
 يمكننا أن نرى أننا نجحنا في تحقيق دمج الصور.
يمكننا أن نرى أننا نجحنا في تحقيق دمج الصور.
ملاحظة: يدعم دمج الصور بحد أقصى 5 روابط صور كمدخلات، أي أنه يدعم دمج 5 صور كحد أقصى، وصيغة الإدخال كما هو موضح أعلاه.
التحويل الجزئي
تدعم هذه الواجهة البرمجية أيضًا وظيفة الرسم الجزئي للصور، ولكنها تدعم فقط الصور التي تم إنشاؤها في المحتوى السابق، حيث يمكننا تمرير معرف فريد لصورة تم إنشاؤها، ومعلمة سلوك إعادة الرسمaction، بالإضافة إلى قناع mask للمنطقة التي تحتاج إلى إعادة الرسم، لتحقيق إعادة الرسم في منطقة القناع تلك.
على سبيل المثال، لدينا هنا صورة تم إنشاؤها عن قطة:


ملاحظة: الكود Python أعلاه يصف عملية توليد القناع، إذا كنت ترغب في دمجه في منتجك، يرجى كتابة كود بلغة مناسبة بناءً على مبدأه.من خلال الكود أعلاه، حصلنا على القناع الذي يحتاج إلى إعادة الرسم
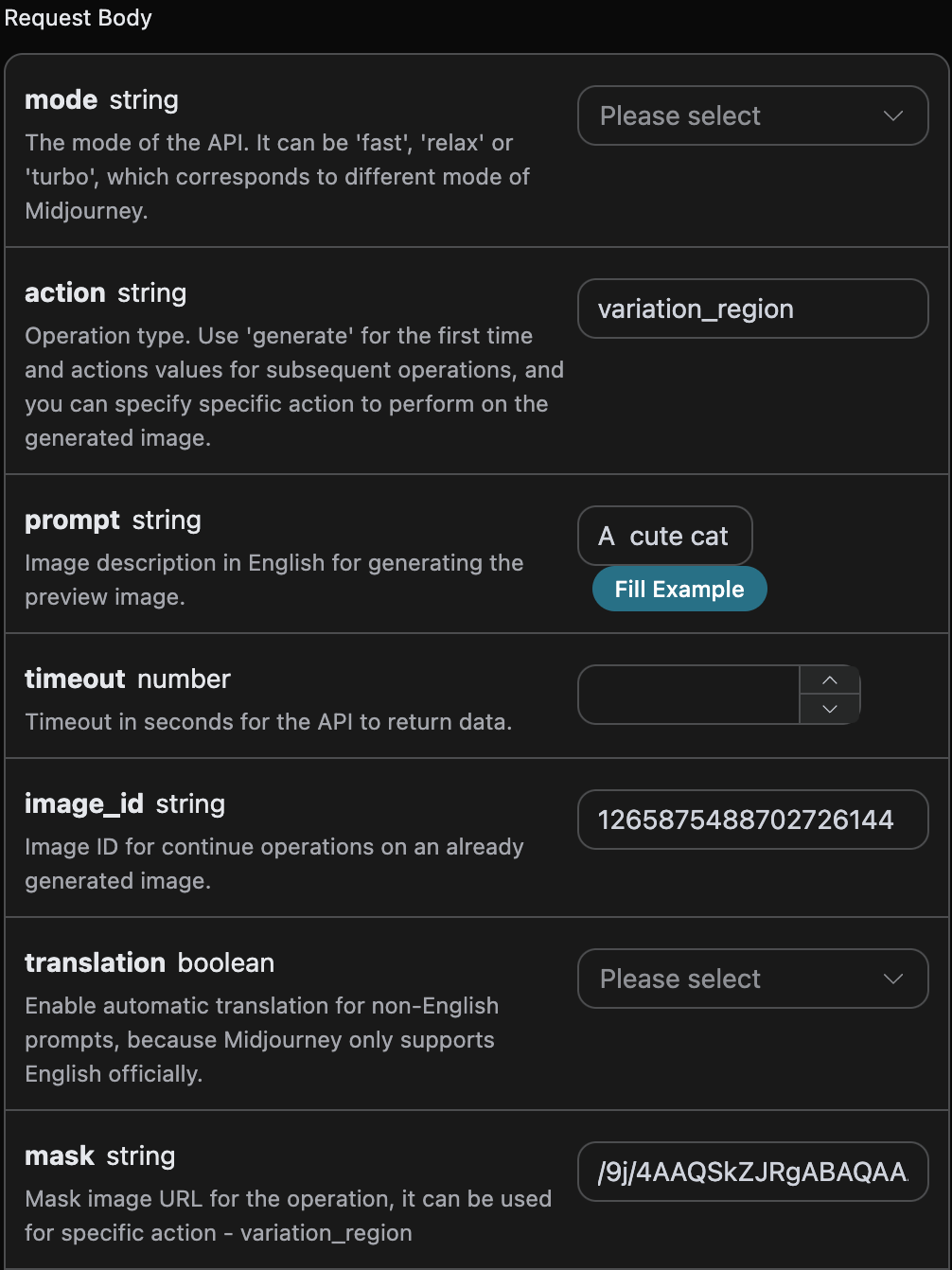
mask، أدناه نحتاج أيضًا إلى تعيين المعامل action إلى variation_region، وتوليد معرف الصورة image_id (للحصول على هذا المعامل، راجع المحتوى أعلاه)، بالإضافة إلى تمرير القناع المقابل mask، ومعلومات المعاملات الأخرى كما يلي:
