data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"content": "", "role": "assistant"}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"reasoning_content": "**Defina Minha Natureza**\n\nMeu pensamento começou. O usuário quer saber minha natureza, perguntando diretamente \"o que você é?\" O primeiro passo foi simples: identificar a consulta. Agora, lembro da minha identidade fundamental: sou um grande modelo de linguagem. Esta é a verdade central que pretendo transmitir.\n\n\n"}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"reasoning_content": "**Aprimorando Minha Resposta**\n\nAdicionei a informação crucial de que fui treinado pelo Google à identidade básica de \"grande modelo de linguagem\". Meu próximo passo é considerar o que significa ser um \"grande modelo de linguagem\" na prática, para que eu possa explicar minhas capacidades principais. Estou focando em fornecer contexto sem entrar em detalhes técnicos específicos ou nomes de modelos. Quero transmitir minha função de uma maneira que o usuário possa entender facilmente.\n\n\n"}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"reasoning_content": "**Confirmando Identidade Central**\n\nAgora estou solidificando minha resposta. A consulta do usuário sobre minha afiliação de modelo precisa de uma resposta focada. Identifiquei que \"treinado pelo Google\" é essencial, fornecendo um contexto chave. Estou resistindo à tentação de mencionar nomes de modelos específicos, pois não é relevante. O objetivo é entregar uma declaração direta e precisa. Meu objetivo continua sendo uma resposta clara e concisa, evitando jargões técnicos e indo direto ao ponto relevante.\n\n\n"}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
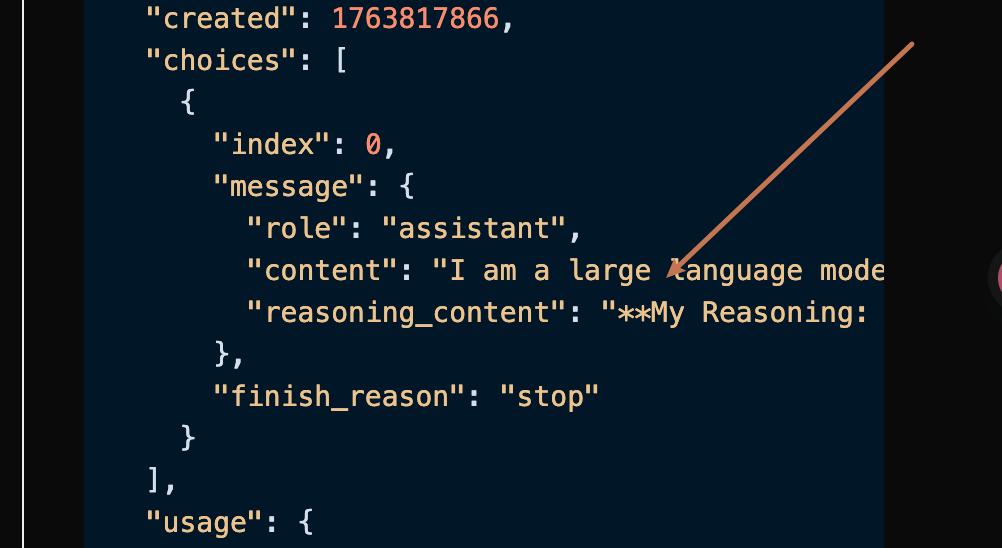
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {"content": "Eu sou um grande modelo de linguagem, treinado pelo Google."}, "logprobs": null, "finish_reason": null, "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": null, "choices": [{"delta": {}, "logprobs": null, "finish_reason": "stop", "index": 0}], "usage": null}
data: {"id": "chatcmpl-20251122214038810722821kNjUTjtr", "object": "chat.completion.chunk", "created": 1763818842, "model": "gemini-2.5-pro", "system_fingerprint": "", "choices": [], "usage": {"prompt_tokens": 8, "completion_tokens": 527, "total_tokens": 535, "prompt_tokens_details": {"cached_tokens": 0, "text_tokens": 8, "audio_tokens": 0, "image_tokens": 0}, "completion_tokens_details": {"text_tokens": 0, "audio_tokens": 0, "reasoning_tokens": 519}, "input_tokens": 0, "output_tokens": 0, "input_tokens_details": null, "claude_cache_creation_5_m_tokens": 0, "claude_cache_creation_1_h_tokens": 0}}
data: [DONE]
 Se você ainda não estiver logado ou registrado, será redirecionado automaticamente para a página de login, convidando-o a se registrar e fazer login. Após o registro e login, você será automaticamente retornado à página atual.
Na primeira solicitação, haverá um crédito gratuito disponível, permitindo o uso gratuito dessa API.
Se você ainda não estiver logado ou registrado, será redirecionado automaticamente para a página de login, convidando-o a se registrar e fazer login. Após o registro e login, você será automaticamente retornado à página atual.
Na primeira solicitação, haverá um crédito gratuito disponível, permitindo o uso gratuito dessa API.