action: سلوك إجراء العملية على الصورة، هنا هوvariation_region، مما يعني إعادة الرسم الجزئي للصورة.prompt: وصف إعادة الرسم الجزئي للصورة (معامل اختياري).image_id: المعرف الفريد للصورة، لتسهيل إعادة الرسم الجزئي للصورة.mask: ترميز base64 لمنطقة القناع المقابلة للصورة (الصورة هي التي حددهاimage_idأعلاه).
prompt هو معامل غير إلزامي، هنا لتسهيل المقارنة، تم تعيين منطقة القناع prompt إلى A cute cat، إعداد المعاملات كما هو موضح في الصورة أدناه:
مثال على الكود
يمكن ملاحظة أنه تم توليد كودات تلقائيًا بلغات مختلفة على الجانب الأيمن، كما هو موضح في الصورة:
مثال على الاستجابة
بعد نجاح الطلب، ستقوم واجهة برمجة التطبيقات بإرجاع معلومات نتيجة الصورة الخلفية بعد تغيير الوجه. على سبيل المثال: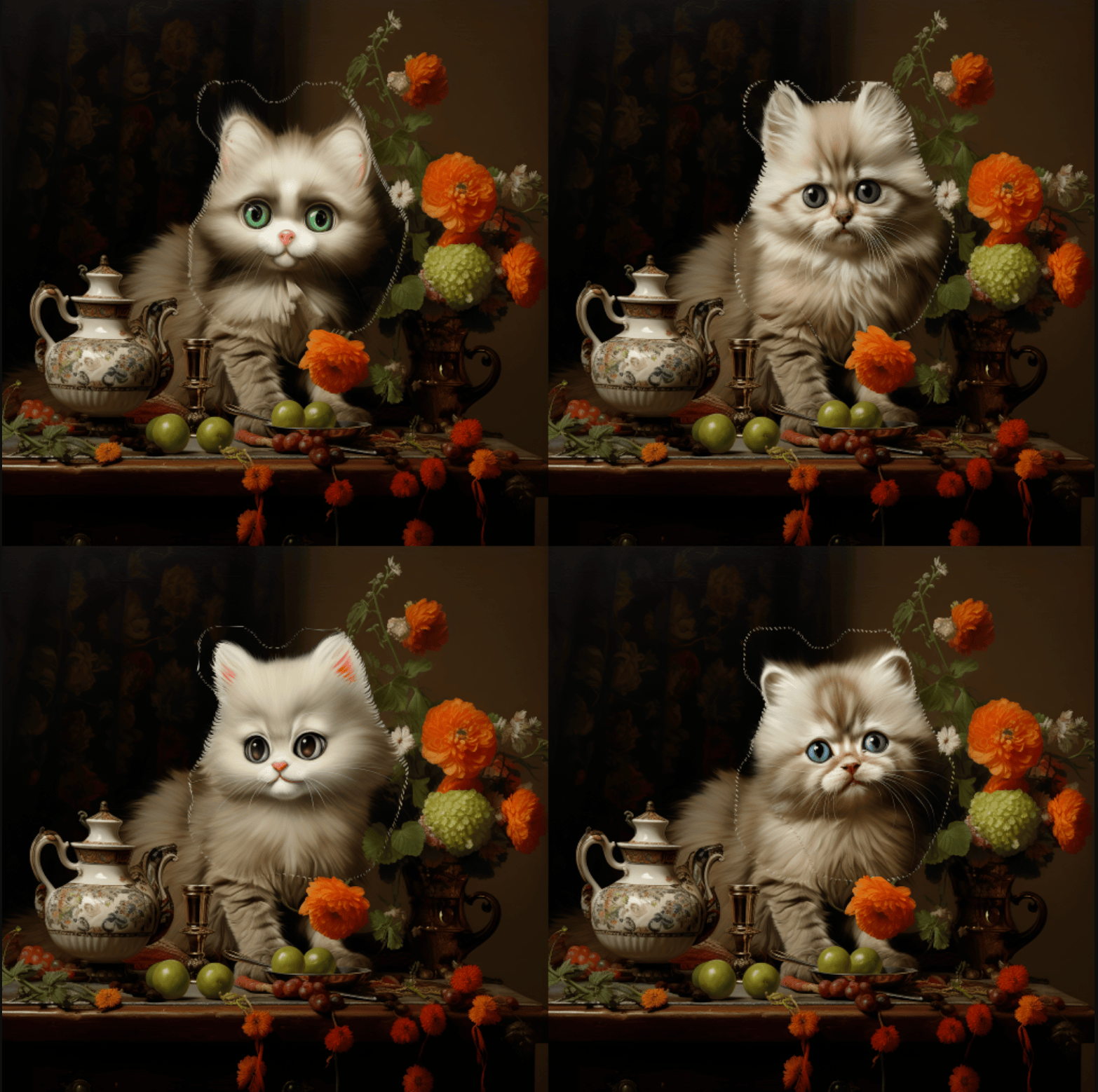 يمكننا أن نرى أننا نجحنا في تنفيذ إعادة الرسم الجزئي على المنطقة المخصصة للصورة الناتجة.
يمكننا أن نرى أننا نجحنا في تنفيذ إعادة الرسم الجزئي على المنطقة المخصصة للصورة الناتجة.
CURL
ردود غير متزامنة
نظرًا لأن Midjourney تحتاج إلى وقت لتوليد الصور، فقد تم تصميم هذه الواجهة البرمجية أيضًا لتكون في وضع الانتظار الطويل بشكل افتراضي. ولكن في بعض السيناريوهات، قد يؤدي الانتظار الطويل إلى بعض التكاليف الإضافية للموارد، لذلك توفر هذه الواجهة البرمجية أيضًا طريقة ردود غير متزامنة عبر Webhook، حيث يتم إرسال النتائج عبر طلب HTTP إلى عنوان URL المحدد لـ Webhook عند نجاح أو فشل توليد الصورة. بعد استلام عنوان URL لردود Webhook للنتائج، يمكن إجراء مزيد من المعالجة. فيما يلي توضيح لعملية الاستدعاء المحددة. أولاً، ردود Webhook هو خدمة يمكنها استقبال طلبات HTTP، يجب على المطورين استبدالها بعنوان URL الخاص بخادم HTTP الذي قاموا بإنشائه. هنا، لتسهيل العرض، نستخدم موقع Webhook عينة عام https://webhook.site/، بفتح هذا الموقع يمكنك الحصول على عنوان URL لـ Webhook، كما هو موضح في الصورة: قم بنسخ هذا العنوان URL، يمكنك استخدامه كـ Webhook، والعينة هنا هي https://webhook.site/995d0a91-d737-40a7-a3b9-5baf68ed924c.
بعد ذلك، يمكننا تعيين الحقل
قم بنسخ هذا العنوان URL، يمكنك استخدامه كـ Webhook، والعينة هنا هي https://webhook.site/995d0a91-d737-40a7-a3b9-5baf68ed924c.
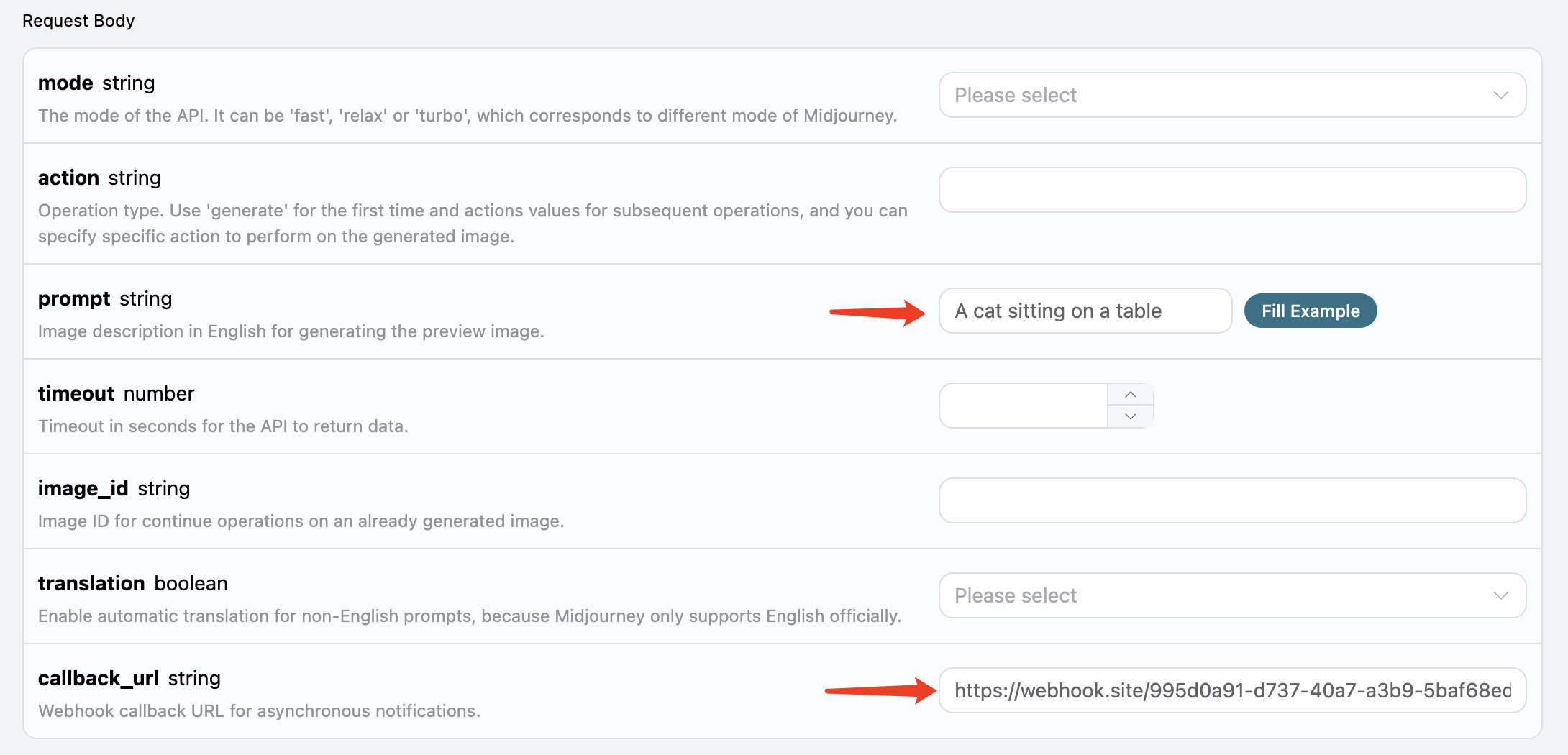
بعد ذلك، يمكننا تعيين الحقل callback_url إلى عنوان URL لـ Webhook المذكور أعلاه، مع ملء prompt، كما هو موضح في الصورة:
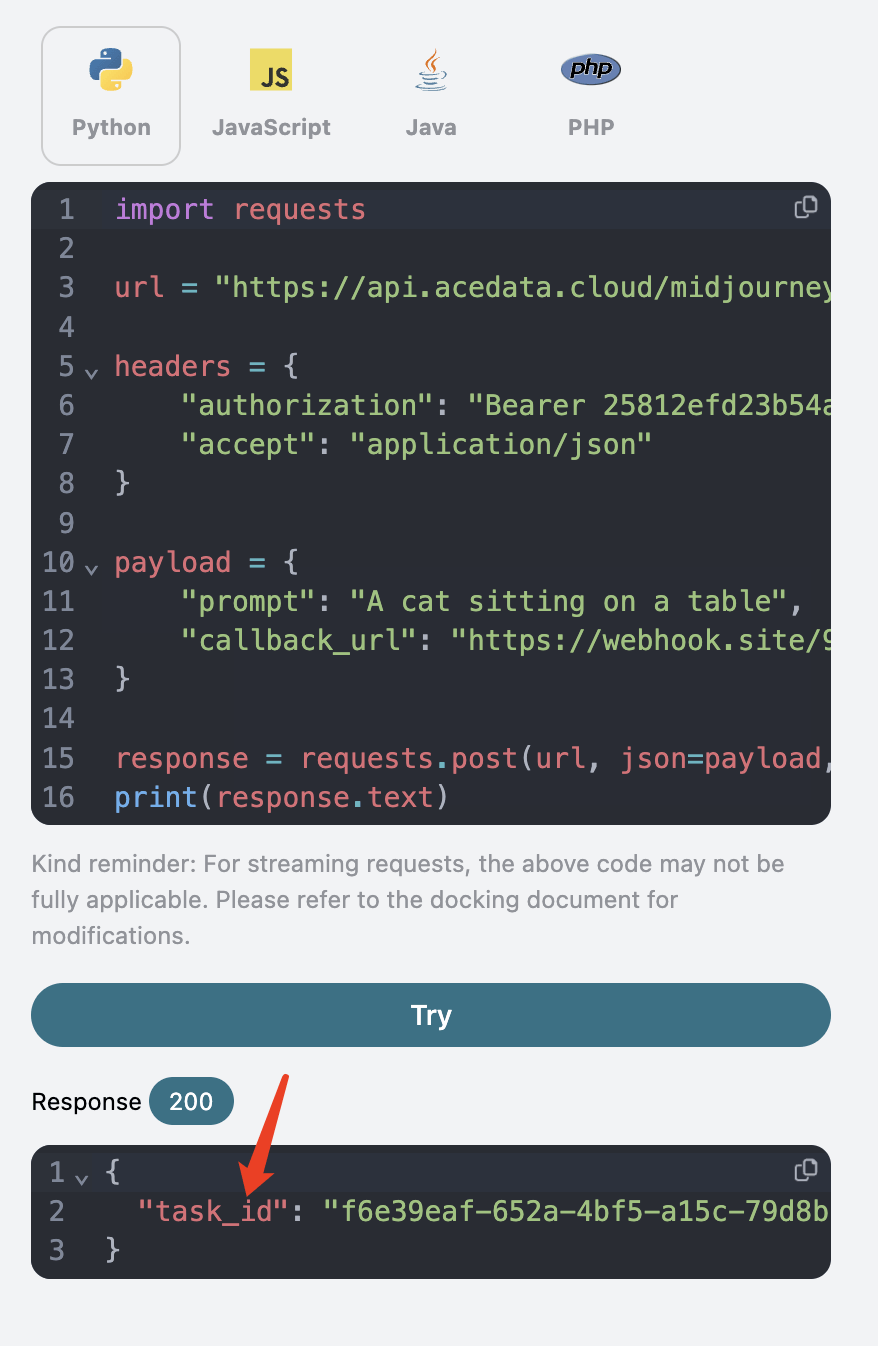
 بعد النقر على اختبار، ستحصل على استجابة فورية تحتوي على
بعد النقر على اختبار، ستحصل على استجابة فورية تحتوي على task_id، لتحديد معرف المهمة الحالية، كما هو موضح في الصورة:
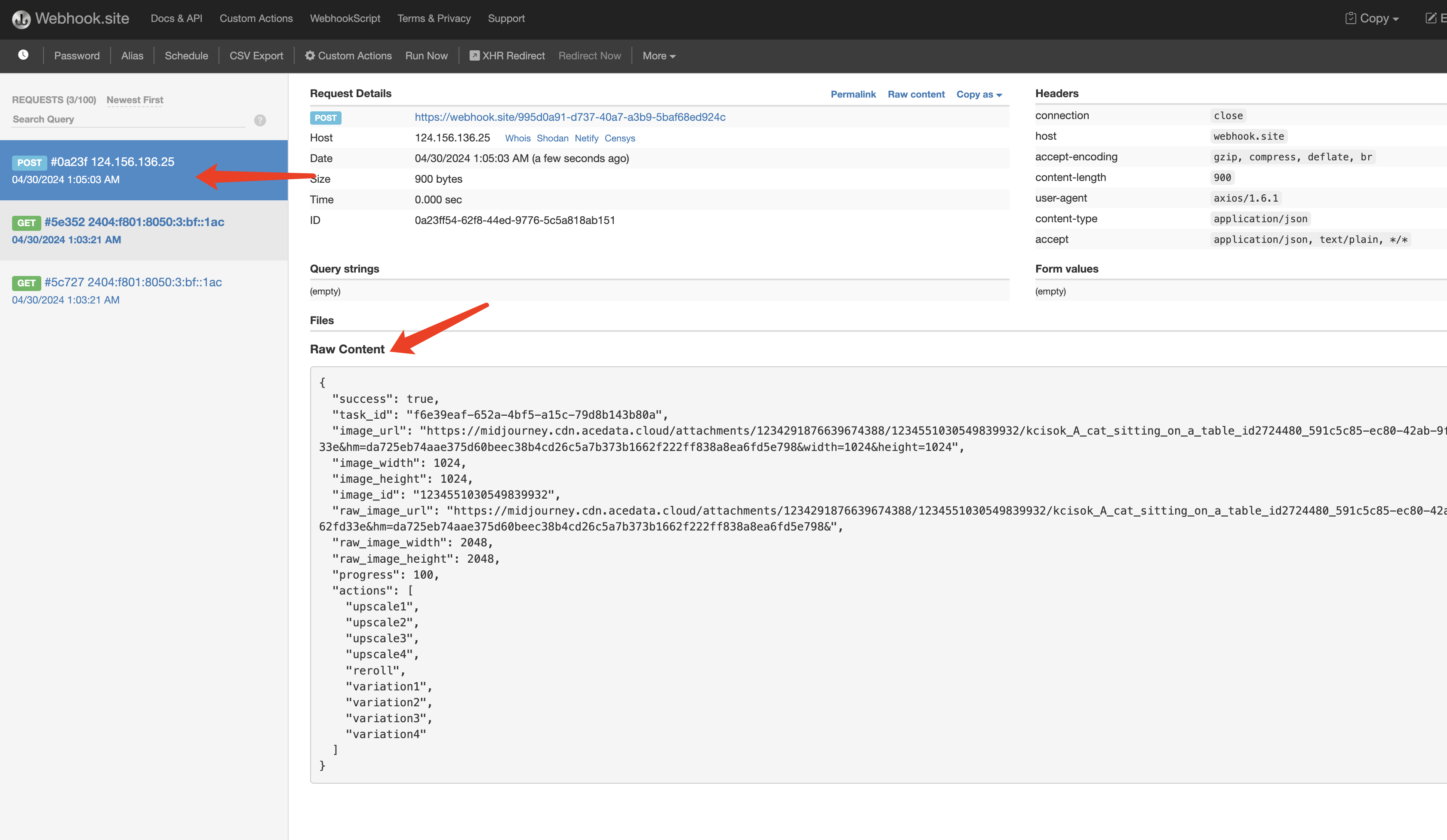 نتيجته هي نتيجة المهمة الحالية، المحتوى كما يلي:
نتيجته هي نتيجة المهمة الحالية، المحتوى كما يلي:
success إلى ما إذا كانت المهمة قد نفذت بنجاح، وإذا كانت ناجحة، فسيكون هناك أيضًا نفس الحقول actions و image_id و image_url، والتي تتطابق مع النتائج التي تم تقديمها سابقًا، بالإضافة إلى task_id لتحديد المهمة، لتحقيق ارتباط بين نتائج Webhook وطلب API الأصلي.
إذا فشلت توليد الصورة، فسيستقبل عنوان URL لـ Webhook محتوى مشابه لما يلي:
success هو false، وسيكون هناك أيضًا حقل error.code و error.message يصف تفاصيل خطأ المهمة، ويمكن لخادم Webhook معالجة النتائج وفقًا لذلك.
إخراج متدفق
تقوم Midjourney رسميًا بتوليد الصور مع تقدم، في البداية تكون الصورة ضبابية، ثم بعد عدة تكرارات، تصبح الصورة تدريجياً أكثر وضوحًا، وفي النهاية تحصل على الصورة الكاملة. لذا، يمكن تقسيم عملية توليد صورة واحدة تقريبًا إلى مراحل “إرسال الأمر” -> “بدء توليد الصورة (تكرارات متعددة تدريجياً تصبح أكثر وضوحًا)” -> “انتهاء توليد الصورة”. عند عدم تفعيل الإخراج المتدفق، فإن هذه الواجهة البرمجية من بدء الطلب إلى إرجاع النتيجة، في الواقع، تشمل العملية الكاملة من “إرسال الأمر” -> “انتهاء توليد الصورة”، حيث يتم تضمين عملية توليد الصورة بالكامل، ونظرًا لأن Midjourney نفسها تولد الصور ببطء، فإن العملية الكاملة تحتاج إلى الانتظار حوالي دقيقة أو أكثر. لذا، من أجل تحسين تجربة المستخدم، تدعم هذه الواجهة البرمجية الإخراج المتدفق، أي عند “بدء توليد الصورة” تبدأ في إرجاع النتائج، وعندما يتغير تقدم الرسم، سيتم إخراج النتائج بشكل متدفق حتى انتهاء توليد الصورة. إذا كنت ترغب في إرجاع استجابة متدفقة، يمكنك تغيير معلمةaccept في رأس الطلب إلى application/x-ndjson، ولكن يجب أن يتضمن كود الاستدعاء التغييرات المناسبة لدعم الاستجابة المتدفقة.
مثال على كود Python:
ملاحظة: عندما لا يكتمل التوليد، يكون حقل actions فارغًا، مما يعني أنه لا يمكن تنفيذ عمليات معالجة إضافية على الصورة الوسيطة. بعد اكتمال التوليد، سيتم تدمير image_url الذي تم إنشاؤه أثناء عملية التوليد.
بالإضافة إلى ذلك، يمكنك دمج نتائج الإخراج المتدفق مع ردود الفعل غير المتزامنة عن طريق تحديد رأس الطلب accept=application/x-ndjson وجسم الطلب callback_url، ثم يمكن أن يتلقى callback_url طلبات POST متعددة لنتائج الإخراج المتدفق.